Discover and read the best of Twitter Threads about #Reproducibility
Most recents (24)

Today's Twitter threads (a Twitter thread).
Inside: Podcasting "Gig Work Is the Opposite of Steampunk"; and more!
Archived at: pluralistic.net/2023/03/19/lov…
#Pluralistic 1/
Inside: Podcasting "Gig Work Is the Opposite of Steampunk"; and more!
Archived at: pluralistic.net/2023/03/19/lov…
#Pluralistic 1/

Today (Mar 20), I'm doing a remote talk for the @Ostrom_Workshop's Beyond the Web Speaker Series
iu.zoom.us/meeting/regist…
On Weds (Mar 22), I'm doing a remote talk for the @IFTF's "Changing the Register" series:
iftf.zoom.us/webinar/regist… 2/
iu.zoom.us/meeting/regist…
On Weds (Mar 22), I'm doing a remote talk for the @IFTF's "Changing the Register" series:
iftf.zoom.us/webinar/regist… 2/
Podcasting "Gig Work Is the Opposite of Steampunk": Why today's Luddites should be smashing apps.
3/
3/


$PVCT Releases 2023 Stockholder Letter globenewswire.com/news-release/2… #rosebengal #rosebengalsodium
1/ $PVCT 2023 Shareholder Letter: (2) Design, prepare, and potentially commence a Phase 2/3 RCT of PV-10®+SOC checkpoint vs monotherapy SOC checkpoint ($MRK #keytruda, $BMY #opdivo) for 1st-line Stage III cutaneous melanoma. #rosebengal #rosebengalsodium. A THREAD.
2/ Utilizing clinical data from an ongoing, multi-cohort, Phase 1b/2 study of PV-10+checkpoint ($MRK #keytruda) for checkpoint-naïve metastatic melanoma (NCT02557321). #rosebengal #rosebengalsodium.

1. #Bioinformatics is the application of #computational techniques to the #analysis of #biological #data, such as #sequences, #structures, and #interactions, and is an essential field of modern biology and medicine.
2. #Bioinformatics has many exciting applications in various fields, such as #genetics, #genomics, #proteomics, and #metabolomics, that can provide new insights into the workings of living systems, and can help to advance science and society.

Excited to share our new paper in Nature Chemical Biology @nchembio
AI is poised to transform #therapeutic #science
The Commons is an initiative to access and evaluate #AI capability across therapeutic modalities and stages of discovery 1/4
nature.com/articles/s4158…
AI is poised to transform #therapeutic #science
The Commons is an initiative to access and evaluate #AI capability across therapeutic modalities and stages of discovery 1/4
nature.com/articles/s4158…

@nchembio @KexinHuang5 @TianfanFu @WenhaoGao1 @marinkazitnik @HarvardDBMI @yzhao062 @jure @jimeng @cwcoley @yusufroohani The Commons establishes a foundation for understanding which AI methods are most suitable for drug discovery and why
It provides a robust foundation and modern AI infrastructure to support predictive modeling and data-driven design 2/4
It provides a robust foundation and modern AI infrastructure to support predictive modeling and data-driven design 2/4

@nchembio @KexinHuang5 @TianfanFu @WenhaoGao1 @marinkazitnik @HarvardDBMI @yzhao062 @jure @jimeng @cwcoley @yusufroohani Researchers across disciplines can use the Commons for numerous #drugdiscovery applications 3/4


Join us at #SIPS2022 tomorrow to help make rock solid tools for transparent neuroscience!
We believe the right kind of tools can make methods reporting smoother and less error-prone.
We’ll introduce the ARTEM-IS Web-App (beta) for you to try, and we can work on improving it! 🧵
We believe the right kind of tools can make methods reporting smoother and less error-prone.
We’ll introduce the ARTEM-IS Web-App (beta) for you to try, and we can work on improving it! 🧵

Accurate methods reporting is super important because different processing pathways can lead to different results, as we’ve shown in one multiverse analysis of N400s 🤔
(see how the Related version Reversed comparison has different outcomes in different pathways)
(see how the Related version Reversed comparison has different outcomes in different pathways)

If we want to improve #reproducibility and #replicability in our field, we need to make sure we can accurately report what has been done - which path was taken through the Garden of Forking Paths?
Lots of reporting guidelines currently exist but…
Lots of reporting guidelines currently exist but…


