Discover and read the best of Twitter Threads about #iclr2022
Most recents (13)

During closing remarks, Yan Liu says that #ICLR2022 had 4800 attendees from 81 countries. Thank you to the @iclr_conf organizers who volunteered to do this and during a pandemic.
She also briefly mentions zoom fatigue.
I definitely have one. I haven't found the right strategy to be fully present at virtual conferences. But I also really appreciate having the talks available afterwords.
I definitely have one. I haven't found the right strategy to be fully present at virtual conferences. But I also really appreciate having the talks available afterwords.
Maybe if we believed that conferences would be fully virtual forever, we would re-configure all of our events differently?
Maybe we'd only have like 3 hours a day type of content and have stuff live? I don't know.
Maybe we'd only have like 3 hours a day type of content and have stuff live? I don't know.

Language models like GPT-3 and Codex can generate code, but they can miss your intent and their code can have bugs. Can we improve that? Perhaps guarantee the absence of certain errors? Come checkout Synchromesh at #ICLR2022 tomorrow! 

We start by identifying two broad classes of mistakes that these models can make:
1- Conceptual errors, when they miss or ignore parts of the specification
2- Implementation errors, where their output can fail to parse, type-check, execute, or violate other desirable constraints
1- Conceptual errors, when they miss or ignore parts of the specification
2- Implementation errors, where their output can fail to parse, type-check, execute, or violate other desirable constraints
Conceptual errors are highly influenced by which examples we give these models in their prompt. Few-shot examples can bias the model in either the right or wrong direction. It's often possible to get the output we want by just giving better examples.

If you’re at #ICLR2022, hope you’ll check out our spotlighted poster: “Multitask Prompted Training Enables Zero-Shot Task Generalization.” arxiv.org/abs/2110.08207
Poster session 5, Tue 1:30-3:30 ET
Poster session 5, Tue 1:30-3:30 ET

This work was a big undertaking from many at the @BigscienceW Workshop, particularly @SanhEstPasMoi, @albertwebson, @colinraffel, and @srush_nlp. It’s been awesome to see all the people already using and building on the T0 family of models for zero-shot learning.
There’s rightly been a lot of excitement around the zero-shot performance of T0 and similar, concurrent approaches like FLAN (ai.googleblog.com/2021/10/introd…).
I also want to highlight the data-centric side of the T0 work.
I also want to highlight the data-centric side of the T0 work.

How can we algorithmically figure out what our model doesn’t know, and then construct datasets to improve it?
We tackle this question in “Know thy student: Interactive learning with Gaussian processes” at #ICLR2022 @cells2societies workshop.
Paper: openreview.net/pdf?id=rpGGNrM…
[1/N]
We tackle this question in “Know thy student: Interactive learning with Gaussian processes” at #ICLR2022 @cells2societies workshop.
Paper: openreview.net/pdf?id=rpGGNrM…
[1/N]

We cast this problem as a teacher-student setup where the teacher must first interact to diagnose 🧪the student (the model), before teaching 👩🏫(constructing the training dataset).
[2/N]
[2/N]
Eg. in an offline reinforcement learning setting, the student must navigate to the goal (green). The teacher determines states (yellow) the student has explored and accomplishes this task. The teacher can then construct demonstrations from states (orange) the student fails.
[3/N]
[3/N]


After extreme procrastination, I finally finished the blog post on "why we should use synthetic dataset in ML".
In other words, can we use all these amazing #dalle2 synthetic images to improve generalization.
vsehwag.github.io/blog/2022/4/sy…
In other words, can we use all these amazing #dalle2 synthetic images to improve generalization.
vsehwag.github.io/blog/2022/4/sy…

