Discover and read the best of Twitter Threads about #数楽
Most recents (24)

#数楽 ℤ[√2]やℤ[√3]はEuclid整域なのでPIDでUFDになるので、ℤ[√2]やℤ[√3]係数の多項式の √2や√3が出て来る因数分解の問題も既約元の積に分解する問題として意味を持ちます。続く
私は、環論を学ぶまで、重根もしくは重解の概念を十分に理解できた感じがしてなかったです。(代数)方程式の概念も同様。
実数体上の方程式x²=0は環
A = ℝ[x]/(x²)
で表現されます。これと方程式x=0に対応する環
ℝ[x]/(x)
は異なる。環論を使えば方程式x²=0とx=0を明瞭に区別できます。
実数体上の方程式x²=0は環
A = ℝ[x]/(x²)
で表現されます。これと方程式x=0に対応する環
ℝ[x]/(x)
は異なる。環論を使えば方程式x²=0とx=0を明瞭に区別できます。
環k上の環Aで表現された方程式のk上の環Bでの解集合はk上の環準同型全体の集合
Hom_{k-ring}(A, B)
で表現されます。例えば、集合として、
Hom_{ℝ-ring}(ℝ[x,y]/(x²+y²-1), ℝ) ≅ {(x,y)∈ℝ²|x²+y²=1}.
Hom_{k-ring}(A, B)
で表現されます。例えば、集合として、
Hom_{ℝ-ring}(ℝ[x,y]/(x²+y²-1), ℝ) ≅ {(x,y)∈ℝ²|x²+y²=1}.
そして、以上のような代数方程式の表現になっている環の話について前もって知っておいた方が、環論の勉強はしやすいように思えます。
#数楽
a(n+1)=3a(n)+2ⁿ は Ta(n)=a(n+1) を使えば
(*) (T-3)a(n)=2ⁿ
と書き直せる。(T-2)2ⁿ=0なので、
(*)⇒(T-2)(T-3)a(n)=0.
ゆえに(*)の解は
a(n)=A×3ⁿ+B×2ⁿ
と書ける。このとき(*)⇔B=-1.
以上の完全に機械的な解法は大幅に一般化可能。
a(n+1)=3a(n)+2ⁿ は Ta(n)=a(n+1) を使えば
(*) (T-3)a(n)=2ⁿ
と書き直せる。(T-2)2ⁿ=0なので、
(*)⇒(T-2)(T-3)a(n)=0.
ゆえに(*)の解は
a(n)=A×3ⁿ+B×2ⁿ
と書ける。このとき(*)⇔B=-1.
以上の完全に機械的な解法は大幅に一般化可能。
#数楽 Ta(n+1)=a(n)と書く。
(Tⁿ+p₁Tⁿ⁻¹+…+pₙ)a(n) = 0
の形の斉次方程式の解の形が完全にわかっていることを使えば、f(n)がそのような形の斉次方程式の解であるときの
(Tⁿ+p₁Tⁿ⁻¹+…+pₙ)a(n) = f(n)
の形の非斉次の場合も機械的に解ける。技巧的な式の変形技術は無用になる。
(Tⁿ+p₁Tⁿ⁻¹+…+pₙ)a(n) = 0
の形の斉次方程式の解の形が完全にわかっていることを使えば、f(n)がそのような形の斉次方程式の解であるときの
(Tⁿ+p₁Tⁿ⁻¹+…+pₙ)a(n) = f(n)
の形の非斉次の場合も機械的に解ける。技巧的な式の変形技術は無用になる。
#数楽 そういう技巧を不要にする機械的解法は、
ある種の方程式を満たす数列全体の集合が具体的に完全にわかっていること
から、ただちに出て来る。
ある街の様子を完全に知っていれば、その街で苦労無しに快適に暮らせるのと似ている。
ある種の方程式を満たす数列全体の集合が具体的に完全にわかっていること
から、ただちに出て来る。
ある街の様子を完全に知っていれば、その街で苦労無しに快適に暮らせるのと似ている。
#数楽 差分作用素をTf(n)=f(n+1)と書く。
a,b,cが異なるとき、
A aⁿ + B bⁿ + C cⁿ
は(T-a)(T-b)(T-c)の作用で消える。
(bⁿ-aⁿ)/(b-a)のb→aの極限naⁿ⁻¹なので