1/ 🧵 Dental research generates data, but is data available and is machine-actionable?
That's the question we asked w/ @ASofiMahmudi @raittioe @IlzeMal & @baiba_vilne in #openaccess @JDentRes journals.sagepub.com/doi/full/10.11… thanks to @mikrotik_com & @bbcentre_eu #FAIR #openscience
That's the question we asked w/ @ASofiMahmudi @raittioe @IlzeMal & @baiba_vilne in #openaccess @JDentRes journals.sagepub.com/doi/full/10.11… thanks to @mikrotik_com & @bbcentre_eu #FAIR #openscience
2/ Raw data allows replication and validation of results. Additionally, if it is in a machine-accessible format, this would allow new hypotheses to be explored using the available data
#reproducibility #researchtransparency #opendata #FAIRdata
#reproducibility #researchtransparency #opendata #FAIRdata

3/ in order for machines to access data, it must be Findable, Accessible, Interoperable and Reusable. This is known as #FAIRdata


Join us at 10:00 EDT from the comfort of your personal conference venue when we talk about "#Reproducibility and #Transparency versus #Privacy and #Confidentiality" #ASSA2022 w/ @john_abowd, Raj+John from @OppInsights, Bruce + James aeaweb.org/conference/202…,

Hm. The listing of names and topics is kind of messed up in the AEA web program. I don't believe that I'm talking about "Data Privacy and Data Collection"... but join us anyway!
Hint: I'm going to argue that it's not "R+T 🤜🤛 P&C" but rather that "R+T 💕 P&C". That's the #EconTwitter version (it's short...), come and join us for the full story!

🙌 Today was a great example of how the #rstats community can help getting learning resources! Thank you for all the amazing material about #deeplearning & #reproducibility with R 🙏 This feels like a good preamble to the remaining poll results about learning strategies 👇

With all these materials out there I am now wondering when will I have time to read it all, same with practicing code and the new skills I will learn after going through them!
68% of replies claimed to practice when they have time, but I think this could have been more accurate 👇

Daily Bookmarks to GAVNet 09/16/2021 greeneracresvaluenetwork.wordpress.com/2021/09/16/dai…
Reproducibility: expect less of the scientific paper
nature.com/articles/d4158…
#reproducibility #replicability #responsibility #ResearchData #ResearchManagement
nature.com/articles/d4158…
#reproducibility #replicability #responsibility #ResearchData #ResearchManagement
The Big Blurry Picture
appliedcomplexity.substack.com/p/the-big-blur…
#AppliedComplexity #unlearning #CoarseGrainedProcesses #control
appliedcomplexity.substack.com/p/the-big-blur…
#AppliedComplexity #unlearning #CoarseGrainedProcesses #control
Daily Bookmarks to GAVNet 07/23/2021 greeneracresvaluenetwork.wordpress.com/2021/07/23/dai…
A design-led approach to embracing an ecosystem strategy
mckinsey.com/business-funct…
#OrganizationDesign #IntegratedEcosystem #BusinessDevelopment
mckinsey.com/business-funct…
#OrganizationDesign #IntegratedEcosystem #BusinessDevelopment
Share methods through visual and digital protocols
nature.com/articles/d4158…
#ExperimentalMethods #reproducibility #accountability #dissemination #revisions
nature.com/articles/d4158…
#ExperimentalMethods #reproducibility #accountability #dissemination #revisions

The evolution of the #RStats script (a thread).
1. You make some analysis with a R script.
You want to share it with some collaborator so she can explore and review the code, propose modifications, fixes, improvements, etc. You send the script by e-mail, along with the data
1. You make some analysis with a R script.
You want to share it with some collaborator so she can explore and review the code, propose modifications, fixes, improvements, etc. You send the script by e-mail, along with the data
Problem: The script is not portable. She needs to substitute some platform-specific packages and functions and modify all paths to the data and to various files. When she sends back her edits, you need to manually revert those changes back again so that it works at your place.
2. The project directory.
You organise files in a directory with a standard structure (src, data, reports) and only use relative paths. You adopt UTF-8 encoding and cross-platform packages and functions.
Your collaborator sends a document reporting and discussing the results.
You organise files in a directory with a standard structure (src, data, reports) and only use relative paths. You adopt UTF-8 encoding and cross-platform packages and functions.
Your collaborator sends a document reporting and discussing the results.

I recently implemented some pairs trading strategies for a paper, and decided to share an implementation of the Gatev, Goetzmann & Rouwenhorst (2006) strategy on a short article on RPubs.
rpubs.com/arubesam/Repli…
#rstats #RPubs #DataScience #finance #pairstrading #reproducibility
rpubs.com/arubesam/Repli…
#rstats #RPubs #DataScience #finance #pairstrading #reproducibility
In the RPubs post above, I provide the #R code to backtest the strategy, as well as some results replicating Gatev, Goetzmann & Rouwenhorst (2006) and Do and Faff (2010), and extending the sample to the end of 2020. In this thread, I show some of these results.
Pairs trading is a type of systematic trading strategy based on finding pairs of stocks or assets that have historically "moved together", and betting that divergences will eventually get corrected. It is a simple form of statistical arbitrage.

