Discover and read the best of Twitter Threads about #Julia言語
Most recents (24)

#統計
正確な説明にこだわっているようなのであえてコメント。
線形回帰でこだわるべき条件は「残差が正規分布」よりも「残差が独立同分布」の方です。
残差が非正規分布のi.i.d.のときの線形回帰は、非正規母集団のt検定と同じようにうまく行ったり、行かなかったりします。詳しい解説に続く。
正確な説明にこだわっているようなのであえてコメント。
線形回帰でこだわるべき条件は「残差が正規分布」よりも「残差が独立同分布」の方です。
残差が非正規分布のi.i.d.のときの線形回帰は、非正規母集団のt検定と同じようにうまく行ったり、行かなかったりします。詳しい解説に続く。
#統計 例で説明します。
まず、残差がi.i.d.ではないが、残差全体は正規分布に従う場合があることの説明。
添付画像がそのような場合の例になっています。
データの散布図(青点達)を見ると、この場合には単純な線形回帰の適用が不適切であることは明らか。続き#
nbviewer.org/github/genkuro…
まず、残差がi.i.d.ではないが、残差全体は正規分布に従う場合があることの説明。
添付画像がそのような場合の例になっています。
データの散布図(青点達)を見ると、この場合には単純な線形回帰の適用が不適切であることは明らか。続き#
nbviewer.org/github/genkuro…

#統計 この例は回帰直線を2本にする必要があります。
1本の回帰直線に関する残差の値全体の分布は正規分布になります。
添付画像①から残差の分布がxへの依存性が分かる。
添付画像②はxを無視すると残差全体は正規分布になることの確認。(理論的にそうなることも確認済み)
続く
1本の回帰直線に関する残差の値全体の分布は正規分布になります。
添付画像①から残差の分布がxへの依存性が分かる。
添付画像②はxを無視すると残差全体は正規分布になることの確認。(理論的にそうなることも確認済み)
続く


#統計 「全部pだと困る問題」について。個人のノートでは
p₁(y|x,c)p₂(x|c)p₃(c)p₁(yₐ|a,c)
の代わりに、
p(y|x,c)p(x|c)p(c)p(y=yₐ|x=a,c)
と書くことにしている。引数名を固定して、引数xにaを代入する場合には引数をx=aと書くという方針。
#Julia言語 のp(; y, x, c)と同じ仕様を採用😊
p₁(y|x,c)p₂(x|c)p₃(c)p₁(yₐ|a,c)
の代わりに、
p(y|x,c)p(x|c)p(c)p(y=yₐ|x=a,c)
と書くことにしている。引数名を固定して、引数xにaを代入する場合には引数をx=aと書くという方針。
#Julia言語 のp(; y, x, c)と同じ仕様を採用😊
#Julia言語 での p(; x=y, μ=0, σ) のような書き方はこんな感じ。
using Distributions
p(; x, μ, σ) = pdf(Normal(μ, σ), x)
y = 1.96
σ = 1
p(; x=y, μ=0, σ)
using Distributions
p(; x, μ, σ) = pdf(Normal(μ, σ), x)
y = 1.96
σ = 1
p(; x=y, μ=0, σ)

プログラミング言語の仕様になっている書き方であれば、well-definedな表記法であることが保証されていると考えてよい。
#Julia言語 との類似は、変数名が違えば型も違うことにすると、同一の名前の函数(メソッド)の多重ディスパッチの仕組みによって、より完璧になる。
#Julia言語 との類似は、変数名が違えば型も違うことにすると、同一の名前の函数(メソッド)の多重ディスパッチの仕組みによって、より完璧になる。
#Julia言語 以下のリンク先と同じことをやってみたい人のための解説
①まず、 julialang.org/downloads/ からCurrent stable releaseで自分のパソコンに合っているものをダウンロードし、自分のパソコンにインストールする。
②インストールしたJuliaを起動する。
添付画像はnightly build。続く
①まず、 julialang.org/downloads/ からCurrent stable releaseで自分のパソコンに合っているものをダウンロードし、自分のパソコンにインストールする。
②インストールしたJuliaを起動する。
添付画像はnightly build。続く

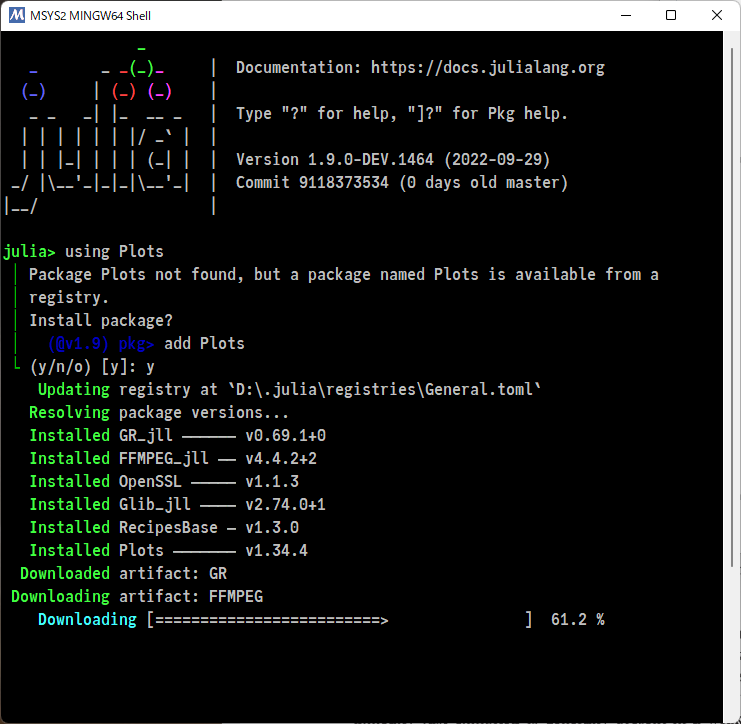
#Julia言語
③添付画像1のように julia> プロンプトに
using Plots
と入力してエンターキーを押します。
そして添付画像2のように y と入力しエンターキーを押します。
すると添付画像3,4のようにPlots.jlパッケージがインストールされます。
③添付画像1のように julia> プロンプトに
using Plots
と入力してエンターキーを押します。
そして添付画像2のように y と入力しエンターキーを押します。
すると添付画像3,4のようにPlots.jlパッケージがインストールされます。



#Julia言語
④ github.com/genkuroki/publ… にアクセスし、そこの In[1] のusing Plots以外の部分を、julia> プロンプトの側にコピー&ペーストして下さい。
そして、最終行の確定のためにエンターキーも押しておく。
そしてしばらく待ちます。
④ github.com/genkuroki/publ… にアクセスし、そこの In[1] のusing Plots以外の部分を、julia> プロンプトの側にコピー&ペーストして下さい。
そして、最終行の確定のためにエンターキーも押しておく。
そしてしばらく待ちます。



#統計 以下のリンク先で引用されている jakevdp.github.io/blog/2014/06/1… のExample 2: Jaynes' Truncated Exponential の内容がひどかったので、Jaynes(1976) bayes.wustl.edu/etj/articles/c… の関連箇所を見たらもっとひどかったので、ひどさが分かるようにノートを作りました。
↓
github.com/genkuroki/publ…
↓
github.com/genkuroki/publ…
#統計 Jaynes(1976) bayes.wustl.edu/etj/articles/c… (doi.org/10.1007/978-94…)のpp.196-198がびっくりするぐらい酷い。
__不適切な__信頼区間の構成法と平坦事前分布のベイズ信用区間を比較して、信頼区間を強くdisり、さらにp.198辺りでそのことについて講演したときの様子を偉そうに説明している。
__不適切な__信頼区間の構成法と平坦事前分布のベイズ信用区間を比較して、信頼区間を強くdisり、さらにp.198辺りでそのことについて講演したときの様子を偉そうに説明している。