A aⁿ + A' naⁿ⁻¹ + C cⁿ
は(T-a)²(T-c)の作用で消える。続き
a,b,cが異なるとき、
A aⁿ + B bⁿ + C cⁿ
は(T-a)(T-b)(T-c)の作用で消える。
(bⁿ-aⁿ)/(b-a)のb→aの極限naⁿ⁻¹なので
A aⁿ + A' naⁿ⁻¹ + C cⁿ
は(T-a)²(T-c)の作用で消える。続き
#統計 c=a+hとおくと、
cⁿ = aⁿ + naⁿ⁻¹h + n(n-1)/2 aⁿ⁻² h² + O(h³)
なので、h→0のとき
(cⁿ - aⁿ - naⁿ⁻¹h)/h² →n(n-1)/2 aⁿ⁻².
ゆえに
A aⁿ + A' naⁿ⁻¹ + A'' n(n-1)/2 aⁿ⁻² = (nの2次以下の多項式) aⁿ
は(T-a)³の作用で消える。
一般の場合も同様。
cⁿ = aⁿ + naⁿ⁻¹h + n(n-1)/2 aⁿ⁻² h² + O(h³)
なので、h→0のとき
(cⁿ - aⁿ - naⁿ⁻¹h)/h² →n(n-1)/2 aⁿ⁻².
ゆえに
A aⁿ + A' naⁿ⁻¹ + A'' n(n-1)/2 aⁿ⁻² = (nの2次以下の多項式) aⁿ
は(T-a)³の作用で消える。
一般の場合も同様。
#数楽 特性方程式が重解を持つときにはJordan標準形を使うと覚えてしまった人がいるかもしれませんが、重解を持たない場合からの極限で重解を持つ場合も理解できます。
系を摂動したときの解の挙動の変化は重要なので、重解を持つ場合を持たない場合で近似することも重要です。
系を摂動したときの解の挙動の変化は重要なので、重解を持つ場合を持たない場合で近似することも重要です。
#数楽
S_n = Σ_{k=n}^∞ 1/(2ᵏk) > 0
とおくと、
S_1 = log 2
なので
a_n = 2ⁿ⁻¹(1 + log 2 - S_n)
となることがわかる。ゆえに
a_n < 2ⁿ⁻¹(1 + log 2) < 2ⁿ.
a_n は 2ⁿ⁻¹(1 + log 2) でよく近似されます。
S_n = Σ_{k=n}^∞ 1/(2ᵏk) > 0
とおくと、
S_1 = log 2
なので
a_n = 2ⁿ⁻¹(1 + log 2 - S_n)
となることがわかる。ゆえに
a_n < 2ⁿ⁻¹(1 + log 2) < 2ⁿ.
a_n は 2ⁿ⁻¹(1 + log 2) でよく近似されます。
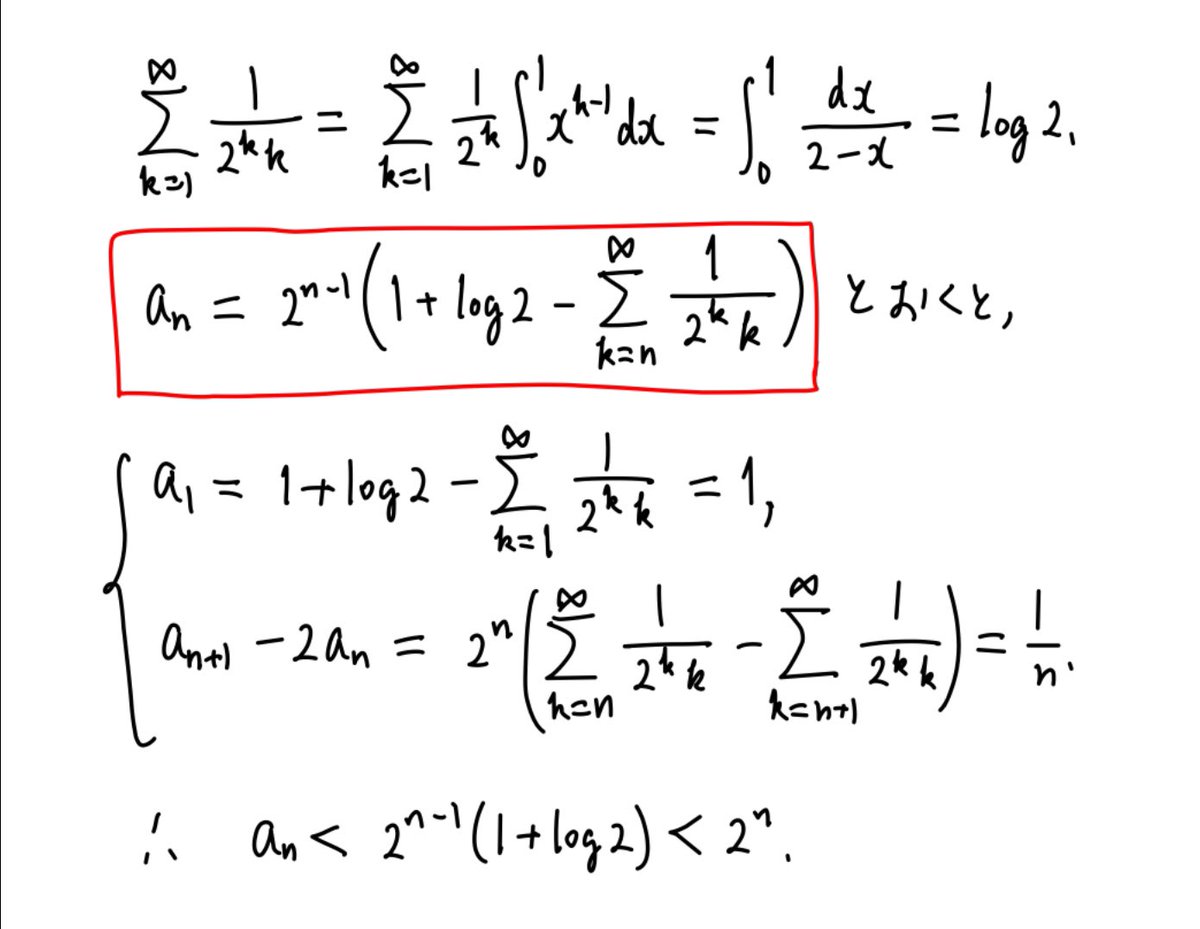
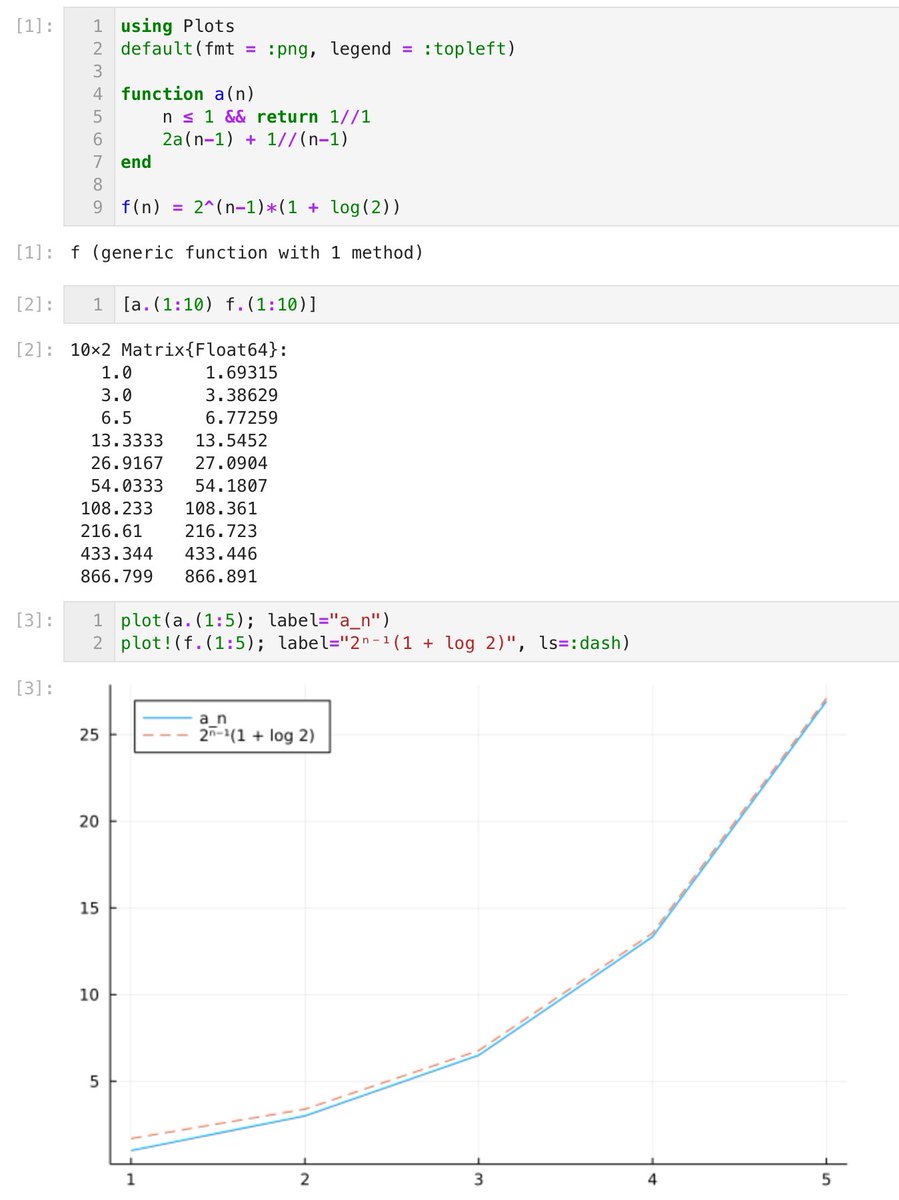
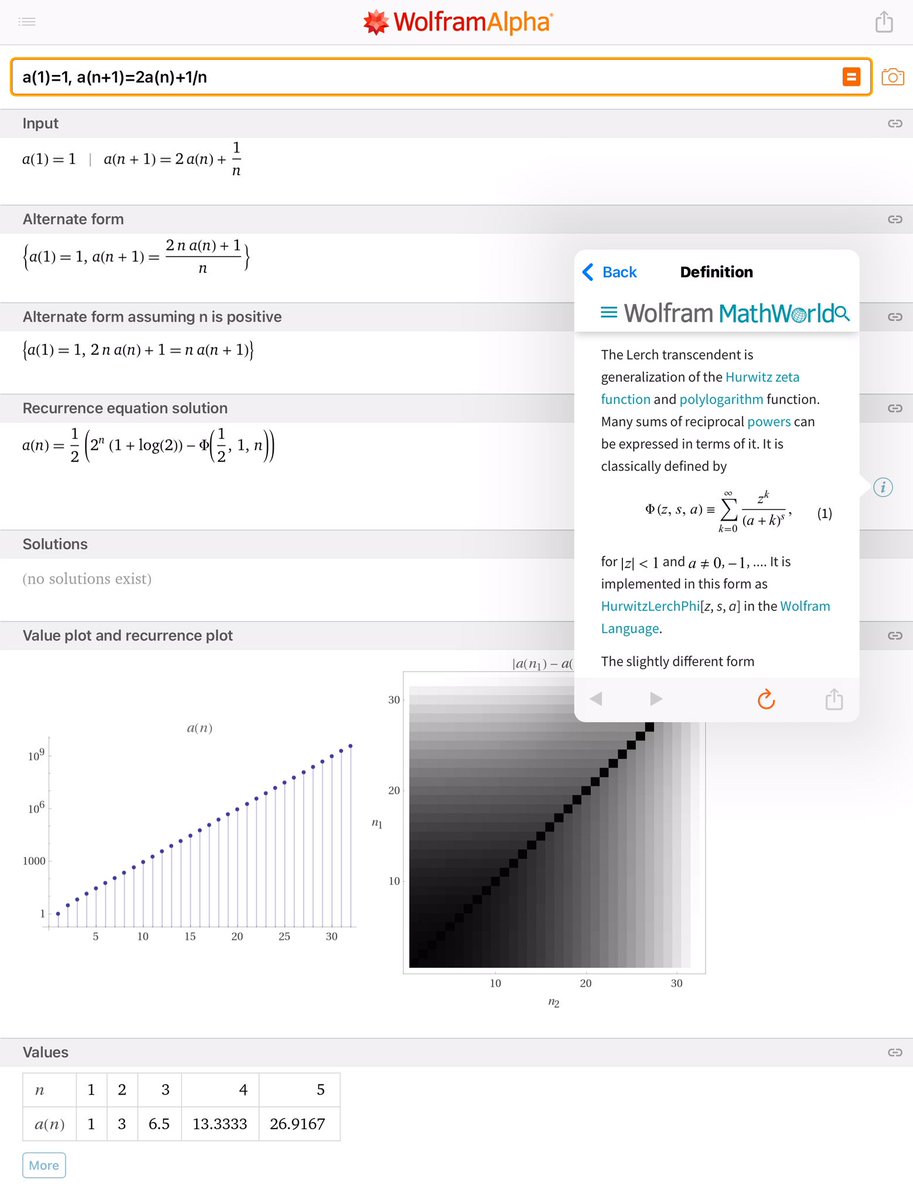
#数楽 不等式による評価は「よりシャープなものを追い求める」ことを考えると楽しくなることが多い。
例えば
a_n < 2ⁿ
よりも
a_n < 2ⁿ⁻¹(1 + log 2)
の方がずっとシャープな結果になっている。
特に教える側は、易しく解けること以上のことを知っていた方がより楽しみやすいと思う。
例えば
a_n < 2ⁿ
よりも
a_n < 2ⁿ⁻¹(1 + log 2)
の方がずっとシャープな結果になっている。
特に教える側は、易しく解けること以上のことを知っていた方がより楽しみやすいと思う。
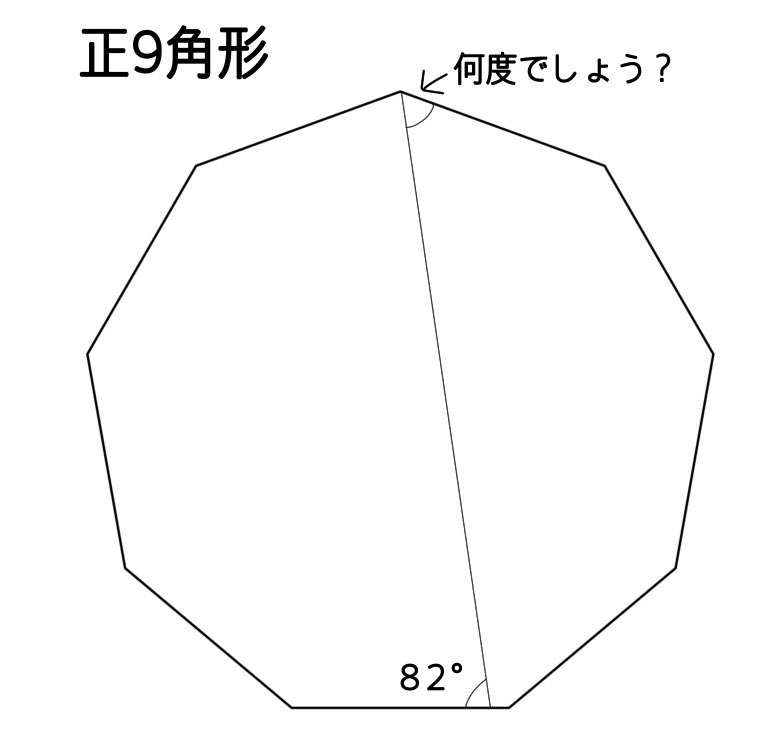
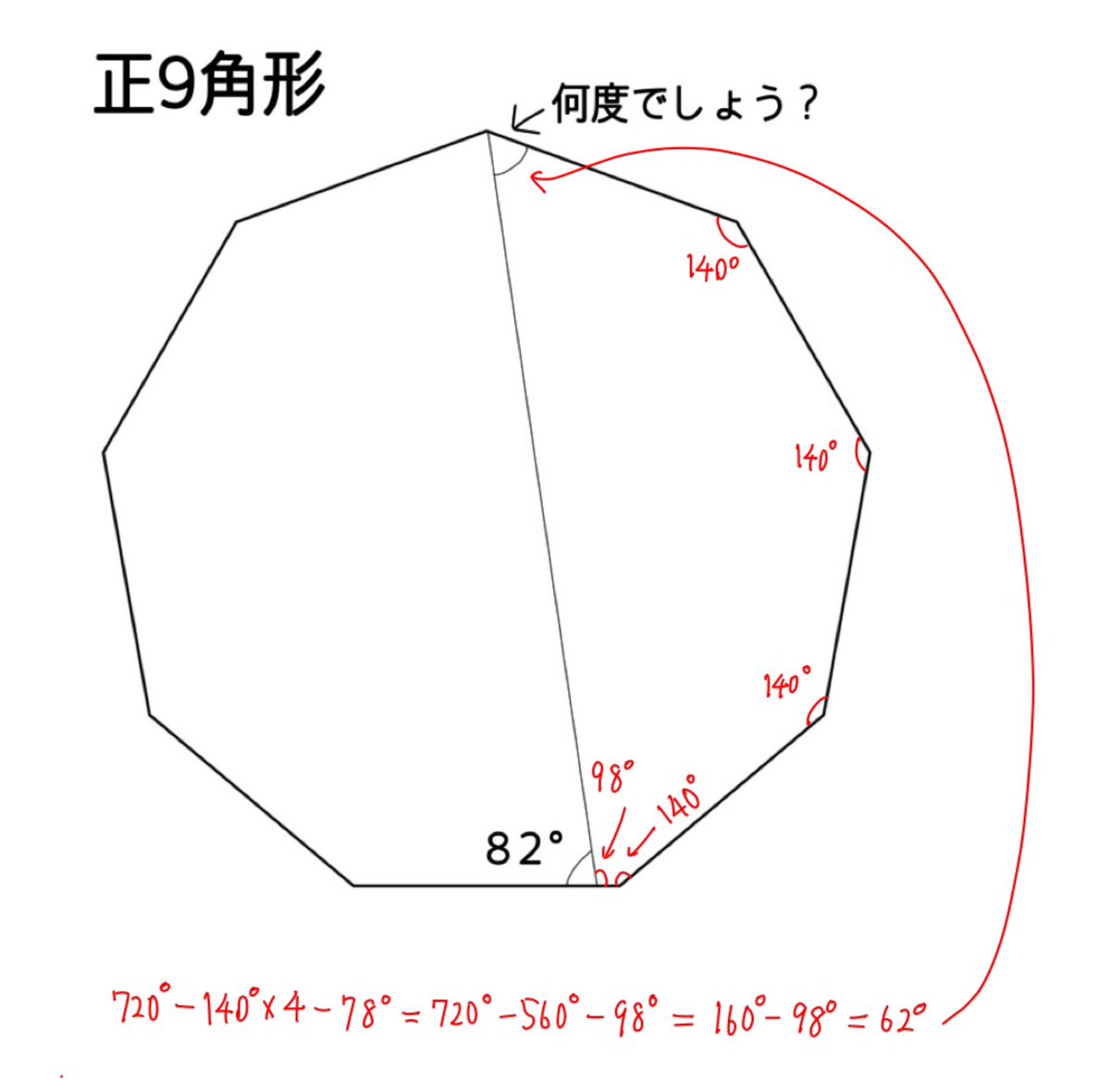
#数楽 子が次の問題を解き始めたので、私が心の中で「正9角形だから各頂点での外角は40度で云々」と考え始めた直後に、「できた!」と言われてくそびっくりした。
10秒で解いた!
解き方が本質を突いていて非常に感心してしまった。
色々な解き方に続く。
10秒で解いた!
解き方が本質を突いていて非常に感心してしまった。
色々な解き方に続く。

