Discover and read the best of Twitter Threads about #stableDiffusion
Most recents (24)

1. Generate Picture Books with AI for free (code open-source👇) with @OpenAI Function Calling, @LangChainAI, #DeepLake, & @StabilityAI.
- Prompt -> a PDF storybook with illustrations.
- Stores image & text pairs in the multimodal #DeepLake VectorDB for model training/finetuning!
- Prompt -> a PDF storybook with illustrations.
- Stores image & text pairs in the multimodal #DeepLake VectorDB for model training/finetuning!
2. Read the 🧵 to learn how @OpenAI Function Calling & @LangChainAI helped.
FableForge is built by @ethanjdev & handles:
1. Prompt -> text & images
2. PDF creation
3. Deep Lake DB to view the multimodal images + text dataset or stream it in real-time to train/fine-tune an LLM.
FableForge is built by @ethanjdev & handles:
1. Prompt -> text & images
2. PDF creation
3. Deep Lake DB to view the multimodal images + text dataset or stream it in real-time to train/fine-tune an LLM.

3. But first... What's @OpenAI's function calling update?
In essence, it's bridging the gap between unstructured language input and structured, actionable output that other systems, tools, or services can use.
In essence, it's bridging the gap between unstructured language input and structured, actionable output that other systems, tools, or services can use.

We’ve got huge plans at @streamlit for LLMs and #GenAI! 🎈🙌
✔️A new customizable chat UI
✔️@LangChainAI integration
✔️Easy connection to the LLM ecosystem
and more!
Our founders @myelbows & @cutlasskelly give you a glimpse into our future! ⬇
🔗 blog.streamlit.io/generative-ai-…
🧵↓
✔️A new customizable chat UI
✔️@LangChainAI integration
✔️Easy connection to the LLM ecosystem
and more!
Our founders @myelbows & @cutlasskelly give you a glimpse into our future! ⬇
🔗 blog.streamlit.io/generative-ai-…
🧵↓
We now have over 5K #LLM-powered @streamlit apps created by our fantastic community! ✨
Powered by @OpenAI, @LangChainAI, @llama_index, @huggingface, #StableDiffusion, @pinecone & more! 🙌
To celebrate, we've published our new #GenerativeAI hub!
🔗 streamlit.io/generative-ai
Powered by @OpenAI, @LangChainAI, @llama_index, @huggingface, #StableDiffusion, @pinecone & more! 🙌
To celebrate, we've published our new #GenerativeAI hub!
🔗 streamlit.io/generative-ai
So why are LLMs like #ChatGPT so great at writing @streamlit apps?
Because of all the Streamlit code our community has shared!
190K+ snippets of Streamlit code on @github alone, helping train #GPT4 and the likes!
No more coding skills needed to hop on that Streamlit boat! 🤗
Because of all the Streamlit code our community has shared!
190K+ snippets of Streamlit code on @github alone, helping train #GPT4 and the likes!
No more coding skills needed to hop on that Streamlit boat! 🤗

Exciting updates to #stablediffusion with Core ML!
- 6-bit weight compression that yields just under 1 GB
- Up to 30% improved Neural Engine performance
- New benchmarks on iPhone, iPad and Macs
- Multilingual system text encoder support
- ControlNet
github.com/apple/ml-stabl… 🧵
- 6-bit weight compression that yields just under 1 GB
- Up to 30% improved Neural Engine performance
- New benchmarks on iPhone, iPad and Macs
- Multilingual system text encoder support
- ControlNet
github.com/apple/ml-stabl… 🧵
coremltools-7.0 introduced advanced model compression techniques. For Stable Diffusion, we demonstrate how 6-bit post-training palettization yields faster models that consume 63% less memory compared to float16. Output variance is comparable to GPU vs Neural Engine.

This 25-minute WWDC23 session is the best resource to learn more about model compression for Apple Silicon: developer.apple.com/videos/play/ww…. We only demonstrate post-training palettization for Stable Diffusion. For better results, check out training-time palettization for 2- and 4-bits!