#統計 統計学の内容以前に人間性が疑わしく思えて来そうなほど偉そうに書いている。
私には、単にJaynesさんは切断指数分布モデル(truncated exponential distribution model)の場合に、適切な信頼区間の構成法を見付けることができなかっただけに見えました。
↓
github.com/genkuroki/publ…
私には、単にJaynesさんは切断指数分布モデル(truncated exponential distribution model)の場合に、適切な信頼区間の構成法を見付けることができなかっただけに見えました。
↓
github.com/genkuroki/publ…
#統計 いやあ、これにはマジでびっくりした。😱
ベイズ版95%信用区間(確信区間)がゼロをまたがなくなるまでNを増やす行為は、P値が5%を切るまでNを増やすp-hacking行為と(小さな誤差を除けば)数学的に同等です。
P値が5%を切るまでNを増やすp-hacking行為の是非も規範の問題で済ませられる?
ベイズ版95%信用区間(確信区間)がゼロをまたがなくなるまでNを増やす行為は、P値が5%を切るまでNを増やすp-hacking行為と(小さな誤差を除けば)数学的に同等です。
P値が5%を切るまでNを増やすp-hacking行為の是非も規範の問題で済ませられる?
#統計 2020年3月に出版された豊田秀樹さんの本には、ベイズ統計では【データを取り増しても】よいし【事前登録~も必要ありません】と言っています。(他にも色々!)
これを「ベイズ統計を使えば研究不正扱いされていたことを堂々とできるようになる」と解釈する人達が出ることを危惧していました。
これを「ベイズ統計を使えば研究不正扱いされていたことを堂々とできるようになる」と解釈する人達が出ることを危惧していました。

#統計 より正確に言えば、同様の言説を他で見た人達が、「ベイズ統計を使えば研究不正扱いされていたことを堂々とできるようになる」と既に信じている場合もあるのではないかと思いました。
これ、めちゃくちゃまずくないですか?
これ、めちゃくちゃまずくないですか?
#Julia言語 いきなり、struct ~ end の中で(内部)コンストラクタをnewを使って定義するのは避けた方が無難。new無しにはできないことをやりたくなったら、初めてそうするのがよいです。
公式ドキュメントにも可能な限り内部コンストラクタは避けよと書いてあります。
docs.julialang.org/en/v1/manual/c…
公式ドキュメントにも可能な限り内部コンストラクタは避けよと書いてあります。
docs.julialang.org/en/v1/manual/c…

#Julia言語 内部コンストラクタを定義せずに、例えば、
struct Foo{A, B}
a::A
b::B
end
と書けば、Foo型オブジェクトのコンストラクタたち
Foo(a::A, b::B) where {A, B}
Foo{A, B}(a, b) where {A, B}
が自動的に定義されます。
ひとまずはコンストラクタとしてこれらを使えば大丈夫。
struct Foo{A, B}
a::A
b::B
end
と書けば、Foo型オブジェクトのコンストラクタたち
Foo(a::A, b::B) where {A, B}
Foo{A, B}(a, b) where {A, B}
が自動的に定義されます。
ひとまずはコンストラクタとしてこれらを使えば大丈夫。
#Julia言語 クラスがあるプログラミング言語から来た人は、struct ~ end の内側でコンストラクタを定義した方が良いと誤解しがちだと思う。
Juliaでは、クラスベースのOOPを廃して、パラメータ付きの型による多重ディスパッチでエコシステム全体を構築した方が効率的だという話になっている感じ。
Juliaでは、クラスベースのOOPを廃して、パラメータ付きの型による多重ディスパッチでエコシステム全体を構築した方が効率的だという話になっている感じ。
対数尤度を「浮動小数点数で尤度を計算してからlogをとる」で計算するとマイナス無限大になりがち。
尤度を浮動小数点数で計算するとぴったり0.0になりがち。
他にもマイナス無限大が得られるパターンが結構あると思う。
尤度を浮動小数点数で計算するとぴったり0.0になりがち。
他にもマイナス無限大が得られるパターンが結構あると思う。
確率がらみの数値計算では、対数尤度は「尤度の対数」で計算しちゃだめで、対数尤度を直接計算するコードを書く必要がある。
例えばgamma(x)やbeta(a, b)の類は使っちゃダメで、loggamma(x)やlogbeta(a, b)を使う。
混合正規分布を使っている場合にはlogsumexp的な工夫が必要になる。
例えばgamma(x)やbeta(a, b)の類は使っちゃダメで、loggamma(x)やlogbeta(a, b)を使う。
混合正規分布を使っている場合にはlogsumexp的な工夫が必要になる。
確率密度の値は浮動小数点数では容易に0.0やInfになるので、確率密度を扱うパッケージには、確率密度の値の対数を直接扱う機能が必ず付いているはず。
私はほんの一部の狭い分野を除くあらゆる分野のど素人なので、この手のことも知らずに、結構酷いコードを書いていたことがある。
私はほんの一部の狭い分野を除くあらゆる分野のど素人なので、この手のことも知らずに、結構酷いコードを書いていたことがある。
#統計 確率密度函数 p(x) = exp(-φ(x))/Z における ∫p(x)dx=1 にするための規格化定数 Z が不明の状況で、分布p(x)のサンプル(i.i.d.な乱数列)を数値的に得たい場合は多い。
函数φ(x)の情報だけから分布p(x)∝exp(-φ(x))の乱数列を作りたい。
MCMC法はそのための方法の1つ。
函数φ(x)の情報だけから分布p(x)∝exp(-φ(x))の乱数列を作りたい。
MCMC法はそのための方法の1つ。
#統計 MCMC法に分類される乱数列の生成法は色々ある。
HMC法ではφ(x)のgradientの情報が必要になる。
φ(x)が与えられれば、自動的にそのgradientも計算できるようにしてくれる自動微分は実際に使ってみると確かに非常に便利です。
HMC法ではφ(x)のgradientの情報が必要になる。
φ(x)が与えられれば、自動的にそのgradientも計算できるようにしてくれる自動微分は実際に使ってみると確かに非常に便利です。
#統計 「自動微分とは逆伝搬法のことだ」と誤解しているように見える発言を見たことがあるが、逆伝搬法は自動微分の手続きをある種の状況で高速化するための手法の1つに過ぎない。
行列A,B,C,DについてA(B(CD))と((AB)C)Dでは行列のサイズによって計算効率が大きく違う場合がある。更なる一般化あり。
行列A,B,C,DについてA(B(CD))と((AB)C)Dでは行列のサイズによって計算効率が大きく違う場合がある。更なる一般化あり。
#統計 せっかく作ったので教育用のノートブックを放流
#Julia言語
nbviewer.org/github/genkuro…
二項分布のある種の極限でPoisson分布が得られる(添付画像③④)のと同じように、負の二項分布のある種の極限でガンマ分布が得られる(添付画像①②)。
#Julia言語
nbviewer.org/github/genkuro…
二項分布のある種の極限でPoisson分布が得られる(添付画像③④)のと同じように、負の二項分布のある種の極限でガンマ分布が得られる(添付画像①②)。




#統計 r=3, p=1/(5N)の負の二項分布を1/N倍でスケールして得られる分布のcdfはN=100でα=3, θ=5 のガンマ分布のcdfにほぼぴったり一致している。
離散分布と連続分布の比較は累積確率分布函数(cdf)のプロットで比較すると楽です。
#Julia言語
nbviewer.org/github/genkuro…
離散分布と連続分布の比較は累積確率分布函数(cdf)のプロットで比較すると楽です。
#Julia言語
nbviewer.org/github/genkuro…