#数楽 「ε-Nやε-δにも触れることが多い」程度であれば、偏ったサンプルの元でなら、大学1年生の講義で「習う」というのが大勢と言って良いかも知れませんが、現実にはほとんど触れない場合も多いと思います。
多分長くなるので、引用RTにしました。続く
多分長くなるので、引用RTにしました。続く
#数楽 ε-Nやε-δ以前の問題として、高校での微積分のカリキュラムには沢山の問題があります。大学1年生向けの微積分の講義の最低目標は「その修正」です。
例えば、積分を不定積分で導入して、定積分を "F(b) - F(a)" で導入するのは、積分の実用的な応用の観点から見ても相当に酷いと思います。続く
例えば、積分を不定積分で導入して、定積分を "F(b) - F(a)" で導入するのは、積分の実用的な応用の観点から見ても相当に酷いと思います。続く
#数楽 実用的観点から重要な無限区間での積分が高校の数学のカリキュラムではなぜか教えないことになっているようです。
Gauss積分、ガンマ函数、Fourier変換、Laplace変換などの応用上知らないと確実に困る事柄がごっそり高校数学での微積分から抜け落ちている。
Gauss積分、ガンマ函数、Fourier変換、Laplace変換などの応用上知らないと確実に困る事柄がごっそり高校数学での微積分から抜け落ちている。
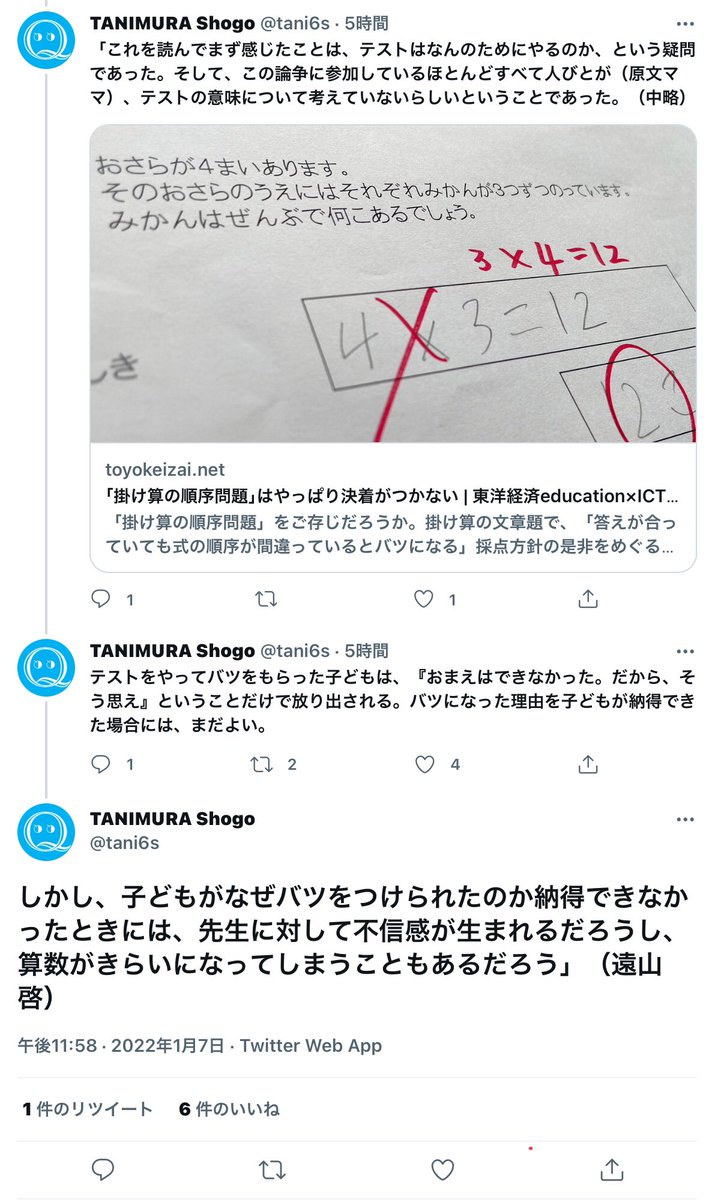
#超算数 谷村省吾さんは遠山啓さんの言葉を孫引きしていますが、実際には遠山さんは彼自身による「量の理論」に基き、かけ算順序固定強制指導を正当化する酷い発言も残しています。
添付画像②を参照。
「量の理論」がその後の算数教育に与えた悪影響について谷村さんは知っているでしょうか?続く
添付画像②を参照。
「量の理論」がその後の算数教育に与えた悪影響について谷村さんは知っているでしょうか?続く