CREATE STICKER / PFP / EMOJI / LOGO of your dog with AI🐶- AI Summer Hacks #5🧵
It's no secret that AI is capable of creating personalized pics of you or anyone you love😋
I've made a series of pics of my dog Audrey, and already using some as Telegram stickers🦾
HOW?👇
🧵1/10
It's no secret that AI is capable of creating personalized pics of you or anyone you love😋
I've made a series of pics of my dog Audrey, and already using some as Telegram stickers🦾
HOW?👇
🧵1/10

Here're ways to make a personalized pic, in #midjourney & #stablediffusion :
MJ:
- /describe
- /imagine w/ IRL reference
- /blend
SD:
- img2img (w/, w/o ControlNet)
- Dreambooth
- Lora
- Embedding
- Hypernetwork
DREAMBOOTH remains the most effective, so I used it here🔥
🧵2/10
MJ:
- /describe
- /imagine w/ IRL reference
- /blend
SD:
- img2img (w/, w/o ControlNet)
- Dreambooth
- Lora
- Embedding
- Hypernetwork
DREAMBOOTH remains the most effective, so I used it here🔥
🧵2/10
Dreambooth is an algorithm that allows you to train an entire AI generative model on your own pics
@icreatelife made an exhaustive step-by-step tutorial on how to perform this training👇
1⃣STEP ONE: 1st step 'll be to watch and repeat!🤩
Part 1 -
🧵3/10
@icreatelife made an exhaustive step-by-step tutorial on how to perform this training👇
1⃣STEP ONE: 1st step 'll be to watch and repeat!🤩
Part 1 -
🧵3/10

@Ai_Lust_ The Ritual
An Offering
Day 1
#AIArtwork #midjourney #aiart #faecore #AiLust #coven #witch #AIart #midjourney #folklore #ActiveArtCollective #AIArtistCommunity #AiLust #AIArtist #StableDiffusion #AIイラスト好きさんと繋がりたい
An Offering
Day 1
#AIArtwork #midjourney #aiart #faecore #AiLust #coven #witch #AIart #midjourney #folklore #ActiveArtCollective #AIArtistCommunity #AiLust #AIArtist #StableDiffusion #AIイラスト好きさんと繋がりたい

@Ai_Lust_ The Ritual
The Coven
Day 2 #AIArtwork #midjourney #aiart #faecore #AiLust #coven #witch #AIart #midjourney #folklore #ActiveArtCollective #AIArtistCommunity #AiLust #AIArtist #StableDiffusion #AIイラスト好きさんと繋がりたい
The Coven
Day 2 #AIArtwork #midjourney #aiart #faecore #AiLust #coven #witch #AIart #midjourney #folklore #ActiveArtCollective #AIArtistCommunity #AiLust #AIArtist #StableDiffusion #AIイラスト好きさんと繋がりたい


@Ai_Lust_ The Ritual
The Summoning
Day 3 #AIArtwork #midjourney #aiart #faecore #AiLust #coven #witch #AIart #midjourney #folklore #ActiveArtCollective #AIArtistCommunity #AiLust #AIArtist #StableDiffusion #AIイラスト好きさんと繋がりたい
The Summoning
Day 3 #AIArtwork #midjourney #aiart #faecore #AiLust #coven #witch #AIart #midjourney #folklore #ActiveArtCollective #AIArtistCommunity #AiLust #AIArtist #StableDiffusion #AIイラスト好きさんと繋がりたい



Wenn ich Künstler:innen und Grafiker:innen über AI-Art reden höre, kommen am häufigsten zwei Reaktionen.
a) Diese zufälligen Bildchen aus dem Internet können nix. Die haben ja alle 6 Finger und schiefe Gesichter.
b) Das wird bestimmt bald verboten, weil es gegen Urheberrecht |1
a) Diese zufälligen Bildchen aus dem Internet können nix. Die haben ja alle 6 Finger und schiefe Gesichter.
b) Das wird bestimmt bald verboten, weil es gegen Urheberrecht |1

verstößt.
Aber Midjourney & Co zeigen nicht einmal einen Bruchteil der Fähigkeiten von StableDiffusion oder Adobe Firefly, das in der aktuellen Beta von Photoshop bereits enthalten ist.
Und die Updates rollen. Automatic 1111, die Oberfläche von #StableDiffusion, läuft bereits |2
Aber Midjourney & Co zeigen nicht einmal einen Bruchteil der Fähigkeiten von StableDiffusion oder Adobe Firefly, das in der aktuellen Beta von Photoshop bereits enthalten ist.
Und die Updates rollen. Automatic 1111, die Oberfläche von #StableDiffusion, läuft bereits |2

als voll funktionstüchtiges Plugin in Photoshop, dessen eigene AI jetzt noch dazu kommt.
In den letzten 3 Tagen ist ControlNet um mehrere Versionen upgedatet worden. Das passiert quasi täglich und die Modelle werden immer mächtiger.
Aus einer schnellen Fotomontage (s.u.), |3
In den letzten 3 Tagen ist ControlNet um mehrere Versionen upgedatet worden. Das passiert quasi täglich und die Modelle werden immer mächtiger.
Aus einer schnellen Fotomontage (s.u.), |3