#統計 この極限はそれぞれの分布の意味が分かっていれば「当然そうなる」と思える類のものです。
minimal working examples抜きには曖昧過ぎて微妙に危険な感じ。よい推定、よい予測、よい意思決定の中身が不明過ぎる。
特に「意思決定」という言葉が「推定」や「予測」など任意の行動を決める意味が広い用語になっているせいで、「本当はよい意思決定を目指すべきだ」と誤解する危険性がある。続く
特に「意思決定」という言葉が「推定」や「予測」など任意の行動を決める意味が広い用語になっているせいで、「本当はよい意思決定を目指すべきだ」と誤解する危険性がある。続く
教科書によく書いてある意思決定論では、パラメータ付きのモデル(推定推測推論用のモデル、以下単にモデルという)の内部で「最悪の場合の最善手」(ミニマックス)や「期待リスク最小化」(事前分布を主観確率と解釈すれば主観内で計算した期待リスク最小化)を考えます。
続く。リスクの定義を決める損失函数として「推定の悪さ」「予測の悪さ」の指標にすれば「モデル内でのよい推定」「モデル内でのよい予測」が得られ、仮に「金銭的な損失」の指標にできれば「モデル内での金銭的に最適な意思決定」が得られます。
そういう話は確かに結構面白いです。続く
そういう話は確かに結構面白いです。続く
以前書いた #Julia言語 版HMC(Hamiltonian Monte Carlo)のサンプルコード
ポテンシャル函数φ(x)から、確率分布p(x)=exp(-φ(x))/Zのi.i.d.サンプルを生成する方法の1つ。
60行程度しかない。
ポテンシャル函数φ(x)から、確率分布p(x)=exp(-φ(x))/Zのi.i.d.サンプルを生成する方法の1つ。
60行程度しかない。

#Julia言語 leapfrog法でHamiltonの正準方程式を解くので、leapfrog法のために必要な情報をLFProblem型の変数に格納し、それをHMC函数に渡すと分布p(x)=exp(-φ(x))/Zのサンプルを返してくれる。
そういうシンプルなコードになっています。
nbviewer.org/github/genkuro…
そういうシンプルなコードになっています。
nbviewer.org/github/genkuro…

#Julia言語 この手の問題では、ポテンシャル函数φ(x)がパラメータに依存している場合が多いので、ポテンシャル函数はφ(x, param)の形式の函数で与える仕様になっています。
だから、HMC函数および関連の函数にはポテンシャル函数を決めるためのparamを渡す必要があります。
nbviewer.org/github/genkuro…
だから、HMC函数および関連の函数にはポテンシャル函数を決めるためのparamを渡す必要があります。
nbviewer.org/github/genkuro…

#Julia言語 のLTS (long-term support)について誤解があるような気がするので、開発者の言葉を引用します。
添付画像は
discourse.julialang.org/t/what-are-the…
のKarpinskiさんの発言のDeepLによる自動翻訳です。
引用【大多数の人は、LTSに留まらず、最新のJuliaバージョンを使うべきです。】
添付画像は
discourse.julialang.org/t/what-are-the…
のKarpinskiさんの発言のDeepLによる自動翻訳です。
引用【大多数の人は、LTSに留まらず、最新のJuliaバージョンを使うべきです。】

#Julia言語 引用続き【LTSを使うべきなのは、アップグレードのプロセスを踏むのが非常に高価でリスクが高い場合だけで、99%のユーザーにとってはそうではありません。最新かつ最高の機械学習機能を必要とする人々は、LTSリリースの対象者ではなく、現在の安定したJuliaバージョンを使用するべきです】
#Julia言語 引用続き【例えば,多くのパッケージでは,Julia 1.3がアーティファクトやマルチスレッドを導入したため,長い間,下限値となっていました.これは公式のLTSではありませんでしたが、パッケージが持つべき立派な下限でした。】
LTSは重要なパッケージのサポート対象から外れることもある。
LTSは重要なパッケージのサポート対象から外れることもある。
こんな所に #Julia言語 を発見!
↓
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
↓
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
↓
p.5
↓
↓
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
↓
watanabe-www.math.dis.titech.ac.jp/users/swatanab…
↓
p.5
↓

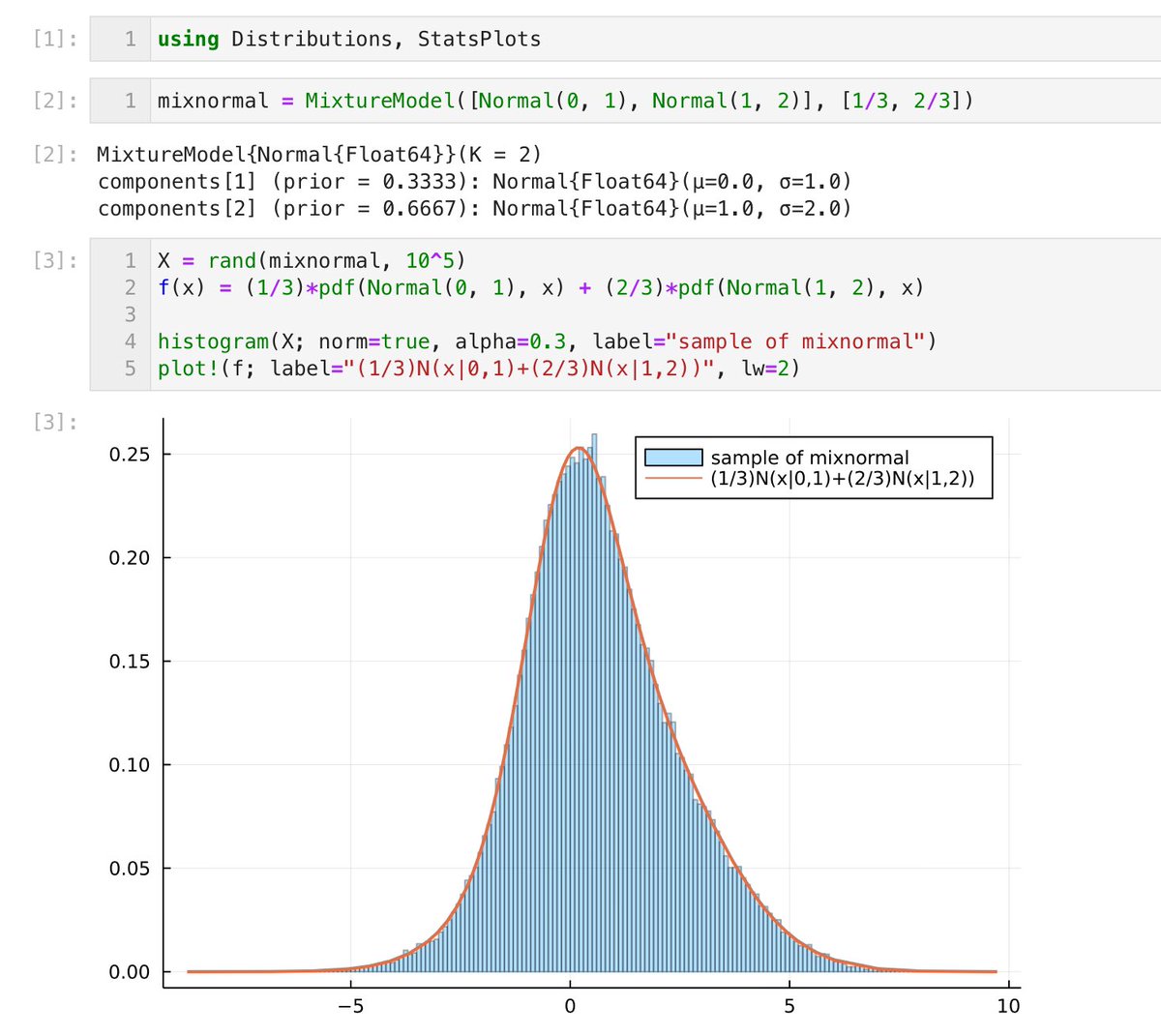
#Julia言語 1つ前のツイートの添付画像中にある自己チェック問題のJuliaでの解答はシンプルで自然。
mixnormal = MixtureModel([Normal(0, 1), Normal(1, 2)], [1/3, 2/3])
rand(mixnormal)
でよい。混合正規分布を意味するオブジェクトを作れば、randやpdfやcdfなどが全部使える。
mixnormal = MixtureModel([Normal(0, 1), Normal(1, 2)], [1/3, 2/3])
rand(mixnormal)
でよい。混合正規分布を意味するオブジェクトを作れば、randやpdfやcdfなどが全部使える。
#Julia言語 相互リンク↓
#Julia言語
C++は避けるべき。
できあいの統計関連のライブラリやパッケージを主に使うなら、Rが多分良くて、Pythonも良いと思います。
サンプルコードでアルゴリズムも示したいならば、ほぼJulia一択だと思います。
実際、須山敦志さんはJuliaを早くから使い始めて大成功しているように見える。
C++は避けるべき。
できあいの統計関連のライブラリやパッケージを主に使うなら、Rが多分良くて、Pythonも良いと思います。
サンプルコードでアルゴリズムも示したいならば、ほぼJulia一択だと思います。
実際、須山敦志さんはJuliaを早くから使い始めて大成功しているように見える。
#Julia言語
machine-learning.hatenablog.com/search?q=Julia
で須山さんによるJuliaを利用した確率統計の学び方を知ることができる。Juliaは高速かつ強力かつ気楽に使えるので、試しに自力実装するのに非常に向いている。
amazon.co.jp/dp/4065259800
Juliaで作って学ぶベイズ統計学 (KS情報科学専門書)
2021/11/26
須山敦志
machine-learning.hatenablog.com/search?q=Julia
で須山さんによるJuliaを利用した確率統計の学び方を知ることができる。Juliaは高速かつ強力かつ気楽に使えるので、試しに自力実装するのに非常に向いている。
amazon.co.jp/dp/4065259800
Juliaで作って学ぶベイズ統計学 (KS情報科学専門書)
2021/11/26
須山敦志
#統計 #Julia言語
コインを20回投げたときの表が出る回数の分布は正規分布で近似される。
Juliaのコードがシンプルであること、確率分布を意味するオブジェクトを作って、確率函数、乱数、プロットで使えること、などに注目!
nbviewer.org/github/genkuro…
コインを20回投げたときの表が出る回数の分布は正規分布で近似される。
Juliaのコードがシンプルであること、確率分布を意味するオブジェクトを作って、確率函数、乱数、プロットで使えること、などに注目!
nbviewer.org/github/genkuro…



