Discover and read the best of Twitter Threads about #NeurIPS
Most recents (14)

This may revolutionize data science: we introduce TabPFN, a new tabular data classification method that takes 1 second & yields SOTA performance (better than hyperparameter-optimized gradient boosting in 1h). Current limits: up to 1k data points, 100 features, 10 classes. 🧵1/6 
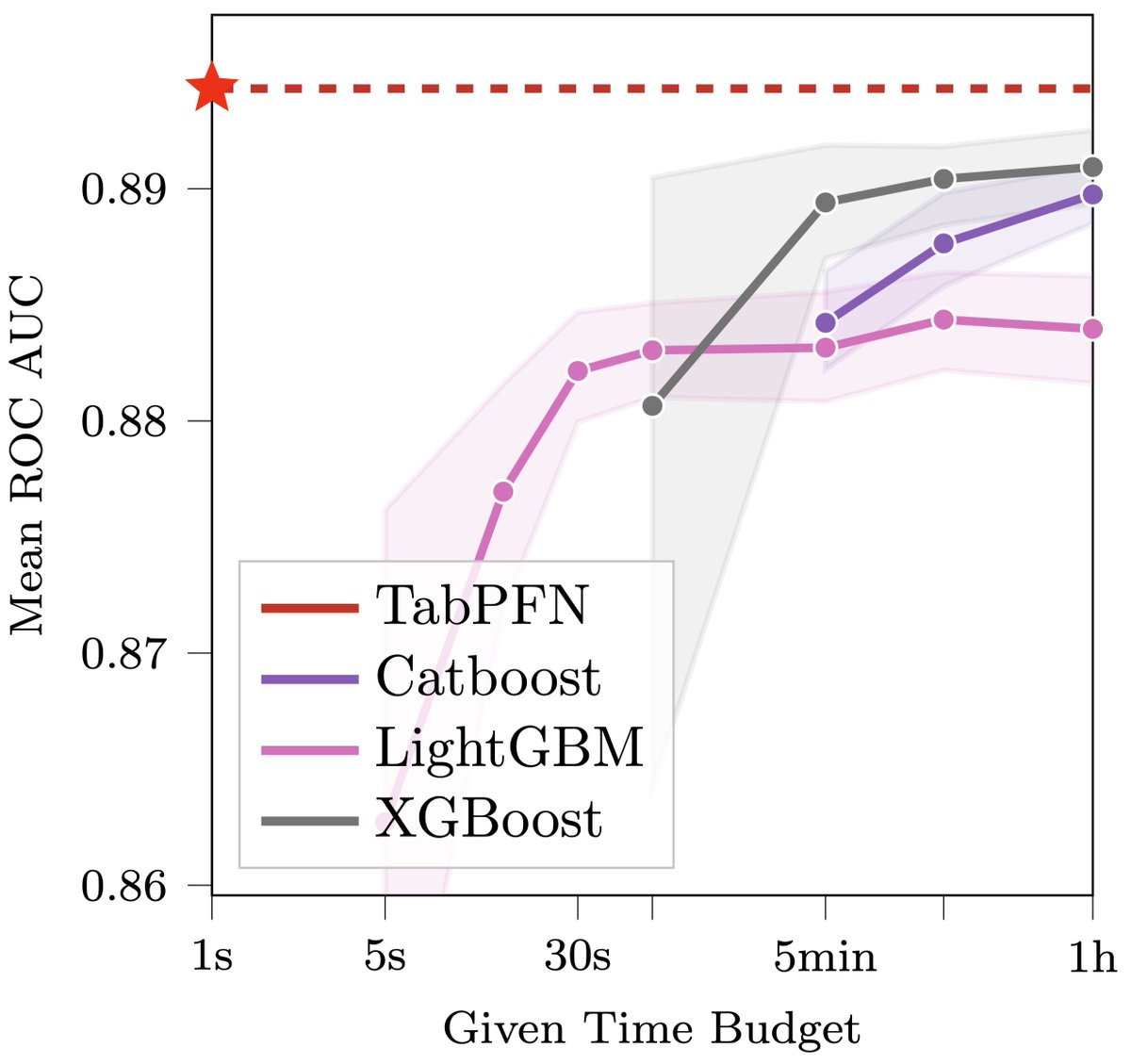
TabPFN is radically different from previous ML methods. It is meta-learned to approximate Bayesian inference with a prior based on principles of causality and simplicity. Here‘s a qualitative comparison to some sklearn classifiers, showing very smooth uncertainty estimates. 2/6

TabPFN happens to be a transformer, but this is not your usual trees vs nets battle. Given a new data set, there is no costly gradient-based training. Rather, it’s a single forward pass of a fixed network: you feed in (Xtrain, ytrain, Xtest); the network outputs p(y_test). 3/6

I am excited to announce that I have successfully defended my PhD and have published my PhD thesis on “Learning with Differentiable Algorithms”. 🎉
arxiv.org/abs/2209.00616
In the thesis, I explore how we can make discrete structures like algorithms differentiable. [1/13]
arxiv.org/abs/2209.00616
In the thesis, I explore how we can make discrete structures like algorithms differentiable. [1/13]