DeepSquare integrates the neural network #text2image model #StableDiffusion.
This thread presents how we #designed and implemented the #workflow to execute Stable Diffusion on the DeepSquare Grid.
This thread presents how we #designed and implemented the #workflow to execute Stable Diffusion on the DeepSquare Grid.
We designed the workflow as follows:
The #prompt is sent over an environment variable.
Most of the parameters are sent via environment varibles.
Images are sent to transfer.deepsquare.run
The #prompt is sent over an environment variable.
Most of the parameters are sent via environment varibles.
Images are sent to transfer.deepsquare.run
The docker image is already compiled from github.com/Stability-AI/s… and is exported as registry-1.deepsquare.run/library/stable…
The steps are as follows:
1-Generate the images. Rows are distributed into task per #GPU.
2-Combine all the images into one grid.
The steps are as follows:
1-Generate the images. Rows are distributed into task per #GPU.
2-Combine all the images into one grid.


Want to make the most out of @midjourney and other image diffusion models w/ us & the AI gurus at @ohnahji? 💡Here's a pro tip: drill down your prompt to use the tool quickly and efficiently! ⚡️ Get the results you need in no time #imageprocessing #deeplearning #productivityhack
One key way to boost your image diffusion model output is with demonyms in your prompts! What… is THAT? 🤣No, Demonyms have nothing to do with demons lol, they describe inhabitants of a place and help create more specific prompts for better results. #demonyms #promptingtips
In this thread we'll focus on West African country demonyms and show you how to use them in your image prompts for better results. Here are 10:
Nigerian 🇳🇬
Ghanaian 🇬🇭
Senegalese 🇸🇳
Ivorian 🇨🇮
Malian 🇲🇱
Beninese 🇧🇯
Guinean 🇬🇳
Liberian 🇱🇷
Sierra Leonean 🇸🇱
Togolese 🇹🇬
#WestAfrica
Nigerian 🇳🇬
Ghanaian 🇬🇭
Senegalese 🇸🇳
Ivorian 🇨🇮
Malian 🇲🇱
Beninese 🇧🇯
Guinean 🇬🇳
Liberian 🇱🇷
Sierra Leonean 🇸🇱
Togolese 🇹🇬
#WestAfrica

Vermilion
19P Image Set at 10000px resolution available on Patreon 👇👍✅
patreon.com/posts/10k-19p-…
#AIWaifu image created with #StableDiffusion
#FinalFantasyVIIRemake #TifaLockhart inspired #AICosplay
19P Image Set at 10000px resolution available on Patreon 👇👍✅
patreon.com/posts/10k-19p-…
#AIWaifu image created with #StableDiffusion
#FinalFantasyVIIRemake #TifaLockhart inspired #AICosplay

Vermilion
19P Image Set at 10000px resolution available on Patreon 👇👍✅
patreon.com/posts/10k-19p-…
#AIWaifu image created with #StableDiffusion
#FinalFantasyVIIRemake #TifaLockhart inspired #AICosplay
19P Image Set at 10000px resolution available on Patreon 👇👍✅
patreon.com/posts/10k-19p-…
#AIWaifu image created with #StableDiffusion
#FinalFantasyVIIRemake #TifaLockhart inspired #AICosplay

Vermilion
19P Image Set at 10000px resolution available on Patreon 👇👍✅
patreon.com/posts/10k-19p-…
#AIWaifu image created with #StableDiffusion
#FinalFantasyVIIRemake #TifaLockhart inspired #AICosplay
19P Image Set at 10000px resolution available on Patreon 👇👍✅
patreon.com/posts/10k-19p-…
#AIWaifu image created with #StableDiffusion
#FinalFantasyVIIRemake #TifaLockhart inspired #AICosplay


🍎 Pour l’IA, le monde n’en a que pour OpenAI, Microsoft ou encore Stability.
Pourtant une entreprise, qui n’a pas encore annoncé son « #ChatGPT » / LLM pourrait être un game changer…
@Apple de @tim_cook pourrait changer le paysage de l’IA pour de bon… vous en pensez quoi ?
Pourtant une entreprise, qui n’a pas encore annoncé son « #ChatGPT » / LLM pourrait être un game changer…
@Apple de @tim_cook pourrait changer le paysage de l’IA pour de bon… vous en pensez quoi ?