#統計 私は、WAICユーザーの大部分がWAICを誤用している疑いがある血思っています。
ベイズ統計ユーザーの多くは階層化されたモデルを使っていると思います。その場合には内部パラメータで積分してWAICを求める必要があります。手動でそうする必要があるし、計算量も大きく増える。
ベイズ統計ユーザーの多くは階層化されたモデルを使っていると思います。その場合には内部パラメータで積分してWAICを求める必要があります。手動でそうする必要があるし、計算量も大きく増える。
#統計 日本はWAICの発祥地なので(笑)、日本語圏ではWAIC(やLOOCV)の誤用に関する情報を手に入れ易い。
いれいさんもWAICを簡単に誤用できることと、誤用せずに済ませることが大変なことに気付いている。
いれいさんもWAICを簡単に誤用できることと、誤用せずに済ませることが大変なことに気付いている。
#統計 HiroさんもWAICの誤用に気付いている。
Stanのような確率プログラミング言語で記述される「モデル」の情報(よくグラフィカルモデルで表現される)だけでは、予測分布が一意に決まらず、汎化誤差もWAICも確定しない。
通常の場合には「周辺化」版予測分布を使わないとアウト。
Stanのような確率プログラミング言語で記述される「モデル」の情報(よくグラフィカルモデルで表現される)だけでは、予測分布が一意に決まらず、汎化誤差もWAICも確定しない。
通常の場合には「周辺化」版予測分布を使わないとアウト。
#Julia言語 デフォルトのコンストラクタ:
struct Kuma{T}
p::Tuple{T, T}
end
とするだけで、デフォルトのコンストラクタ達
* Kuma(p::Tuple{T, T}) where T
* Kuma{T}(p) where T
が定義され、後者は引数の型変換も行なってくれる。
多くの場合にこれで十分。
github.com/genkuroki/publ…
struct Kuma{T}
p::Tuple{T, T}
end
とするだけで、デフォルトのコンストラクタ達
* Kuma(p::Tuple{T, T}) where T
* Kuma{T}(p) where T
が定義され、後者は引数の型変換も行なってくれる。
多くの場合にこれで十分。
github.com/genkuroki/publ…

#Julia言語 struct ~ end の内側に自前のコンストラクタの定義を書くと(内部コンストラクタを定義すると)、それらのデフォルトのコンストラクタは定義されなくなります。
複雑な内部コンストラクタが沢山書いてあるコードは読み難いの出注意。
複雑な内部コンストラクタが沢山書いてあるコードは読み難いの出注意。
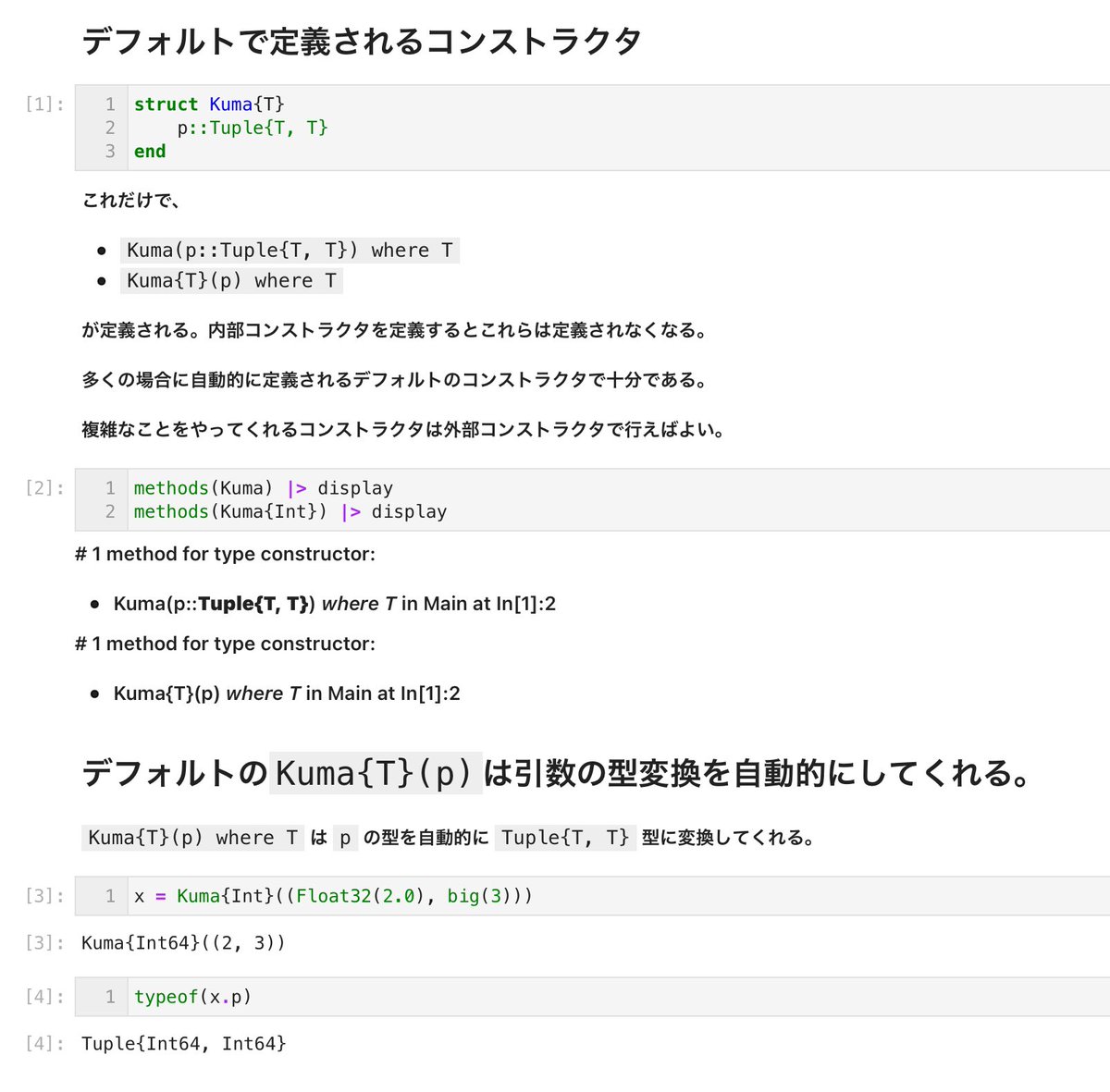
#Julia言語 デフォルトのコンストラクタを破棄したい理由がある場合や、`new`を使わないとできないことをやる場合以外に、内部コンストラクタは無理に使わない方が良いと思う。
使う場合にも内部コンストラクタの個数はできるだけ少なくするべき。
↓
公式ドキュメント
docs.julialang.org/en/v1/manual/c…
使う場合にも内部コンストラクタの個数はできるだけ少なくするべき。
↓
公式ドキュメント
docs.julialang.org/en/v1/manual/c…