By making algorithms differentiable, we can integrate them end-to-end into neural network machine learning architectures. For example, we can continuously relax sorting (github.com/Felix-Petersen…) for learning to rank. [2/13]

*Generative Flow Networks*
A new method to sample structured objects (eg, graphs, sets) with a formulation inspired to the state space of reinforcement learning.
I have collected a few key ideas and pointers below if you are interested. 👀
1/n
👇
A new method to sample structured objects (eg, graphs, sets) with a formulation inspired to the state space of reinforcement learning.
I have collected a few key ideas and pointers below if you are interested. 👀
1/n
👇

*Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation*
#NeurIPS paper by @folinoid @JainMoksh et al. introducing the method.
The task is learning to sample objects that can be built 1 piece at a time ("lego-style").
2/n
arxiv.org/abs/2106.04399
#NeurIPS paper by @folinoid @JainMoksh et al. introducing the method.
The task is learning to sample objects that can be built 1 piece at a time ("lego-style").
2/n
arxiv.org/abs/2106.04399

For example: a complex molecule can be built by adding one atom at a time; an image by colouring one pixel per iteration; etc.
If you formalize this process, you get a state space where you move from an "empty" object to a complete object by traversing a graph.
3/n
If you formalize this process, you get a state space where you move from an "empty" object to a complete object by traversing a graph.
3/n


Tomorrow at #NeurIPS we’re launching Nightingale Open Science, a computing platform empowering researchers to access massive new health imaging datasets
We hope Nightingale will help solve some of the biggest medical problems of our time
A 🧵on how to get involved (1/16)
We hope Nightingale will help solve some of the biggest medical problems of our time
A 🧵on how to get involved (1/16)
Launch workshop features product demo + panels w/ top minds in CS, tech, medicine
@EricSchmidt @BarzilayRegina @JenniferChayes @AneeshChopra @EricTopol @MarzyehGhassemi @kevin_volpp @judywawira @mattlungrenMD @2plus2make5 @ensoesie
nightingalescience.org/conferences-20… (2/16)
@EricSchmidt @BarzilayRegina @JenniferChayes @AneeshChopra @EricTopol @MarzyehGhassemi @kevin_volpp @judywawira @mattlungrenMD @2plus2make5 @ensoesie
nightingalescience.org/conferences-20… (2/16)
Just as ImageNet jump-started ‘machine vision’, we want to help build a new field of ‘computational medicine’
Nightingale’s mission is to bring together researchers, incl. computer scientists and clinicians, around questions pushing the boundaries of medical science (3/16)
Nightingale’s mission is to bring together researchers, incl. computer scientists and clinicians, around questions pushing the boundaries of medical science (3/16)
Tomorrow at #NeurIPS we’re launching Nightingale Open Science, a computing platform giving researchers access to massive new health imaging datasets
We hope Nightingale will help solve some of the biggest medical problems of our time
What makes these datasets special? (1/8)
We hope Nightingale will help solve some of the biggest medical problems of our time
What makes these datasets special? (1/8)
Our datasets are curated around medical mysteries—heart attack, cancer metastasis, cardiac arrest, bone aging, Covid-19—where machine learning can be transformative
We designed these datasets with four key principles in mind: (2/8)
We designed these datasets with four key principles in mind: (2/8)
1. Each dataset begins with a large collection of medical images: x-rays, ECG waveforms, digital pathology (and more to come)
These rich, high-dimensional signals are too complex for humans to see or fully process—so machine vision can add huge value (3/8)
These rich, high-dimensional signals are too complex for humans to see or fully process—so machine vision can add huge value (3/8)

Causal effect estimation is fundamental for decision-making in many domains, e.g., personalized medicine. Having access to observational data only, how can we infer causal effects of structured treatments, e.g., molecular graphs of drugs, images, texts, etc.? 1/4 #NeurIPS

We propose the generalized Robinson decomposition (GRD) for such treatments: it isolates the causal estimands (reducing regularization bias), allows one to plug in arbitrary models for learning, and possesses a quasi-oracle error bound under mild assumptions. 2/4
We implement an NN-based instance of GRD: Structured Intervention Networks. In experiments with molecular/small-world graphs, it outperforms prior approaches. There is plenty of future work to be done: datasets/applications, hidden confounding, consistency guarantees, ... 3/4

Hey computing academics! What are you favorite examples of ethical considerations/discussions in published papers? e.g. research ethics, broader impacts. Please share papers! I would love examples from a range of subfields. 🙏
Clarification: I’m not looking for papers ABOUT research ethics (though you’re welcome to share if you like :) ); I’m looking for papers that discuss ethical decisions or implications of the research they describe. e.g. a paragraph about ethics in the methods section!
I would actually especially love good examples of broader impacts statements in NeurIPS papers or similar! Help? 🙏 #neurips #NeurIPS2021

📢 In our #ACMMM21 paper, we highlight issues with training and evaluation of 𝗰𝗿𝗼𝘄𝗱 𝗰𝗼𝘂𝗻𝘁𝗶𝗻𝗴 deep networks. 🧵👇

For far too long, 𝗰𝗿𝗼𝘄𝗱 𝗰𝗼𝘂𝗻𝘁𝗶𝗻𝗴 works in #CVPR, #AAAI, #ICCV, #NeurIPS have reported only MAE, but not standard deviation.
Looking at MAE and standard deviation from MAE, a very grim picture emerges. E.g. Imagine a SOTA net with MAE 71.7 but deviation is a whopping 376.4 !