👇 Fuzzing Papers with Code 👇
In 2020, only 35 of 60 fuzzing papers published the code together with the paper. In 2021, let's do better! #reproducibility
Data from wcventure.github.io/FuzzingPaper/
Conferences: CCS, NDSS, S&P, USENIX Sec, ICSE, ESEC/FSE, ISSTA, ASE, ASIACCS, ICST.
1/5
In 2020, only 35 of 60 fuzzing papers published the code together with the paper. In 2021, let's do better! #reproducibility
Data from wcventure.github.io/FuzzingPaper/
Conferences: CCS, NDSS, S&P, USENIX Sec, ICSE, ESEC/FSE, ISSTA, ASE, ASIACCS, ICST.
1/5
Alphabetically,
* github.com/aflnet/aflnet
* github.com/aflplusplus/AF…
* github.com/andreafioraldi…
* github.com/assist-project…
* github.com/duytai/sfuzz
* github.com/fau-inf2/StarS…
* github.com/hexhive/USBFuzz
* github.com/hexhive/FuzzGen
* github.com/hexhive/retrow…
* github.com/hub-se/MoFuzz
2/5
* github.com/aflnet/aflnet
* github.com/aflplusplus/AF…
* github.com/andreafioraldi…
* github.com/assist-project…
* github.com/duytai/sfuzz
* github.com/fau-inf2/StarS…
* github.com/hexhive/USBFuzz
* github.com/hexhive/FuzzGen
* github.com/hexhive/retrow…
* github.com/hub-se/MoFuzz
2/5

Happy March! What better way to start a new month than by spreading the word on all things #openscience! Over the next month we’ll be sharing 1 summary of #openscience literature every day because you know what they say, an open science paper a day keeps the bad science away! 👏

If 1 summary just isn’t enough check out the FORRT website forrt.org/summaries/! The summaries are a work in progress & we are always looking for people to contribute their thoughts/ideas - if you’d like to get involved or have comments get in touch we’d love to hear from you!
Kicking off the #OpenScience summaries with 7 Easy Steps to Open Science! The paper provides an introduction to open science and related reforms in the form of an annotated reading list of seven peer-reviewed articles! 👏


Executable papers on CodaLab Worksheets are now linked from paperswithcode.com pages thanks to a collaboration with @paperswithcode! For example:
paperswithcode.com/paper/noise-in…
paperswithcode.com/paper/noise-in…


Executable papers contain not just the code and data, but also the experiments that produced the results of a paper. Releasing code is great, but CodaLab goes one step further for full #reproducibility, providing the full certifiable provenance of an empirical result.

I am very happy that @MKrzywinski and Naomi Altman gave us the opportunity to contribute an article on the #standardizationfallacy to their legendary #pointsofsignificance column in @naturemethods
nature.com/articles/s4159…
nature.com/articles/s4159…
It all started 20 (actually 21) years ago with this 👇correspondence on behaviour and the standardization fallacy in @NatureGenet nature.com/articles/ng110…
It was my response to this 👇famous paper in @ScienceMagazine by John Crabbe and colleagues showing that behavioural phenotypes of mouse mutants may turn out to be lab specific science.sciencemag.org/content/284/54…
Unpopular opinion. In Computer Science, we should start organizing a new kind of conferences where #reproducibility and #openscience are first-class citizens. You submit claims (paper) together with the evidence (data, tools,..). The PC can query the evidence via an AEC. 1/2
(PC = Program Committee, AEC = Artifact Evaluation Committee).
* Yes, as author you will get less papers accepted, but the quality of accepted papers would be supreme.
* Yes, not every research facilitates the submission of "evidence", but you can always submit elsewhere.
2/2
* Yes, as author you will get less papers accepted, but the quality of accepted papers would be supreme.
* Yes, not every research facilitates the submission of "evidence", but you can always submit elsewhere.
2/2
@threadreaderapp unroll

Hi everyone! I'm Louise Bowler, a Research Data Scientist from @turinginst's Research Engineering Group @turinghut23. I'm borrowing the account for the day to show you all a day in the life of a Research Data Scientist! 👩💻
I stumbled across this job whilst I was writing up my PhD and immediately went “Yes, that’s the job I want but didn’t know existed!” I wanted to stay close to research but not be tied to a single field, so the projects here are a great fit
I’ve always enjoyed switching fields – I started out as an undergraduate @ImperialPhysics, then explored the biological and medical sciences during the first year of my PhD @dtc_oxford 🌟🪐👩🔬🖥️🧬🧫💊