#Julia言語 で include や Revise.includet を使っている人達は、どこかの段階で、自分専用パッケージをものすごく簡単に作れることに気付いて、
using MyPkg
のようにして、自分が書いたコードを使うようにすれば楽しいと思います。もちろん、using MyPkgの前にusing Reviseしておくと便利。続く
using MyPkg
のようにして、自分が書いたコードを使うようにすれば楽しいと思います。もちろん、using MyPkgの前にusing Reviseしておくと便利。続く
#Julia言語 適当なディレクトリで
pkg> generate MyPkg
pkg> dev ./MyPkg
とすると
MyPkg/Ptoject.toml
MyPkg/src/MyPkg.jl
が作成され、
julia> using Revise
julia> using MyPkg
で使えるようになり、MyPkg.jlの編集結果がREPLに自動反映される。
pkg> generate MyPkg
pkg> dev ./MyPkg
とすると
MyPkg/Ptoject.toml
MyPkg/src/MyPkg.jl
が作成され、
julia> using Revise
julia> using MyPkg
で使えるようになり、MyPkg.jlの編集結果がREPLに自動反映される。

#Julia言語 のREPLは、shell (badh, zsh, fish, ...)のようなもので、自分で書いたshell scriptsの集まりの類似物は、自分がよく使う函数などをまとめたパッケージです。パッケージ中の函数をREPL内で組み合わせて仕事を行う。
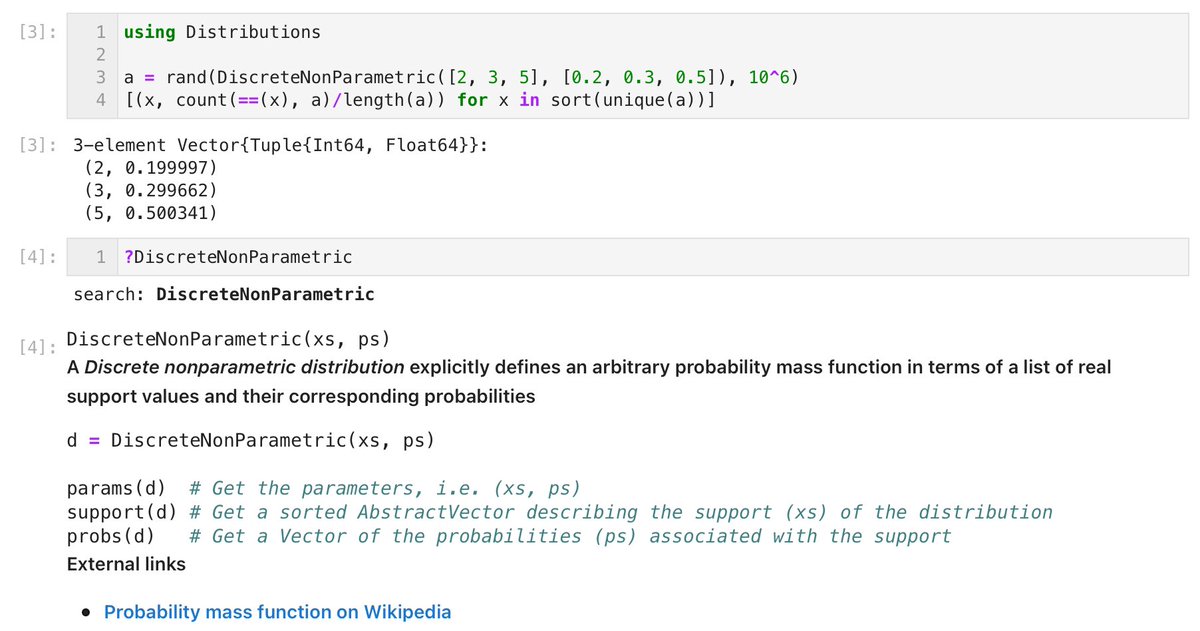
#Julia言語 値の集合から確率を指定してサンプルを1つ抽出する方法
using StatsBase
a = sample([2, 3, 5], ProbabilityWeights([0.2, 0.3, 0.5]))
using Distributions
a = rand(DiscreteNonParametric([2, 3, 5], [0.2, 0.3, 0.5]))
複数取り出す場合は添付画像。
github.com/genkuroki/publ…
using StatsBase
a = sample([2, 3, 5], ProbabilityWeights([0.2, 0.3, 0.5]))
using Distributions
a = rand(DiscreteNonParametric([2, 3, 5], [0.2, 0.3, 0.5]))
複数取り出す場合は添付画像。
github.com/genkuroki/publ…

#Julia言語 Juliaでappend!は配列に配列を追加するために使うことが普通で、配列に要素を追加するために普通使うのはpush!です。REPLで
julia> ?
help?> append!
julia> ?
help?> push!
を確認してみてください。REPLに ? で質問すると沢山のことが分かります。続く
julia> ?
help?> append!
julia> ?
help?> push!
を確認してみてください。REPLに ? で質問すると沢山のことが分かります。続く

#Julia言語 Pythonから来た人達がよくやっている失敗は
a = []
for i in 1:n
xを計算
push!(a, x)
end
というコードで長さnの1次元配列を作ること。
このaのeltype(a)はAnyになるので、aを使う計算が数十倍遅くなる。
具体的に他のどのような書き方が適切であるかはケースバイケース。続く
a = []
for i in 1:n
xを計算
push!(a, x)
end
というコードで長さnの1次元配列を作ること。
このaのeltype(a)はAnyになるので、aを使う計算が数十倍遅くなる。
具体的に他のどのような書き方が適切であるかはケースバイケース。続く
#Julia言語 『数値計算の常識』という有名な本があって第5章のタイトルが「逆行列よさようなら」です。
Juliaでは計画行列Xによるバックスラッシュ演算
β̂ = X \ y
の一発で最小二乗法も計算できます。
github.com/genkuroki/publ…
Juliaでは計画行列Xによるバックスラッシュ演算
β̂ = X \ y
の一発で最小二乗法も計算できます。
github.com/genkuroki/publ…