En effet, 1️⃣ on a une tendance claire à l’allègement des modèles LLM et la semaine dernière on a eu #WebGPT, donc une démocratisation du LLM sur des terminaux légers est possible :
2️⃣ Avec une base installée de 2 milliards d’appareils actifs, un historique autour de Siri, et une capacité d’intégration hors norme, il y a fort à parier, comme le pense @SullyOmarr, que Apple travaille sur son AppleGPT, un #LLM optimisé pour ses appareils… d’autant que :

What does a mirror see?
What does a mirror see if the mirror looked into random alternative Gothic universes...
#GothLookingGlass #AI_Filter #AI #AIart #thread
What does a mirror see if the mirror looked into random alternative Gothic universes...
#GothLookingGlass #AI_Filter #AI #AIart #thread

This is the very fist image produced by the #GothLookingGlass prompt series.
This mirror seems to look upon a backrooms styled bathing room set to 1600s Electro-Gothic SubCulture.
Yes, this does try to hit a "1580 - 1600s" Gothic Sub-Culture imagery as if looking from a mirror.
This mirror seems to look upon a backrooms styled bathing room set to 1600s Electro-Gothic SubCulture.
Yes, this does try to hit a "1580 - 1600s" Gothic Sub-Culture imagery as if looking from a mirror.

So we see rooms are the main point of interest for the surroundings & we see already the AI is trying to trace light sources.
We change the prompt a bit to get here and we change it again after this.
We change the prompt a bit to get here and we change it again after this.




Lets go on a journey.
What can #AI do with a single color?
#stablediffusion (SD) will be used for this thread.
Color provided by @everygothcolor (recommended for future Gothic color tweets)
What can #AI do with a single color?
#stablediffusion (SD) will be used for this thread.
Color provided by @everygothcolor (recommended for future Gothic color tweets)

So, the left is SD 1.5 & the right is SD 2.1
2.1 handles single colors very well
1.5 did add to the image but it's in such slight hue difference most human eyes won't see it without enlarging/zooming/digital effecting
Check ALT for prompt/noise %s
2.1 handles single colors very well
1.5 did add to the image but it's in such slight hue difference most human eyes won't see it without enlarging/zooming/digital effecting
Check ALT for prompt/noise %s


From here, we will start back at the original 1.5 output from the single color and the very next img we get is on the left side.
We used the right image as the new starter image to get the left image.
check alt for noise/prompt %s
We used the right image as the new starter image to get the left image.
check alt for noise/prompt %s



HOLY SHIT. @RenderToken & @StabilityAI is here. 🧵 [1/5]
🎥Watch the video to see it in action!
Amazing to see how a conversation from @JulesUrbach and @EMostaque turns creates a new use case.
A new day, a new decade 😅
#stablediffusion #RNDR @OTOY @OctaneRenderIt #ai
🎥Watch the video to see it in action!
Amazing to see how a conversation from @JulesUrbach and @EMostaque turns creates a new use case.
A new day, a new decade 😅
#stablediffusion #RNDR @OTOY @OctaneRenderIt #ai
This cost me £0.02 ($0.025) for instant results (video is real-time). Stable Diffusion can now have decentralised access to GPU power thanks to @RenderToken. Say bye bye to AWS, Azure, and other costly/capped GPU services. Exponential growth depending on your use case. [2/5]
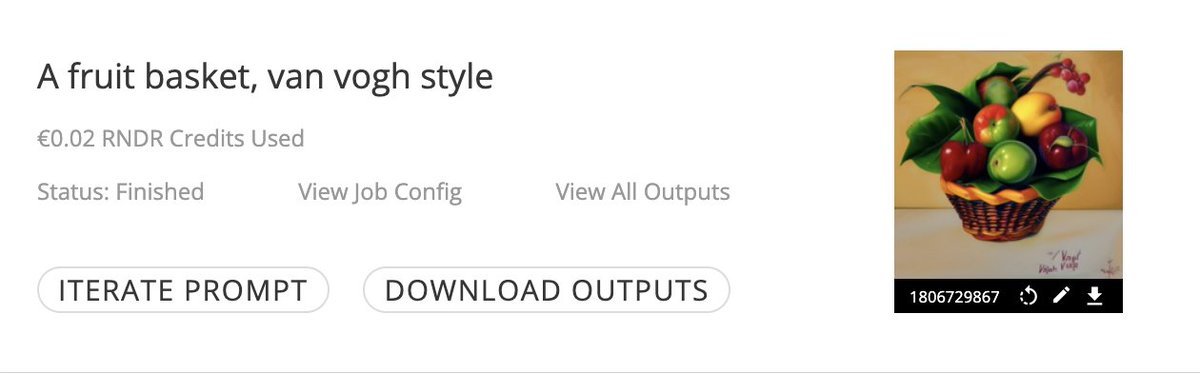
With it being cloud based, that also removes the need for personally owning expensive GPU's, democratising access to these tools even further to those who can't afford/run this to begin with. What a time to be alive! [3/5]

