Discover and read the best of Twitter Threads about #icml
Most recents (6)

One of the biggest criticisms of the field of post hoc #XAI is that each method "does its own thing", it is unclear how these methods relate to each other & which methods are effective under what conditions. Our #NeurIPS2022 paper provides (some) answers to these questions. [1/N] 

In our #NeurIPS2022 paper, we unify eight different state-of-the-art local post hoc explanation methods, and show that they are all performing local linear approximations of the underlying models, albeit with different loss functions and notions of local neighborhoods. [2/N]
By doing so, we are able to explain the similarities & differences between these methods. These methods are similar in the sense that they all perform local linear approximations of models, but they differ considerably in "how" they perform these approximations [3/N]

I am excited to announce that I have successfully defended my PhD and have published my PhD thesis on “Learning with Differentiable Algorithms”. 🎉
arxiv.org/abs/2209.00616
In the thesis, I explore how we can make discrete structures like algorithms differentiable. [1/13]
arxiv.org/abs/2209.00616
In the thesis, I explore how we can make discrete structures like algorithms differentiable. [1/13]

By making algorithms differentiable, we can integrate them end-to-end into neural network machine learning architectures. For example, we can continuously relax sorting (github.com/Felix-Petersen…) for learning to rank. [2/13]

At #ICML today: why is generalization so hard in value-based RL? We show that the TD targets used in value-based RL evolve in a structured way, and that this encourages neural networks to ‘memorize’ the value function.
📺 icml.cc/virtual/2022/p…
📜 proceedings.mlr.press/v162/lyle22a.h…
📺 icml.cc/virtual/2022/p…
📜 proceedings.mlr.press/v162/lyle22a.h…

TL;DR: reward functions in most benchmark MDPs don’t look much like the actual value function — in particular, the smooth* components of the value function tend to be missing!
*smooth ~= doesn't change much between adjacent states, e.g. a constant function.
*smooth ~= doesn't change much between adjacent states, e.g. a constant function.
Early TD targets tend to resemble the reward, and it can take many updates for reward information to propagate (see attached figure). Meanwhile, the deep RL agent is training its neural network to fit these non-smooth prediction targets, building in a bias towards *memorization*.


1/n This #ICML #ICCV plagiarism issue reminds me of an uncomfortable experience of mine. I believe that the code of my ICLR 2020 paper Program Guided Agent (openreview.net/forum?id=BkxUv…), which is not publicly released

2/n and was only submitted to NeurIPS 2019 and ICLR 2020 for reviewing purposes only, was used to produce results and visualizations of another paper without asking for my permission.
3/n When I first saw that paper, I did not even know that crosses a line let alone doing something about it, but I definitely felt really uncomfortable. It has been a while and I still have not heard from the authors.

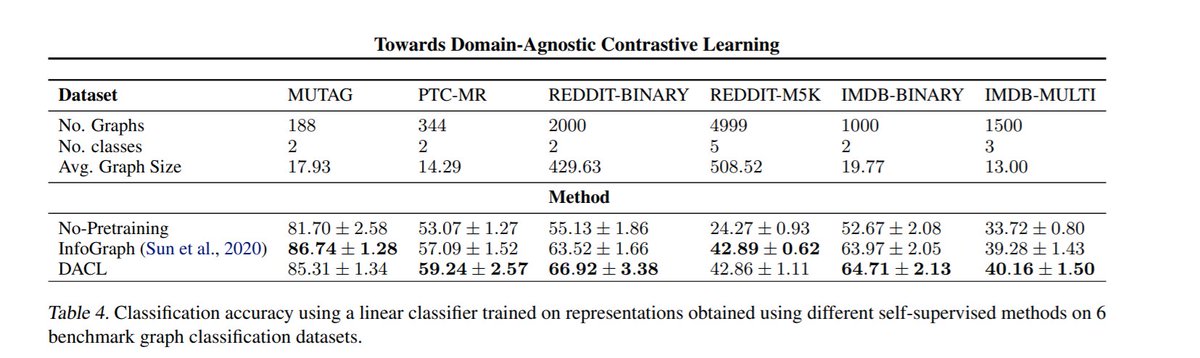
*Towards Domain-Agnostic Contrastive Learning*
#ICML 2021 by @vikasverma1077 @lmthang Kawaguchi @hieupham789 @quocleix
Here's an interesting question: can we do self-supervised learning if we know *nothing* about the domain we are operating on?
/n
#ICML 2021 by @vikasverma1077 @lmthang Kawaguchi @hieupham789 @quocleix
Here's an interesting question: can we do self-supervised learning if we know *nothing* about the domain we are operating on?
/n

The solution they propose is fascinatingly simple: create a positive pair by moving a short distance towards another point (mixup).
The intuition being that this captures the manifold along which the data resides.
For graphs/sequences, do mixup on a fixed-length embedding.
/n
The intuition being that this captures the manifold along which the data resides.
For graphs/sequences, do mixup on a fixed-length embedding.
/n

The theoretical analysis shows that this acts similarly to a form of regularization, and the experiments are quite impressive.
Paper: arxiv.org/abs/2011.04419
Paper: arxiv.org/abs/2011.04419

[Thread on reviewing for #MachineLearning confs, after receiving the reminder from @iclr_conf (#ICLR)]
Posting response to @iclr_conf's request for reviewing here in the hope (again) that we can change the reviewing structure of ML conferences to promote better science.
1/
Posting response to @iclr_conf's request for reviewing here in the hope (again) that we can change the reviewing structure of ML conferences to promote better science.
1/
Whether it is @NeurIPSConf (#neurips), @icmlconf (#icml), @iclr_conf (#ICLR), @RealAAAI (#aaai) or any other crowded ML conf, the reviewing structure that involves a fixed review window, multiple assigned papers, unlimited supplemental material, etc., promotes the following:
2/
2/
a) Reviews are handed off to inexperienced reviewers, directly or indirectly, due to the time pressure involved.
b) It leaves reviewers with little time to digest the technical details, leading them to potentially miss subtle errors or undervalue the merits of the work.
3/
b) It leaves reviewers with little time to digest the technical details, leading them to potentially miss subtle errors or undervalue the merits of the work.
3/