In a new preprint, @sinabooeshaghi et al. present deep SMART-Seq, @10xGenomics and MERFISH #scRNAseq (37,925,526,323 reads, 344,256 cells) from the mouse primary motor cortex, demonstrating the benefits of cross-platform isoform-level analysis. biorxiv.org/content/10.110… 1/15

We produce an isoform atlas and identify isoform markers for classes, subclasses and clusters of cells across all layers of the primary motor cortex. 2/15
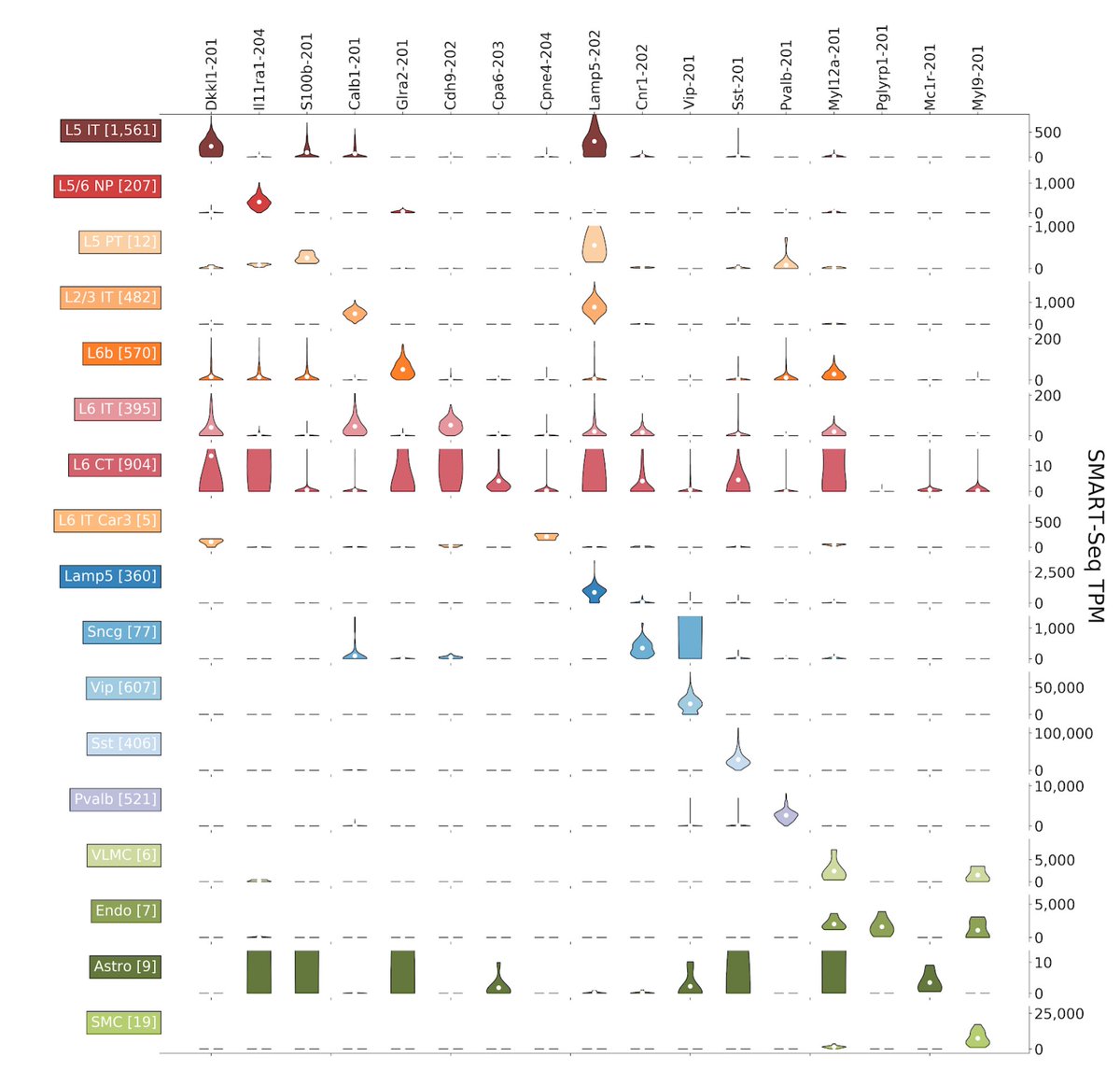