using the internet now is a 24/7 job interview
no different from gamespot/ANN reviewing games/anime while having the site covered in ads for new games/anime
ingame sf6 chun-li looks like something a mediocre twitter artist who says "lewds" would draw

🤯AI can "see" your thoughts! What's next?! 🧠👀
Osaka University researchers decode brain activity, sparking privacy debates!
How will this power be used? 🚨👇
Osaka University researchers decode brain activity, sparking privacy debates!
How will this power be used? 🚨👇

Researchers have used a deep learning AI model #StableDiffusion to decode brain activity, generating images of what test subjects were seeing while inside an MRI.
This breakthrough does not represent mind-reading, as it can only produce images a person has viewed.
For now 🙃
This breakthrough does not represent mind-reading, as it can only produce images a person has viewed.
For now 🙃
📺 The current method cannot be transferred to novel subjects due to individual brain differences.
Potential applications include clinical, communication, or entertainment purposes, with concerns about ethics and data usage, or genuine mind-reading.
Potential applications include clinical, communication, or entertainment purposes, with concerns about ethics and data usage, or genuine mind-reading.

What important messages would Jesus share if he found himself resurrected at Walmart?
#HappyEaster #JesusChrist #Church #Christianity #WorshipAI #HealthyLiving #Walmart #AIArtCommunity #MidJourney #MindJourney
🧵Thread - Share your thoughts on AI merging with religion and… twitter.com/i/web/status/1…
#HappyEaster #JesusChrist #Church #Christianity #WorshipAI #HealthyLiving #Walmart #AIArtCommunity #MidJourney #MindJourney
🧵Thread - Share your thoughts on AI merging with religion and… twitter.com/i/web/status/1…

Would he have anything to say about kosher food?

What would Jesus think about plastic Easter eggs?


1/ 🚀 Runway's groundbreaking #Gen1 is here!
@runway has the tech, the network, and the community to reshape the online video landscape.
Here's why we should get ready...
🧵👀
@runway has the tech, the network, and the community to reshape the online video landscape.
Here's why we should get ready...
🧵👀
2/ 💡 @runway has been developing AI video tools since 2018 and garnered support from content creators and major movie/TV studios. 🎬
And in 2021, they teamed up with @LMU_Muenchen to develop the first version of #stablediffusion 🤯
technologyreview.com/2023/02/06/106…
#AICinema #AiArt
And in 2021, they teamed up with @LMU_Muenchen to develop the first version of #stablediffusion 🤯
technologyreview.com/2023/02/06/106…
#AICinema #AiArt