#数楽 Xが縦長の行列で、β, y が縦ベクトルのときの、βの成分に関する連立一次方程式
Xβ = y
は一般に解を持たないのですが、Xβとyのユークリッド距離を最小にするようなβをβ̂と書いて、「解」とみなすのが最小二乗法の考え方です。その「解」を
β̂ = X \ y
と書くことは記号法的に自然です。
Xβ = y
は一般に解を持たないのですが、Xβとyのユークリッド距離を最小にするようなβをβ̂と書いて、「解」とみなすのが最小二乗法の考え方です。その「解」を
β̂ = X \ y
と書くことは記号法的に自然です。
#Julia言語 Juliaがバックスラッシュ二項演算子で最小二乗法も可能にしていることの背景には以上のような数学が隠れています。
東京大学出版会の『統計学入門』を運悪く「真面目」に読んでしまい、それに従って、「確率ではなく、割合だ」というスタイルで「信頼区間警察」をやっている側が狼藉之義也の「ヒャッハー」達だという問題。
へたをするとこれが高校数学にも伝搬する恐れがある。
へたをするとこれが高校数学にも伝搬する恐れがある。
最近の例では
tjo.hatenablog.com/entry/2021/07/…
渋谷駅前で働くデータサイエンティストのブログ
2021-07-16
95%信頼区間の「95%」の意味
がひどい。
教科書に書いてあるという事実は正しいことの証拠にはなりません。
tjo.hatenablog.com/entry/2021/07/…
渋谷駅前で働くデータサイエンティストのブログ
2021-07-16
95%信頼区間の「95%」の意味
がひどい。
教科書に書いてあるという事実は正しいことの証拠にはなりません。
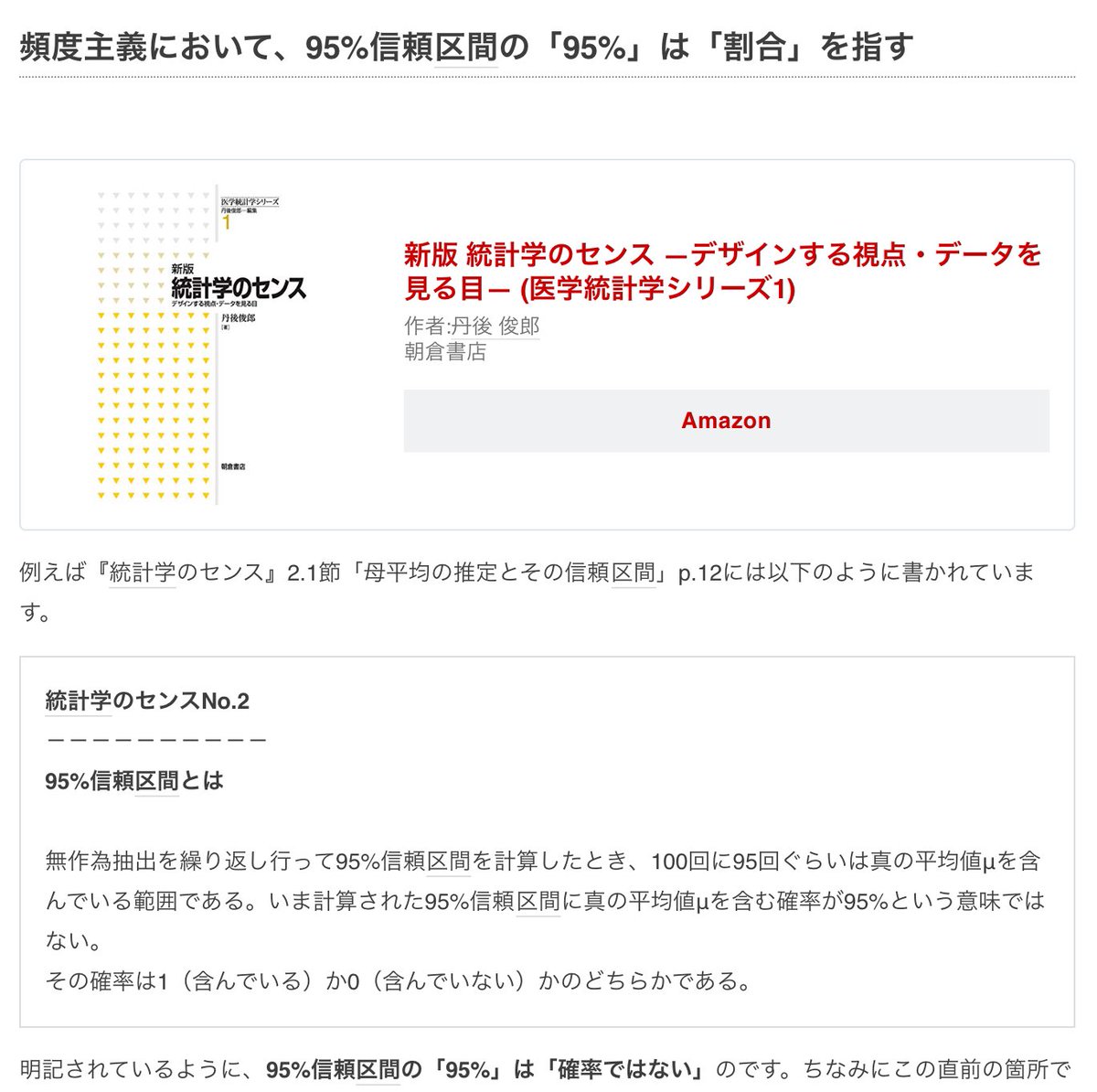
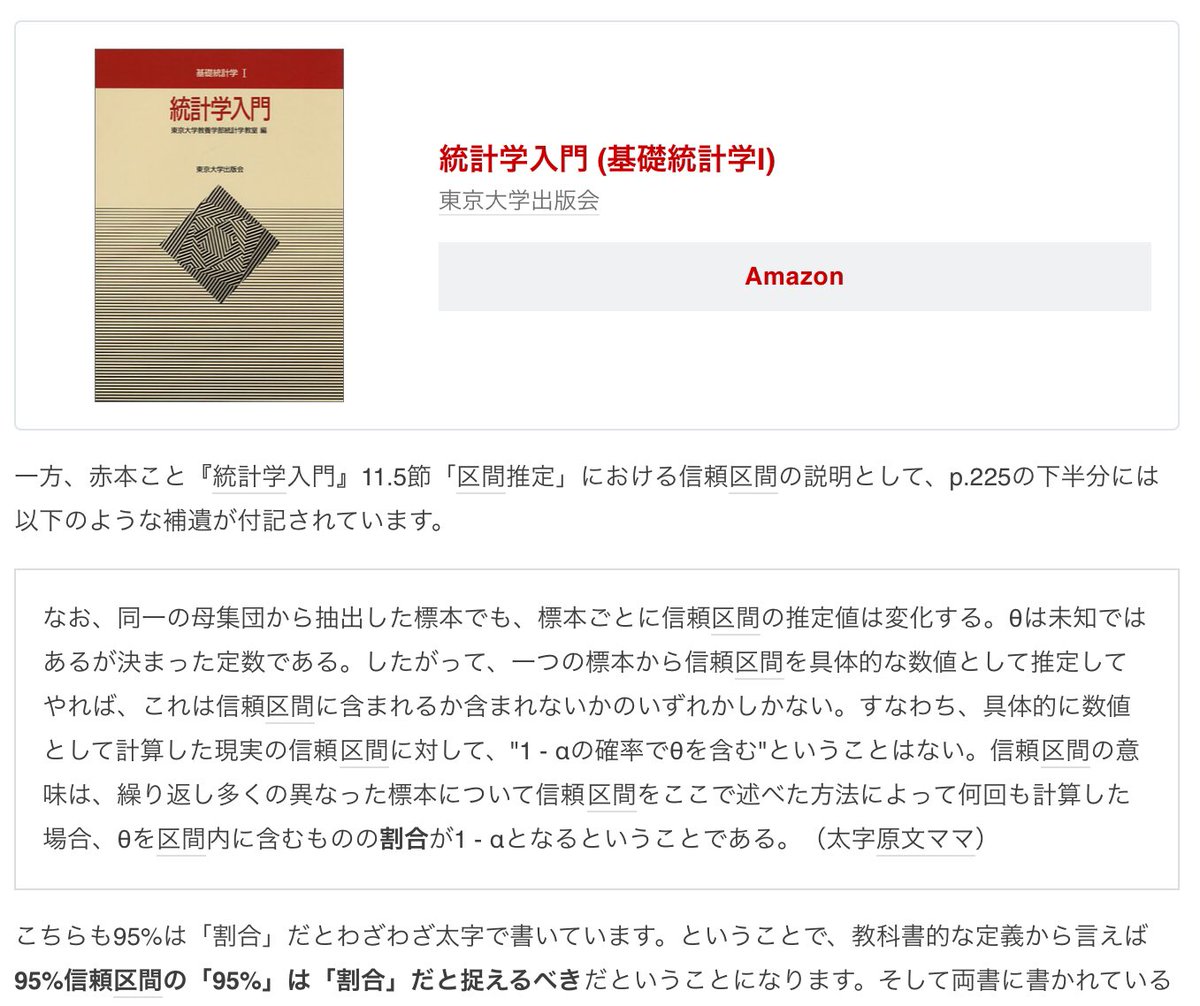
#統計 正しい考え方
* 信頼区間の計算では通常パラメータを持つモデル(例えば正規分布モデルや二項分布モデルなど)が使われる。
* 95%信頼区間の95%はそのモデル内での標本分布で測った確率(の近似値)になる。
* 使用したモデルが現実において妥当でなければ、信頼区間は信頼できないものになる。
* 信頼区間の計算では通常パラメータを持つモデル(例えば正規分布モデルや二項分布モデルなど)が使われる。
* 95%信頼区間の95%はそのモデル内での標本分布で測った確率(の近似値)になる。
* 使用したモデルが現実において妥当でなければ、信頼区間は信頼できないものになる。
#Julia言語 1万人に一人あたり100万円配って、その後ランダムに誰かから1万円を取り上げて(破産していたら取るのを諦める)、別の誰かに配ることを繰り返したときの、保有金額の分布の推移のアニメーション。
分布の収束先は不平等な指数分布。
これは「税額一定」の場合。
github.com/genkuroki/publ…
分布の収束先は不平等な指数分布。
これは「税額一定」の場合。
github.com/genkuroki/publ…
#Julia言語 不平等な指数分布になった後に、今度はランダムに誰かを選んで保有金額の5%の税金を徴収して別の誰かに配ることを繰り返すとこうなる。
分布の収束先はかなり平等的なガンマ分布。
証明は知らない。誰か教えて!(笑)
(((わざと真剣に考えていない)))
github.com/genkuroki/publ…
分布の収束先はかなり平等的なガンマ分布。
証明は知らない。誰か教えて!(笑)
(((わざと真剣に考えていない)))
github.com/genkuroki/publ…
#Julia言語 ここからが真に面白い話になる。
さて、ついさっき税額ではなく、税率を一定にしたランダムな富の分配で平等に近付けることができることを紹介した。
税率は5%だった。
問題:税率を50%に上げるとさらに平等になるか?
さて、ついさっき税額ではなく、税率を一定にしたランダムな富の分配で平等に近付けることができることを紹介した。
税率は5%だった。
問題:税率を50%に上げるとさらに平等になるか?
#Julia言語
色々よく分かっていないあいだは、内部コンストラクタを定義しない方が無難だという話。
添付画像は
github.com/genkuroki/publ…
より。これの1つ前のコードでは赤枠部分の外部コンストラクタしか定義されていなかった。青枠部分は後で追加された。
続く
色々よく分かっていないあいだは、内部コンストラクタを定義しない方が無難だという話。
添付画像は
github.com/genkuroki/publ…
より。これの1つ前のコードでは赤枠部分の外部コンストラクタしか定義されていなかった。青枠部分は後で追加された。
続く