#超算数 遠山啓氏は、自身が広めた「内包量」という困りものの算数数学教育用語を用いてこう言った。
【乗法の交換法則が連続量にはまだ適用しないほうがよいとしたら〜外延量×内包量とは書かないほうがよいだろう】
【単価×分量~とは書くが~分量×単価〜とは書かない】
books.google.co.jp/books?id=Zaiaq…
【乗法の交換法則が連続量にはまだ適用しないほうがよいとしたら〜外延量×内包量とは書かないほうがよいだろう】
【単価×分量~とは書くが~分量×単価〜とは書かない】
books.google.co.jp/books?id=Zaiaq…

#超算数 「量の理論」についても教わってしまったのはまずかったと思います。
昔から数学関係者の一部には、遠山啓さんやその「量の理論」に好意的なせいで、遠山啓さん及びその弟子筋(特に銀林浩氏)が算数数学教育に与えた悪影響を無視する傾向があるという問題があります。
これは頭の痛い問題。
昔から数学関係者の一部には、遠山啓さんやその「量の理論」に好意的なせいで、遠山啓さん及びその弟子筋(特に銀林浩氏)が算数数学教育に与えた悪影響を無視する傾向があるという問題があります。
これは頭の痛い問題。

#超算数 見事に何が問題とされているかを全然理解できていない。
#超算数 【等号「=」の意味の違い】だと説明しようとしている点があまりにも杜撰すぎる。これはひどくデタラメな説明だと言って問題ない。
あと、常識的にはx=x+1やx=xも「その等式を満たす実数xの全体を求めよ」の形で方程式扱いされるので、添付画像の方程式の説明もおかしいです。
あと、常識的にはx=x+1やx=xも「その等式を満たす実数xの全体を求めよ」の形で方程式扱いされるので、添付画像の方程式の説明もおかしいです。

#超算数 【等号「=」の意味の違い】とする説明が批判されているのに、それとは違う杜撰な要約をして、以下のリンク先のように、等号「=」の意味の違いとは全然違う話を始めた。
しかも、その内容もかなり杜撰。
しかも、その内容もかなり杜撰。
#統計 添付画像下段はよくあるベイズ版95%信用区間(確信区間)の最高事後密度(HPD)版です。95%の部分は0から1の間の任意の実数に一般化できる。
添付画像上段のベイズ版P値は「信頼区間と検定が表裏一体」という原理を適用して定義されています。
nbviewer.org/github/genkuro…
添付画像上段のベイズ版P値は「信頼区間と検定が表裏一体」という原理を適用して定義されています。
nbviewer.org/github/genkuro…
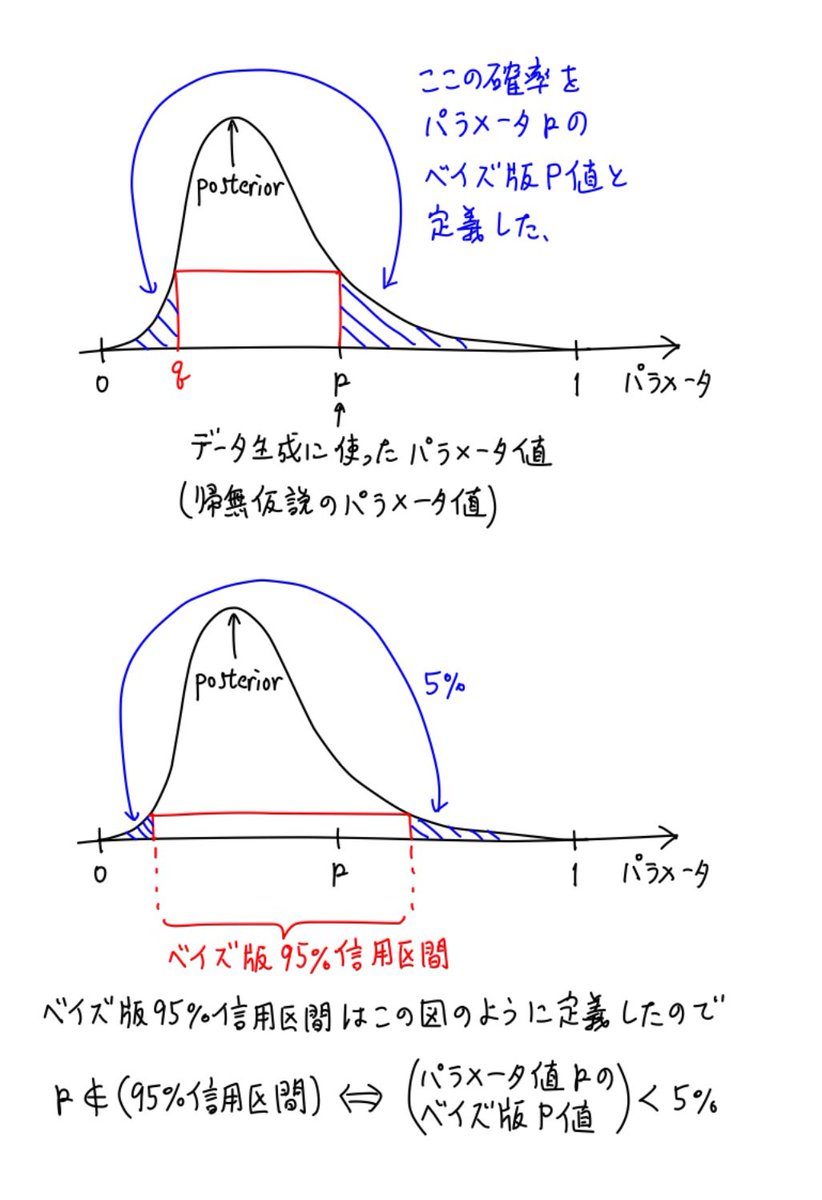
#統計 ベイズ版95%信用区間もベイズ版のP値も事後分布の情報だけを使って定義されており、通常の信頼区間やP値の作り方とは異なります。
しかし、数学には定義が全然違う量がある条件のもとでほぼ同じ値になることを証明できる場合が多数あって、解析学の基本的な考え方になっています。
しかし、数学には定義が全然違う量がある条件のもとでほぼ同じ値になることを証明できる場合が多数あって、解析学の基本的な考え方になっています。
#統計 実践的には無視できる違いしかない2つの数学的量を使った分析や推論は平等な扱いをする必要があります。
❌定義の違いは規範の違いから来ている。違いを無視できるほど同じ値になるとしても、それらは異なる使い方をされなければいけない。
などと言うと、単なるトンデモさんになってしまう。
❌定義の違いは規範の違いから来ている。違いを無視できるほど同じ値になるとしても、それらは異なる使い方をされなければいけない。
などと言うと、単なるトンデモさんになってしまう。
#数楽 統計学の勉強と無関係に、弧度法による角度の定義とtanの定義まで戻れば、直線 y = ax とx軸で挟まれた部分の角度が
θ = arc tan a = ∫₀ᵃ dt/(1 + t²)
になることが直接的に導けることを確認すると、高校で習ったことの再構成ができてうれしいかも。続く
genkuroki.github.io/documents/High…
θ = arc tan a = ∫₀ᵃ dt/(1 + t²)
になることが直接的に導けることを確認すると、高校で習ったことの再構成ができてうれしいかも。続く
genkuroki.github.io/documents/High…