Isoform-level results are facilitated by kallisto isoform-level quantification of the SMART-seq data. We show that such EM-based isoform quantification is essential not just for isoform but for gene-level results. #methodsmatter 3/15


Your MDS Curator this week, @TiffanyTimbers, here.
This morning I would like to share with you some of the most influential resources that have shaped my #DataScience workflow:
1. @swcarpentry 's Version Control with Git lesson: swcarpentry.github.io/git-novice/
This morning I would like to share with you some of the most influential resources that have shaped my #DataScience workflow:
1. @swcarpentry 's Version Control with Git lesson: swcarpentry.github.io/git-novice/
@TiffanyTimbers @swcarpentry @JennyBryan 3. "Good enough practices in scientific computing" by @gvwilson @JennyBryan Karen Cranston Justin Kitzes @lexnederbragt & @tracykteal
journals.plos.org/ploscompbiol/a…
journals.plos.org/ploscompbiol/a…

A "worrying analysis":
"18 [#deeplearning] algorithms ... presented at top-level research conferences ... Only 7 of them could be reproduced w/ reasonable effort ... 6 of them can often be outperformed w/ comparably simple heuristic methods."
Paper:
lnkd.in/dTaGCTv
#AI
"18 [#deeplearning] algorithms ... presented at top-level research conferences ... Only 7 of them could be reproduced w/ reasonable effort ... 6 of them can often be outperformed w/ comparably simple heuristic methods."
Paper:
lnkd.in/dTaGCTv
#AI

[Updates worth tweeting]
2/
There is much concern about #reproducibility issues and flawed scientific practices in the #ML community in particular & #academia in general.
Both the issues and the concerns are not new.
Isn't it time to put an end to them?
2/
There is much concern about #reproducibility issues and flawed scientific practices in the #ML community in particular & #academia in general.
Both the issues and the concerns are not new.
Isn't it time to put an end to them?
3/
There are several works that have exposed these and similar problems along the years.
👏👏 again to @Maurizio_fd et al. for sharing their paper and addressing #DL algorithms for recommended systems (1st tweet from this thread).
But there is more, unfortunately:
There are several works that have exposed these and similar problems along the years.
👏👏 again to @Maurizio_fd et al. for sharing their paper and addressing #DL algorithms for recommended systems (1st tweet from this thread).
But there is more, unfortunately:

Now out! New report examines Reproducibility and Replicability in Science, with recommendations for researchers, agencies, policy makers, journals, etc.
@theNASEM ow.ly/BK5350u0Iz2
#ReproducibilityInScience
@theNASEM ow.ly/BK5350u0Iz2
#ReproducibilityInScience
@theNASEM Terms like “reproducibility” and “replicability” are sometimes used as an umbrella word to encompass all related concerns. But often, researchers use each term to refer to a distinct concept. #ReproducibilityInScience
@theNASEM The committee defined #reproducibility as obtaining consistent computational results using the same input data, computational steps, methods, code, and conditions of analysis as an original study.

Today I'd like to talk about issues with respect to #openscience and specifically sharing code.
But first an intro to what open science is...
But first an intro to what open science is...
I am sure you all know a bit about #openscience already but essentially it's a very broad community/movement that aims to make science more accessible, transparent, inclusive, etc.
@daniellecrobins and @rchampieux have this great umbrella infographic!
@daniellecrobins and @rchampieux have this great umbrella infographic!
#Openscience boils down to making science more free and open in the same general ways that the related open source and free software movements/communities pushed for change by making the outputs of science more accessible to both the general public and to other scientists.

Today at my first #SciData18 conference with @SpringerNature. Today's themes are:
mentoring open science
+
making data findable, accessible, interoperable and reusable throughout the research lifecycle
mentoring open science
+
making data findable, accessible, interoperable and reusable throughout the research lifecycle
Data Generalist @becky_boyles
Scientists must store, integrate, analyse, compare + share data sets. Via @TheEconomist, data is the new oil
Or is it the new plastic?
Careful how data used as resource. Closed v shared v open data. Not even 'open data' is truly open #SciData18
Scientists must store, integrate, analyse, compare + share data sets. Via @TheEconomist, data is the new oil
Or is it the new plastic?
Careful how data used as resource. Closed v shared v open data. Not even 'open data' is truly open #SciData18
Data Generalist @becky_boyles
New model for data -
not sharing data via 'copying' (email, dropbox)
enhanced security where user is both producer and consumer
teams form outside silos
democratic tools for use by non-programmers
integrated data
#SciData18
New model for data -
not sharing data via 'copying' (email, dropbox)
enhanced security where user is both producer and consumer
teams form outside silos
democratic tools for use by non-programmers
integrated data
#SciData18