#Julia言語
struct Foo{T}
a::T
b::T
Foo(a::T) where T = new{T}(a, T(2)a)
end
と内部コンストラクタFoo(a)を定義すると、これ以外にFoo型のオブジェクトを作る方法が失われ、フィールドbは常にaの2倍になることになります。
この仕様を変更するにはコードの変更が必要になる。
struct Foo{T}
a::T
b::T
Foo(a::T) where T = new{T}(a, T(2)a)
end
と内部コンストラクタFoo(a)を定義すると、これ以外にFoo型のオブジェクトを作る方法が失われ、フィールドbは常にaの2倍になることになります。
この仕様を変更するにはコードの変更が必要になる。
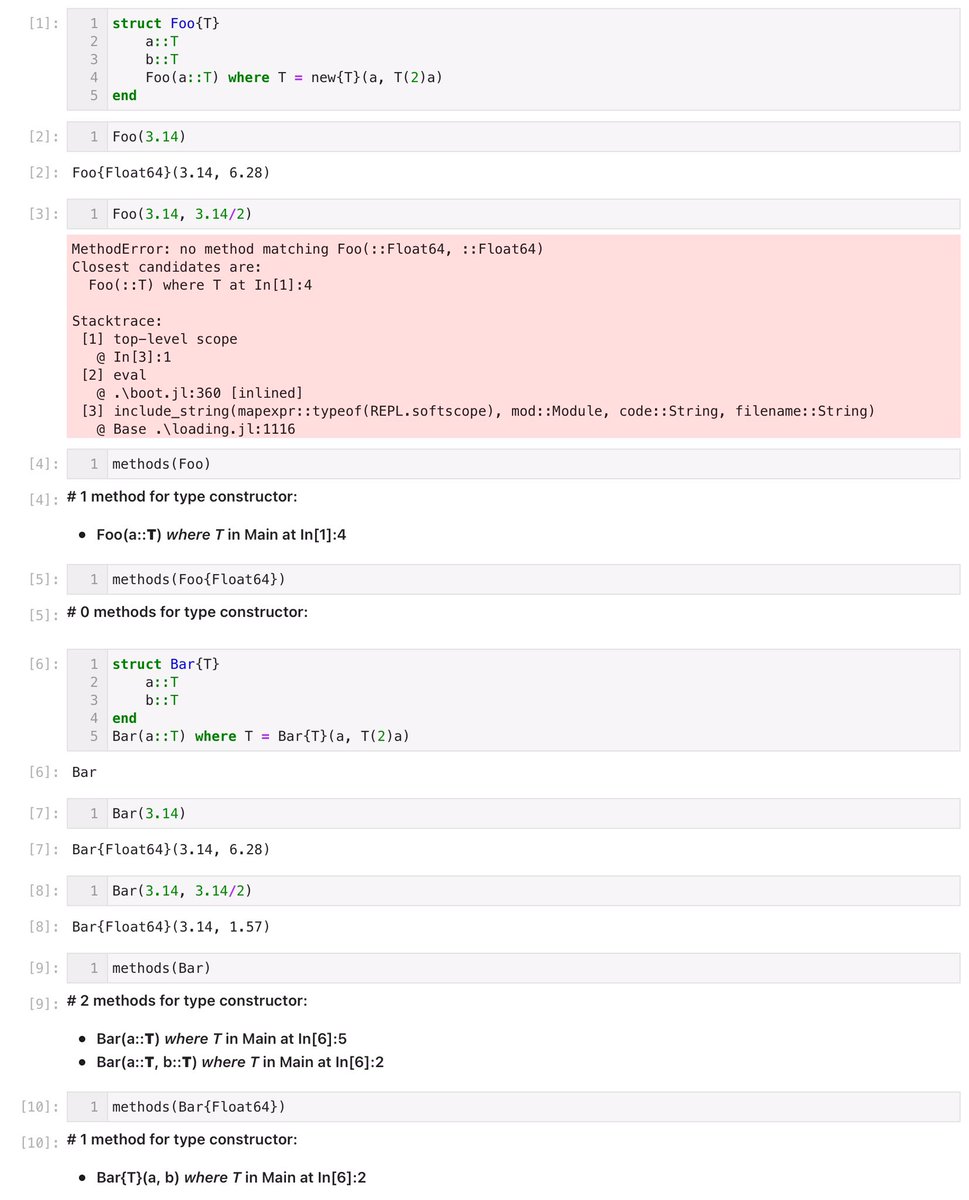
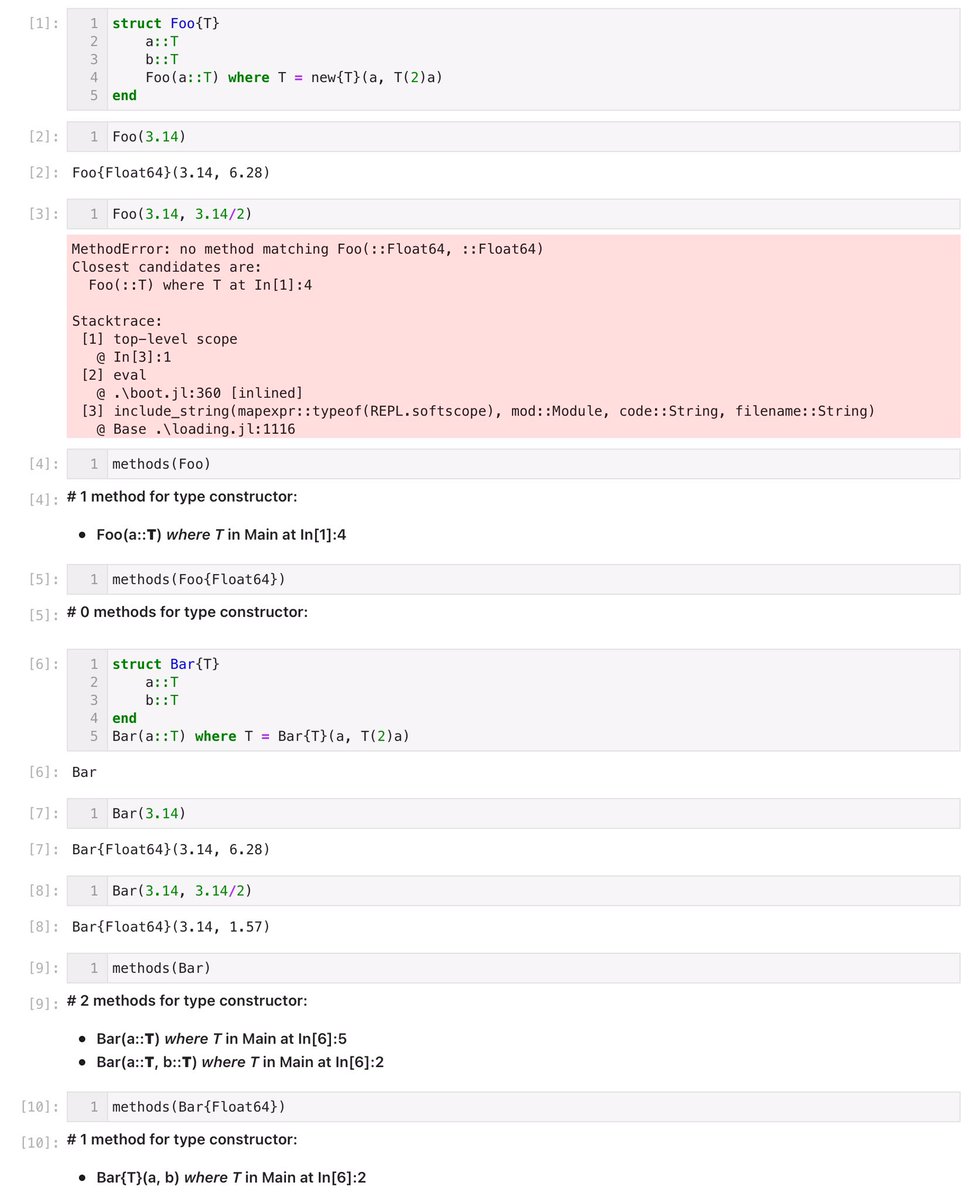
#Julia言語 一方、
struct Bar{T}
a::T
b::T
end
Bar(a::T) where T = Bar{T}(a, T(2)a)
と内部コンストラクタを定義せずに、外部コンストラクタBar(a)を定義しているなら、デフォルトで定義されているBar(a, b)を使ってbをaの2倍以外の値に設定できます。
struct Bar{T}
a::T
b::T
end
Bar(a::T) where T = Bar{T}(a, T(2)a)
と内部コンストラクタを定義せずに、外部コンストラクタBar(a)を定義しているなら、デフォルトで定義されているBar(a, b)を使ってbをaの2倍以外の値に設定できます。
#Julia言語 グローバル変数Aを参照する
S(x) = S(A, x)
の類の函数の定義は計算効率重視なら避けるべき。
しかし、これができないと途方に暮れる人もいるかもしれない。
そういう人は
github.com/genkuroki/publ…
github.com/genkuroki/publ…
のスタイルをパクればよい。
S(x) = S(A, x)
の類の函数の定義は計算効率重視なら避けるべき。
しかし、これができないと途方に暮れる人もいるかもしれない。
そういう人は
github.com/genkuroki/publ…
github.com/genkuroki/publ…
のスタイルをパクればよい。
#Julia言語
あと、初心者のうちは、内部コンストラクタを使わざるを得ない場合を除いて、内部コンストラクタを定義しない方が無難だと思う。要するに、初心者段階では
struct Foo{A, B}
a::A
b::B
function Foo(~) ~ new(a, b) end
end
のようにできるだけ書かないようにする。続く