#数楽 x²+y²=1の右半分とy=txの交点は
(x(t), y(t)) = (1/√(1+t²), t/√(1+t²))
になります。これの軌跡のt=0からt=aまでの長さが弧度法の意味での角度θの定義なので、
θ = arc tan a = ∫₀ᵃ √(x'(t)²+y'(t)²) dt
です。ここでarc tanは角度θをaに対応させる函数tanの逆函数。続く
(x(t), y(t)) = (1/√(1+t²), t/√(1+t²))
になります。これの軌跡のt=0からt=aまでの長さが弧度法の意味での角度θの定義なので、
θ = arc tan a = ∫₀ᵃ √(x'(t)²+y'(t)²) dt
です。ここでarc tanは角度θをaに対応させる函数tanの逆函数。続く
#数楽 ここまで、高校の数学の教科書に書いてあることしか使っていないことに注意。図を自分で描けば分かり易い。
上の場合にちょっと計算すると
√(x'(t)²+y'(t)²) = 1/(1+t²).
これが arc tan t の導函数であることは、角度とtanの高校数学の教科書における定義からほぼ直接的に導かれる。
上の場合にちょっと計算すると
√(x'(t)²+y'(t)²) = 1/(1+t²).
これが arc tan t の導函数であることは、角度とtanの高校数学の教科書における定義からほぼ直接的に導かれる。
#統計 数学的に曖昧で厳密でない書き方への不満はよく見ますが、読者が数学の専門家であれば自力で議論を再構成できるはずなので、解説を各人はそういう人達相手に厳密に書く必要はないと思います。
定義も設定も曖昧で良い。
自分で定義してくれで問題ない。
定義も設定も曖昧で良い。
自分で定義してくれで問題ない。
#統計 数学がらみに話題では、各人は自分の好みに合わせて、議論全体を丸ごと再構成しようとするのが普通だと思います。
少なくとも、私が学部制時代にはそういうものだと習った。
あと、私が世話になったある先生は、数学は既存の定義から出発するわけではないというようなことも言っていました。
少なくとも、私が学部制時代にはそういうものだと習った。
あと、私が世話になったある先生は、数学は既存の定義から出発するわけではないというようなことも言っていました。
#数楽 個人的な体験談
解析力学→正準量子化
量子力学→古典極限
について、ツイッター上で物理学的な議論になっているように見えますが、私は物理と無関係に数学として面白ければよい(面白くなければいけない)という立場なので、物理学的な議論とは別の話をしたいと思います。続く
解析力学→正準量子化
量子力学→古典極限
について、ツイッター上で物理学的な議論になっているように見えますが、私は物理と無関係に数学として面白ければよい(面白くなければいけない)という立場なので、物理学的な議論とは別の話をしたいと思います。続く
#数楽 私はずっと(佐藤幹夫の意味での)τ函数の量子化をどのようにすればよいかについて考えていました。
ソリトン系は無限自由度系なので大変過ぎるので、その相似簡約として出て来るパンルヴェ系(所謂パンルヴェ方程式達の大幅な一般化)の"τ"の量子版の構成について考えることにしました。続く
ソリトン系は無限自由度系なので大変過ぎるので、その相似簡約として出て来るパンルヴェ系(所謂パンルヴェ方程式達の大幅な一般化)の"τ"の量子版の構成について考えることにしました。続く
#数楽 パンルヴェ系はLax形式ではモノドロミー保存系とみなせ、モノドロミー保存系は2次元量子共形場理論の共形ブロックの理論の古典極限とみなせ、私は共形ブロックの数学的理論の専門家だったので、自分にとって情報量の大きそうな部分を攻めるとよいと思いました。続く
#数楽
∫ xⁿ eᶜˣ dx 型の不定積分は本質的に
不完全ガンマ函数
と呼ばれる基本特殊函数(統計学などで使用される)になっていることを、高校生に数学を教える人達には知っておいて欲しいと思いました。
γ(s, x) = ∫_0^x tˢ⁻¹ e⁻ᵗ dt
ja.wikipedia.org/wiki/%E4%B8%8D…
∫ xⁿ eᶜˣ dx 型の不定積分は本質的に
不完全ガンマ函数
と呼ばれる基本特殊函数(統計学などで使用される)になっていることを、高校生に数学を教える人達には知っておいて欲しいと思いました。
γ(s, x) = ∫_0^x tˢ⁻¹ e⁻ᵗ dt
ja.wikipedia.org/wiki/%E4%B8%8D…
#数楽 関連スレッド
高校数学IIIの教科書に出て来る断片的な計算例の多くが、実戦的な応用で必要な数学を理解するために必要な具体的な計算例にもなっています。
天下り的に何の価値があるか不明の計算をやらされるのではない方が勉強し易く感じる高校生は結構多いのではないかと思います。
高校数学IIIの教科書に出て来る断片的な計算例の多くが、実戦的な応用で必要な数学を理解するために必要な具体的な計算例にもなっています。
天下り的に何の価値があるか不明の計算をやらされるのではない方が勉強し易く感じる高校生は結構多いのではないかと思います。
#数楽
∫_a^b (x - a)^A (b - a)^B dx
の形の定積分は本質的にベータ函数
B(p, q) = ∫_0^1 t^{p-1} (1 - t)^{q-1} dt
です。さらに t = (cos θ)² とおけば
∫_0^{π/2) (cos θ)^C (sin θ)^D dθ
も本質的にベータ函数であることが分かります。
∫_a^b (x - a)^A (b - a)^B dx
の形の定積分は本質的にベータ函数
B(p, q) = ∫_0^1 t^{p-1} (1 - t)^{q-1} dt
です。さらに t = (cos θ)² とおけば
∫_0^{π/2) (cos θ)^C (sin θ)^D dθ
も本質的にベータ函数であることが分かります。
#Julia言語 『数値計算の常識』という有名な本があって第5章のタイトルが「逆行列よさようなら」です。
Juliaでは計画行列Xによるバックスラッシュ演算
β̂ = X \ y
の一発で最小二乗法も計算できます。
github.com/genkuroki/publ…
Juliaでは計画行列Xによるバックスラッシュ演算
β̂ = X \ y
の一発で最小二乗法も計算できます。
github.com/genkuroki/publ…