In typical space-cowboy style, @ylecun, donning no slides, but only a whiteboard on Zoom, explains how all the various self-supervised models can be unified under an Energy Based view. #NeurIPS #SSL workshop


Another long thread. Bear with me till the end please. These are my views, and not necessarily of those associated with me. Though those associated with me have been incredibly supportive. I thank everyone who messaged me. I thank @databoydg for inspiring me to say this next. 1/n
First, @databoydg: I hope this makes justice to what you've tried to teach me. I'm sorry if I'm a slow student. In this second part of the story, I'm a privileged academic having a drink in Montreal after a #neurips conference with @sindero 2/n
Simon says to me: I feel we need to do something about this (stark lack of minority representation in ML). We agree we'll do something about it, but it feels like we're at the bottom of Everest and have to climb it without any gear 3/n

Reliability is a key challenge in ML. There are now dozens of robust training methods and datasets - how do they compare?
We ran 200+ ImageNet models on 200+ test sets to find out.
modestyachts.github.io/imagenet-testb…
TDLR: Distribution shift is *really* hard, but common patterns emerge.
We ran 200+ ImageNet models on 200+ test sets to find out.
modestyachts.github.io/imagenet-testb…
TDLR: Distribution shift is *really* hard, but common patterns emerge.

To organize the 200 distribution shifts, we divide them into two categories: synthetic shifts and natural shifts.
Synthetic shifts are derived from existing images by perturbing them with noise, etc.
Natural shifts are new, unperturbed images from a different distribution.
Synthetic shifts are derived from existing images by perturbing them with noise, etc.
Natural shifts are new, unperturbed images from a different distribution.

At a high level, there has been good progress on the synthetic shifts (e.g., ImageNet-C or adversarial examples).
Natural distribution shifts (e.g., ImageNetV2 or ObjectNet), on the other hand, are still much harder.
Natural distribution shifts (e.g., ImageNetV2 or ObjectNet), on the other hand, are still much harder.

[Thread on reviewing for #MachineLearning confs, after receiving the reminder from @iclr_conf (#ICLR)]
Posting response to @iclr_conf's request for reviewing here in the hope (again) that we can change the reviewing structure of ML conferences to promote better science.
1/
Posting response to @iclr_conf's request for reviewing here in the hope (again) that we can change the reviewing structure of ML conferences to promote better science.
1/
Whether it is @NeurIPSConf (#neurips), @icmlconf (#icml), @iclr_conf (#ICLR), @RealAAAI (#aaai) or any other crowded ML conf, the reviewing structure that involves a fixed review window, multiple assigned papers, unlimited supplemental material, etc., promotes the following:
2/
2/
a) Reviews are handed off to inexperienced reviewers, directly or indirectly, due to the time pressure involved.
b) It leaves reviewers with little time to digest the technical details, leading them to potentially miss subtle errors or undervalue the merits of the work.
3/
b) It leaves reviewers with little time to digest the technical details, leading them to potentially miss subtle errors or undervalue the merits of the work.
3/

In case you missed our #neurips poster on MixMatch (arxiv.org/abs/1905.02249) today because you aren't in Vancouver or didn't survive the poster session stampede, here's the PDF: github.com/google-researc… and here's a transcript of what I said to everyone who came by: ⬇️ 1/11
The goal in semi-supervised learning (SSL) is to use unlabeled data to improve a model's performance. Many approaches do this by using the model to produce "label guesses" for unlabeled data, and then training the model to predict those guesses. 2/11
Two common ingredients for producing label guesses are consistency regularization ("When I perturb the input or model, the model's prediction shouldn't change.") and entropy minimization ("The model should output low-entropy/confident predictions on unlabeled data.") 3/11

1/7 Our new paper on adversarial attack detection and capsule networks with @sabour_sara and Geoff Hinton is out on arxiv today! arxiv.org/abs/1811.06969 it will be presented at the #NeurIPS Workshop on Security. Don't have time to read the paper? Read this thread instead! :)
2/7 The problem with adversarial examples is that they dont look like what they are classified as. Capsule networks output both a classification and a reconstruction of the input conditioned on the classification. A reconstruction of an adversarial looks different from the input

3/7 We can create a detection algorithm by defining a threshold for reconstruction error from a validation set, and flag inputs as adversarial if the reconstruction error exceeds this threshold.