あと、初心者のうちは、内部コンストラクタを使わざるを得ない場合を除いて、内部コンストラクタを定義しない方が無難だと思う。要するに、初心者段階では
struct Foo{A, B}
a::A
b::B
function Foo(~) ~ new(a, b) end
end
のようにできるだけ書かないようにする。続く
#Julia言語 代わりに、単に
struct Foo{A, B}
a::A
b::B
end
と書くか、必要に応じて外部コンストラクタを
function Foo(~) ~ Foo(a, b) end
のように定義しておく。続く
struct Foo{A, B}
a::A
b::B
end
と書くか、必要に応じて外部コンストラクタを
function Foo(~) ~ Foo(a, b) end
のように定義しておく。続く
#Julia言語 100以下の素数
(a->a[a.∉(a*a',)])(2:100)
これを理解すれば、色々理解できたことになる。
九九の表は (1:9)*(1:9)' で作れる。
∉ は \notin TAB で入力できる。
a.∉(a*a',)の代わりにa.∉Ref(a*a')と書くことが多い。
実験するときには
a = 2:100
a[a.∉(a*a',)]
を試すとよい。
(a->a[a.∉(a*a',)])(2:100)
これを理解すれば、色々理解できたことになる。
九九の表は (1:9)*(1:9)' で作れる。
∉ は \notin TAB で入力できる。
a.∉(a*a',)の代わりにa.∉Ref(a*a')と書くことが多い。
実験するときには
a = 2:100
a[a.∉(a*a',)]
を試すとよい。

#Julia言語 解説
a = 2:100
のとき、aは2,3,4,...,100が縦に並んでいるベクトル扱いになる。
a'はaの転置で、横ベクトル扱いされる。
a*a' は通常の線形代数によって、2,3,4,...,100の2つの数の積を並べた99×99行列になる。続く
a = 2:100
のとき、aは2,3,4,...,100が縦に並んでいるベクトル扱いになる。
a'はaの転置で、横ベクトル扱いされる。
a*a' は通常の線形代数によって、2,3,4,...,100の2つの数の積を並べた99×99行列になる。続く

#Julia言語 100以下の素数全体は、a = 2:100 に含まれる数で行列 a*a' に含まれないものの全体に一致する。
a .∉ (a*a',) は a の各要素 k に写像 k ↦ k ∉ a*a' を作用させた結果になる。真偽値達のBitVectorになる。続く
a .∉ (a*a',) は a の各要素 k に写像 k ↦ k ∉ a*a' を作用させた結果になる。真偽値達のBitVectorになる。続く