#数楽 Xが縦長の行列で、β, y が縦ベクトルのときの、βの成分に関する連立一次方程式
Xβ = y
は一般に解を持たないのですが、Xβとyのユークリッド距離を最小にするようなβをβ̂と書いて、「解」とみなすのが最小二乗法の考え方です。その「解」を
β̂ = X \ y
と書くことは記号法的に自然です。
Xβ = y
は一般に解を持たないのですが、Xβとyのユークリッド距離を最小にするようなβをβ̂と書いて、「解」とみなすのが最小二乗法の考え方です。その「解」を
β̂ = X \ y
と書くことは記号法的に自然です。
#Julia言語 Juliaがバックスラッシュ二項演算子で最小二乗法も可能にしていることの背景には以上のような数学が隠れています。
#統計 #数楽 この短い動画も非常にためになるし楽しめる。
「変分ベイズ」「変分推論」のように呼ばれる方法は、計算が大変な真の分布φ(w)を特別な形の分布ψ(w)でφ(w)から最も出て来やすいもので近似する方法。続く
「変分ベイズ」「変分推論」のように呼ばれる方法は、計算が大変な真の分布φ(w)を特別な形の分布ψ(w)でφ(w)から最も出て来やすいもので近似する方法。続く
#統計 Kullback-Leibler情報量 D(ψ||φ) は、Sanovの定理より、「分布φのサンプルの分布として分布ψに近いものの出て来やすさ」を意味する。
もしも分布ψの台が分布φの台よりも真に大きいならば、そのはみ出した部分の値はφから出て来ないので、D(ψ||φ) = ∞ となる。
続く
もしも分布ψの台が分布φの台よりも真に大きいならば、そのはみ出した部分の値はφから出て来ないので、D(ψ||φ) = ∞ となる。
続く
#統計 D(ψ||φ) < ∞ ならばψの台はφの台に含まれる。
固定されたφに対して、特別な形のψを動かして、D(ψ||φ) を最小化すると(変分推論!)、分布ψは分布φよりも狭い部分に集中した感じの分布になり易い。
以下のリンク先の場合には実際に概ねそうなっているように見える。
固定されたφに対して、特別な形のψを動かして、D(ψ||φ) を最小化すると(変分推論!)、分布ψは分布φよりも狭い部分に集中した感じの分布になり易い。
以下のリンク先の場合には実際に概ねそうなっているように見える。
#Julia言語 1万人に一人あたり100万円配って、その後ランダムに誰かから1万円を取り上げて(破産していたら取るのを諦める)、別の誰かに配ることを繰り返したときの、保有金額の分布の推移のアニメーション。
分布の収束先は不平等な指数分布。
これは「税額一定」の場合。
github.com/genkuroki/publ…
分布の収束先は不平等な指数分布。
これは「税額一定」の場合。
github.com/genkuroki/publ…
#Julia言語 不平等な指数分布になった後に、今度はランダムに誰かを選んで保有金額の5%の税金を徴収して別の誰かに配ることを繰り返すとこうなる。
分布の収束先はかなり平等的なガンマ分布。
証明は知らない。誰か教えて!(笑)
(((わざと真剣に考えていない)))
github.com/genkuroki/publ…
分布の収束先はかなり平等的なガンマ分布。
証明は知らない。誰か教えて!(笑)
(((わざと真剣に考えていない)))
github.com/genkuroki/publ…
#Julia言語 ここからが真に面白い話になる。
さて、ついさっき税額ではなく、税率を一定にしたランダムな富の分配で平等に近付けることができることを紹介した。
税率は5%だった。
問題:税率を50%に上げるとさらに平等になるか?
さて、ついさっき税額ではなく、税率を一定にしたランダムな富の分配で平等に近付けることができることを紹介した。
税率は5%だった。
問題:税率を50%に上げるとさらに平等になるか?
#数楽 大学1年生向けの線形代数の講義では、与えられた a_{ij}とb_iが定めるx_j達に関する連立一次方程式
a_{11}x_1 + … + a_{1n}x_n = b_1
………
a_{m1}x_1 + … + a_{mn}x_n = b_m
をa_{ij}, b_iに関する場合分けで解く話をやったりします。
ax=bはこれのm=n=1の特別な場合。
a_{11}x_1 + … + a_{1n}x_n = b_1
………
a_{m1}x_1 + … + a_{mn}x_n = b_m
をa_{ij}, b_iに関する場合分けで解く話をやったりします。
ax=bはこれのm=n=1の特別な場合。
#数楽 そのm=n=1の特別な場合の方程式
ax=b
は以下の3種に分けされる。
(0) a≠0の場合の ax=b
(1) a=0, b≠0の場合の 0=b
(2) a=0, b=0の場合の 0=0
(0), (2)の場合に解空間の次元はそれぞれ0, 1になり、(1)の場合に解空間は空集合になる。
これの一般化をやる。
ax=b
は以下の3種に分けされる。
(0) a≠0の場合の ax=b
(1) a=0, b≠0の場合の 0=b
(2) a=0, b=0の場合の 0=0
(0), (2)の場合に解空間の次元はそれぞれ0, 1になり、(1)の場合に解空間は空集合になる。
これの一般化をやる。
#数楽 m=n=2の場合の方程式の中には
x + ay = p
0x + 0y = q
のようなものも含まれる、q≠0の場合は解なしになり、q=0の場合には
x = p - ay
yは任意
の形ですべての解を表せる。
こういう講義をしている人達はそれなりにいるはず。
x + ay = p
0x + 0y = q
のようなものも含まれる、q≠0の場合は解なしになり、q=0の場合には
x = p - ay
yは任意
の形ですべての解を表せる。
こういう講義をしている人達はそれなりにいるはず。
#数楽 #Julia言語 新学期の講義のためのC^∞級函数の例の準備で、
f(x) = if x > 0 exp(-1/x) else 0 end
のような函数を扱っている人もいるはず。
現時点で最もよく使われているFloat64型の浮動小数点数の精度では
exp(-1/0.001) == 0
は true になります❗️(笑)
こういうのもネタになりそう。
f(x) = if x > 0 exp(-1/x) else 0 end
のような函数を扱っている人もいるはず。
現時点で最もよく使われているFloat64型の浮動小数点数の精度では
exp(-1/0.001) == 0
は true になります❗️(笑)
こういうのもネタになりそう。

#Julia言語
f(x) = if x > 0 exp(-1/x) else zero(x) end
using ForwardDiff
f′(x) = ForwardDiff.derivative(f, x)
のグラフ。最近では自動微分が普通で、数値的に微分を求めるときにも、導函数の公式を入力せずに、「正確に」かつ「効率良く」微係数を計算できます。
gist.github.com/genkuroki/ce92…
f(x) = if x > 0 exp(-1/x) else zero(x) end
using ForwardDiff
f′(x) = ForwardDiff.derivative(f, x)
のグラフ。最近では自動微分が普通で、数値的に微分を求めるときにも、導函数の公式を入力せずに、「正確に」かつ「効率良く」微係数を計算できます。
gist.github.com/genkuroki/ce92…

#Julia言語
f(x) = if x > 0 exp(-1/x) else zero(x) end
g(x) = if x > 0 exp(-1/x)/x^2 else zero(x) end
using ForwardDiff
f′(x) = ForwardDiff.derivative(f, x)
のgとf′の値と計算速度の比較。
導函数の公式を私が入力したgとForward.derivativeで自動微分しているf′で計算速度はほぼ同じ。
f(x) = if x > 0 exp(-1/x) else zero(x) end
g(x) = if x > 0 exp(-1/x)/x^2 else zero(x) end
using ForwardDiff
f′(x) = ForwardDiff.derivative(f, x)
のgとf′の値と計算速度の比較。
導函数の公式を私が入力したgとForward.derivativeで自動微分しているf′で計算速度はほぼ同じ。

#数楽 私の線形代数のノート(問題集の形式、多分まだ公開していない)から関連する部分のスクショを貼り付けます。
多項式のユークリッドの互助法(最大公約多項式を多項式係数一次結合で作れること)と有理函数の部分分数展開とLagrange(-Sylvester)補間公式は本質的に同じ話題。
1/8~4/8
多項式のユークリッドの互助法(最大公約多項式を多項式係数一次結合で作れること)と有理函数の部分分数展開とLagrange(-Sylvester)補間公式は本質的に同じ話題。
1/8~4/8