📢 Attention #MageCommunity
Major announcement! We're launching the Mage Model Creators Program to revolutionize the open-source AI landscape.🌟 #stablediffusion
Read the full announcement here: mage.space/model-creators…
👇🧵
Major announcement! We're launching the Mage Model Creators Program to revolutionize the open-source AI landscape.🌟 #stablediffusion
Read the full announcement here: mage.space/model-creators…
👇🧵
1⃣ Mage Model Creators Program
An opt-in program empowering custom AI model creators to earn revenue on a per-generation basis. Top creators can make high 4-figure USD monthly revenue. 🤑
An opt-in program empowering custom AI model creators to earn revenue on a per-generation basis. Top creators can make high 4-figure USD monthly revenue. 🤑
2⃣ Eligibility
Every AI model on Mage is eligible for this game-changing program. 🌐
Every AI model on Mage is eligible for this game-changing program. 🌐
🔥Anime AI Model🔥
DucHaitenClassicAnime is a custom AI model great for classic anime and is available on mage.space
View examples here: mage.space/u/DucHaitenCA
#stablediffusion #aiia #aiart #midjourney #dalle
👇🧵
DucHaitenClassicAnime is a custom AI model great for classic anime and is available on mage.space
View examples here: mage.space/u/DucHaitenCA
#stablediffusion #aiia #aiart #midjourney #dalle
👇🧵

lady

gentleman


1/n The private biotech industry perhaps has at least 10-20 years more accumulated knowledge than the academic world. A majority do not realize this. This is why nation-states like China and Russia cannot create vaccines like in the West. AI will end up similarly.
2/n This large disparity in knowledge and know-how is a consequence of the evolutionary nature of biology. This nature also exists in deep learning AI. Evolution's creativity is a consequence of frozen accidents; these accidents cannot be uncovered through first principles.
3/n Genentech, an early pioneer in genetic engineering, has specially engineered organisms (i.e., mice) that the rest of the world cannot access. Many biotech companies have secret sauce that can only be discovered through experimentation.
Portrait🧡
Art created via mage.space
#aiart #stablediffusion #dalle2 #midjourney #magespace #aiia
Prompt included👇
Art created via mage.space
#aiart #stablediffusion #dalle2 #midjourney #magespace #aiia
Prompt included👇

Prompt: "white woman, ginger hair, light blue eyes, very pale skin, in city clothes, slim body, face freckles, little nose, detailled eyebrows, piercings in nose, ((film grain, skin details, high detailed skin texture, 8k hdr, dslr))"
Continued👇
Continued👇
Negative Prompt: "ugly, bad face, disfigured, bad looking, multiple hand, bad nose, ugly nose, multi body, disformed, multiple head"
Continued👇
Continued👇
Liger 🦁🐯🌈
Art created by @ AiryAI via mage.space
#aiart #stablediffusion #dalle2 #midjourney #magespace #aiia
Prompt included👇
Art created by @ AiryAI via mage.space
#aiart #stablediffusion #dalle2 #midjourney #magespace #aiia
Prompt included👇

Prompt: "8k image, sharp focus, sharp focus, insanely detailed and intricate, cinematic lighting, Octane render, doomsday scene, 8K, hyperrealism, octane render, hyper detailed,
Continued👇
Continued👇
volumetric lighting, hdr, realistic soft skin, shining, vibrant, photorealism, Canon EOS 7D, Canon EF 70-200mm f/2.8L IS, vibrant colors, shot by best camera, quality, focused"
Continued👇
Continued👇

AIを用いたアニメーションのテスト
Stable Diffusion( ebsynth utility, LoRA, ControlNet),VRoid, Unity, krita
#StableDiffusion #AIイラスト
Stable Diffusion( ebsynth utility, LoRA, ControlNet),VRoid, Unity, krita
#StableDiffusion #AIイラスト
VRoidでモデル制作→LoRAで学習→Unityで雑にアニメーションとカメラの設定、MP4で出力→ebsynth utilityでフレーム切り出しとマスク→キーフレーム抽出→Loopback4~5、Face CropのDetection MethodはYolov5(起動オプション書き換えないといけないので注意)→ kritaで毎フレーム手動でノイズ除去、連結



「monochrome line art」というプロンプトのテスト。モデルや呪文を練れば、もっとちゃんと「マンガの作画」っぽくできそう。
#AIart #AIイラスト #AI漫画 #StableDiffusion #AI呪文研究部
#AIart #AIイラスト #AI漫画 #StableDiffusion #AI呪文研究部




でも、せっかく「フルカラーのハイカロリーな作画を量産できる」というAIの強みがあるのに、それをわざわざ捨てて「人間の作画」に似せる必要性 is どこ?
ついでに、フルカラーイラストから線画を綺麗に抽出する技術がすでにあるので、無理にグレスケ絵をSDに吐かせる必要はない…