#数楽 多項式のユークリッドの互助法(最大公約多項式を多項式係数一次結合で作れること)と有理函数の部分分数展開とLagrange(-Sylvester)補間公式は本質的に同じ話題であることの続き。
5/8~8/8
5/8~8/8




#数楽 例:互いに異なるα_1,…,α_n∈ℂについて、f(x)=(x-α_1)…(x-α_n)とおき、p(x)をn-1次以下の複素多項式とするとき、
p(x)/f(x)=a_1/(x-α_1)+…+a_n/(x-α_n) in ℂ(x)
を満たすa_i∈ℂ達は、両辺にf(x)をかけて、xにα_iを代入することを経由して、
a_i=p(α_i)/f'(α_i)
で求められる(一意的)。
p(x)/f(x)=a_1/(x-α_1)+…+a_n/(x-α_n) in ℂ(x)
を満たすa_i∈ℂ達は、両辺にf(x)をかけて、xにα_iを代入することを経由して、
a_i=p(α_i)/f'(α_i)
で求められる(一意的)。
#数楽
多項式f∈ℝ[x]に「a∈ℝをf(a)∈ℝを対応させる函数」を対応させる写像は単射なので、多項式fとそれに対応する実数の函数を区別しなくも大丈夫。(無限体でもOK)
有限体F上の多項式g∈F[x]に「a∈Fをg(a)∈Fを対応させる函数」を対応させる写像は単射でないので、それらを同一視できない。
多項式f∈ℝ[x]に「a∈ℝをf(a)∈ℝを対応させる函数」を対応させる写像は単射なので、多項式fとそれに対応する実数の函数を区別しなくも大丈夫。(無限体でもOK)
有限体F上の多項式g∈F[x]に「a∈Fをg(a)∈Fを対応させる函数」を対応させる写像は単射でないので、それらを同一視できない。
#数楽 例えば二元体𝔽₂={0,1} (1+1=0)について、𝔽₂上の多項式としてxとx²は異なるが、𝔽₂上の函数としてはどちらも恒等写像になって等しくなってしまう。
xとx²を𝔽₂の2次拡大𝔽₄=𝔽₂[α] (α²=α+1)上の函数とみなしたものは互いに異なる。
こういう具体例がノータイムで出て来ることが大事。
xとx²を𝔽₂の2次拡大𝔽₄=𝔽₂[α] (α²=α+1)上の函数とみなしたものは互いに異なる。
こういう具体例がノータイムで出て来ることが大事。
#数楽 面倒なのは有理函数(多項式環の分数体の要素)に対応する「函数」の場合。
有理函数ごとに定義域も変わるので、異なる定義域を持つ函数達を同時に扱うための「処理」が必要になる。(これには複数の処方箋がある。)
結果的に、無限体の場合には、有理函数と対応する「函数」は同一視可能になる。
有理函数ごとに定義域も変わるので、異なる定義域を持つ函数達を同時に扱うための「処理」が必要になる。(これには複数の処方箋がある。)
結果的に、無限体の場合には、有理函数と対応する「函数」は同一視可能になる。
#Julia言語 (1-2^(1-s))ζ(s) は交代級数になりEuler変換が使える。Euler変換を使えば数十項でFloat64の精度を使い切った計算が可能。
①オイラー変換のウェイトのグラフ
②64項の和の計算結果
③正確な値との相対誤差の常用対数、横軸Lは項数
Euler変換はかなり強力。
nbviewer.jupyter.org/gist/genkuroki…
①オイラー変換のウェイトのグラフ
②64項の和の計算結果
③正確な値との相対誤差の常用対数、横軸Lは項数
Euler変換はかなり強力。
nbviewer.jupyter.org/gist/genkuroki…
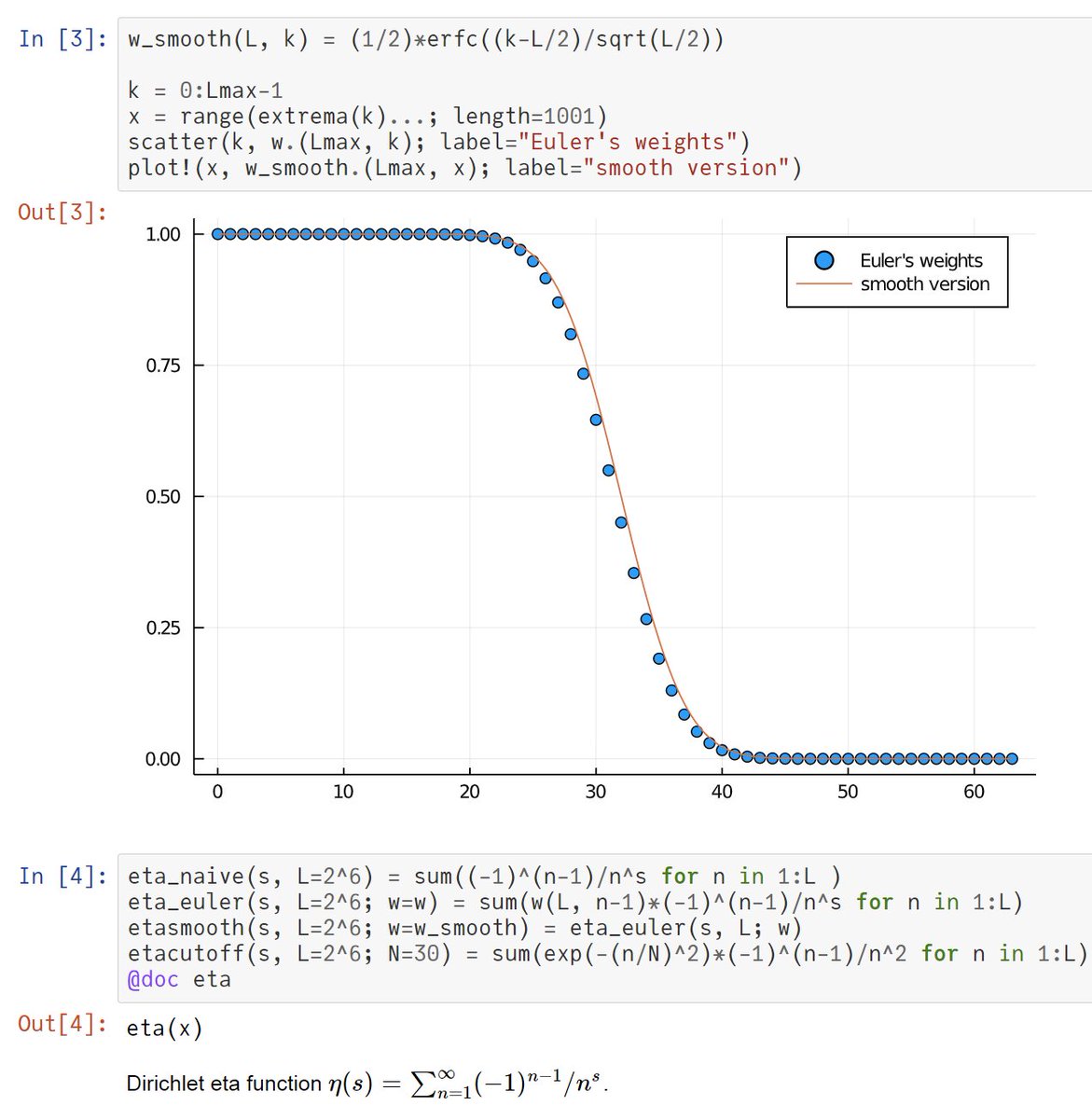
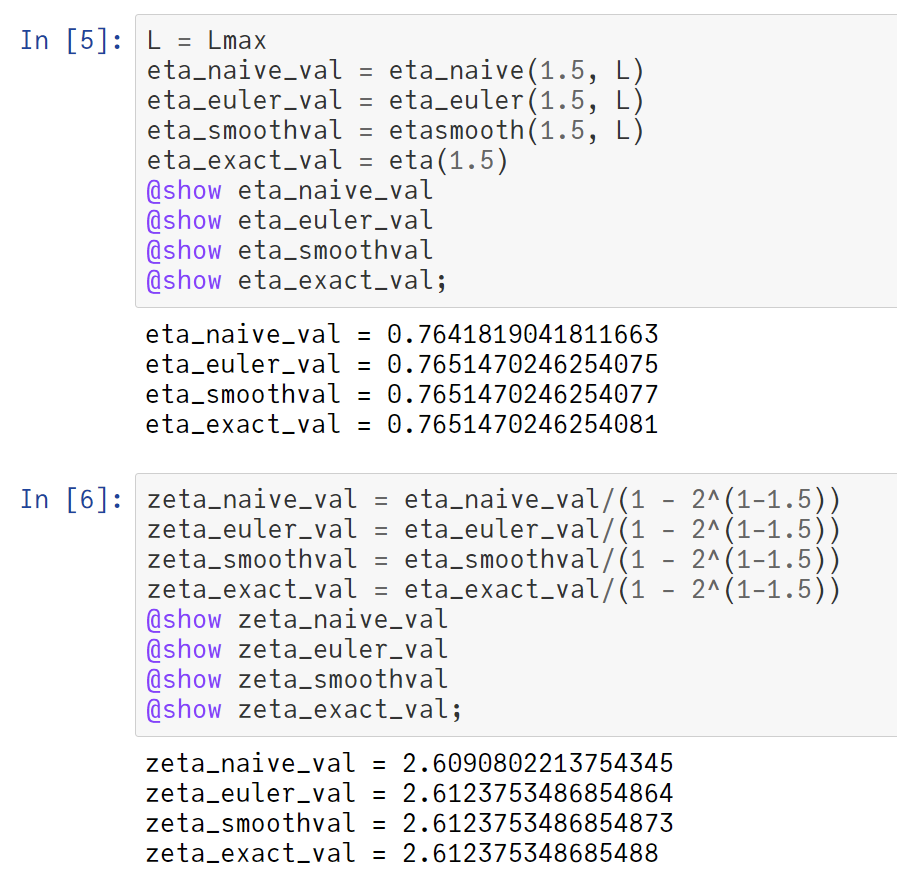

#Julia言語 Euler変換とは、1つ前のツイートの1つ目の添付画像で示された謎のウェイト w^{(L)}_k をかけて (-1)^k a_k を k=0からL-1まで足し上げると、(-1)^k a_k のk=0から∞までの和の良い近似になるという魔法のような話。
1つ前のツイートのLは2^6=64.
1つ前のツイートのLは2^6=64.
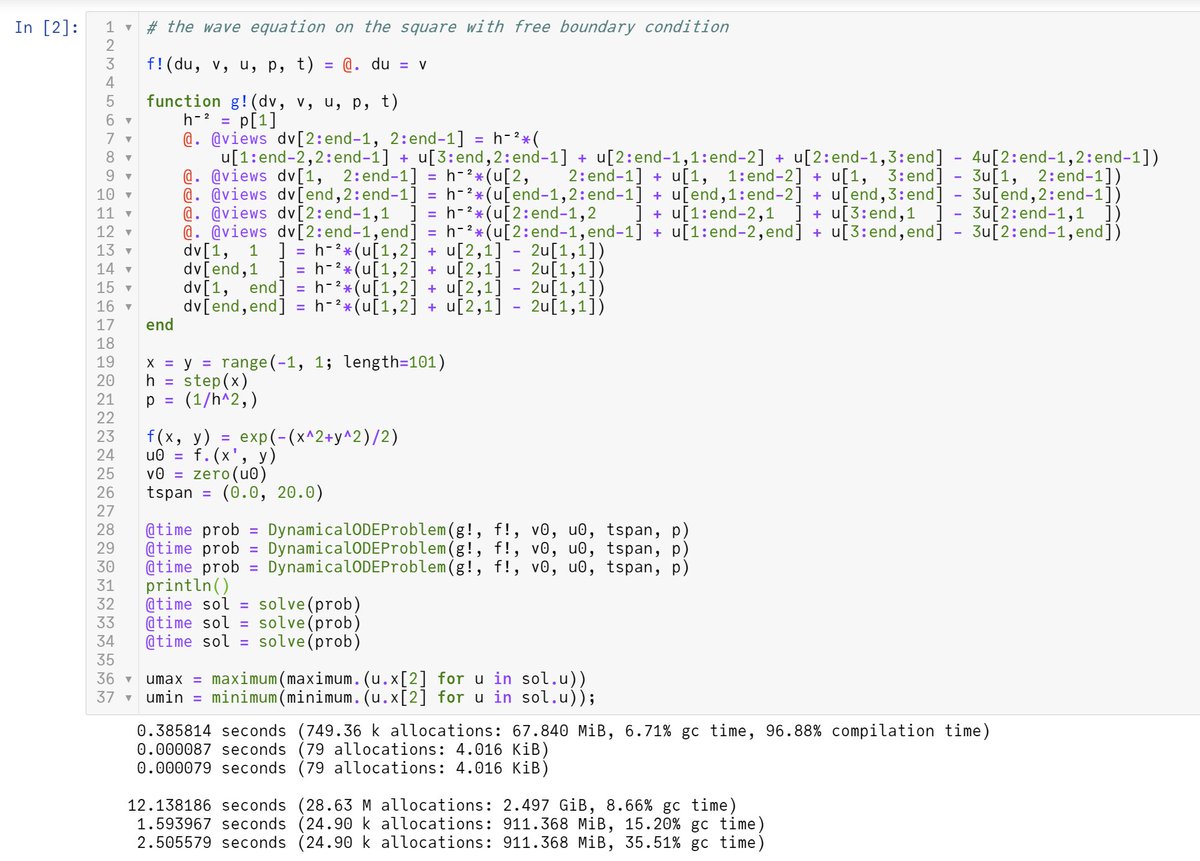
#Julia言語 10行では無理なやつ
正方形上の自由境界条件の波動方程式の離散化をDifferentialEquations.jlで数値的に解いて動画を作ってみた↓
nbviewer.jupyter.org/gist/genkuroki…
これを作るために必要な行数は40行程度でした。
正方形上の自由境界条件の波動方程式の離散化をDifferentialEquations.jlで数値的に解いて動画を作ってみた↓
nbviewer.jupyter.org/gist/genkuroki…
これを作るために必要な行数は40行程度でした。
#Julia言語 約1万個の質点がバネで繋がっている状況を記述する常微分方程式 prob を DifferentialEquations.jl に sol = solve(prob) の形式で数値的に解かせています。自分でソルバを書かなくて良いとかなり楽です。
nbviewer.jupyter.org/gist/genkuroki…
nbviewer.jupyter.org/gist/genkuroki…
#Julia言語 正方形ではなく、正五角形上の自由境界条件のもとでの波動方程式の数値解。
これもDifferentialEquations.jlを使っています。
コードの効率はそうよくないのですが、シンプル。
これもDifferentialEquations.jlを使っています。
コードの効率はそうよくないのですが、シンプル。


#Julia言語
[f(x) for x in X if cond(x)] では、実際に条件を満たすすべてのxについてf(x)を計算して、Array(配列)ができ、その分だけのメモリ割当が生じる。
(f(x) for x in X if cond(x)) は単に条件を満たすf(x)達の生成の仕方を記述したオブジェクトになり、メモリをほとんど消費しない。
[f(x) for x in X if cond(x)] では、実際に条件を満たすすべてのxについてf(x)を計算して、Array(配列)ができ、その分だけのメモリ割当が生じる。
(f(x) for x in X if cond(x)) は単に条件を満たすf(x)達の生成の仕方を記述したオブジェクトになり、メモリをほとんど消費しない。
#Julia言語
sum([f(x) for x in X if cond(x)]) では [f(x) for x in X if cond(x)] の分の配列が作られて、その分だけのメモリ割当が生じる。
一方、sum(f(x) for x in X if cond(x)) ではそのような無駄なメモリ割当は発生せず、条件を満たす各々のxについてf(x)が計算され、即足し上げられる。
sum([f(x) for x in X if cond(x)]) では [f(x) for x in X if cond(x)] の分の配列が作られて、その分だけのメモリ割当が生じる。
一方、sum(f(x) for x in X if cond(x)) ではそのような無駄なメモリ割当は発生せず、条件を満たす各々のxについてf(x)が計算され、即足し上げられる。
#Julia言語 これらの違いはループの内側でそのような和を計算するときにはパフォーマンスに決定的な影響を与える。
条件無しに単に x∈X について和を計算したい場合には
sum(f, X)
とも書ける。誤差の観点からはこちらの方が好ましい(Float32で計算する場合は特にそうである)。
条件無しに単に x∈X について和を計算したい場合には
sum(f, X)
とも書ける。誤差の観点からはこちらの方が好ましい(Float32で計算する場合は特にそうである)。