Training on synthetic+real data, tend to show an inflection point. As the quality of synthetic data improves, it will go from "degrading performance" -> "no benefit at all" -> "finally benefit in generalization". Diffusion models cross the inflection point on most datasets.
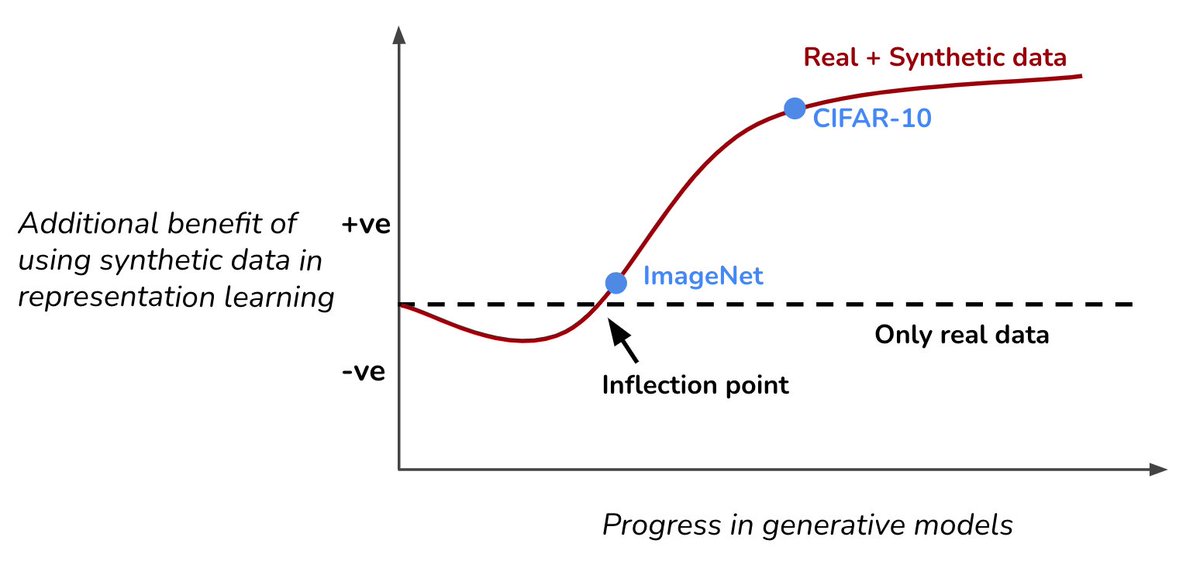
The benefit of synthetic data is even higher in adversarial/robust training, since it is known to be more data hungry.
On cifar10, using synthetic data leads to tremendous boost in robust accuracy. More details are in our upcoming paper at #ICLR2022
rb.gy/dlve4y
On cifar10, using synthetic data leads to tremendous boost in robust accuracy. More details are in our upcoming paper at #ICLR2022
rb.gy/dlve4y


Proudly presenting at #ICLR2022: Our DEG model learns to optimize a symbolic grammar for generating molecules and works in the very common small data scenario mostly ignored so far!
w/ #MinghaoGuo & @lbc1245 @payel791 #JieChen #WojciechMatusik
@MITIBMLab @MITCSAIL @IBMResearch
w/ #MinghaoGuo & @lbc1245 @payel791 #JieChen #WojciechMatusik
@MITIBMLab @MITCSAIL @IBMResearch




Retrieval-based models are increasingly important in NLP/QA. But an important factor in modeling text is knowing *where* it came from. Our #ICLR2022 paper proposes retrieval-based LMs considers the "structural locality" of texts to improve retrieval: arxiv.org/abs/2110.02870 🧵↓

We demonstrate this on two example datasets: Wikipedia articles and Java code. We leveraging the article and project structure respectively to define different "locality" levels between two documents.

Our analysis shows that the distance between embeddings, used widely in retrieval tasks, is *not* capturing this locality directly, so further improvements are needed. We do this by learning a function to adjust the distance metric for each locality level in KNN language models.


"A lot of AI research is about a kind of teaching-to-the-test." Insightful talk with Ted Chiang, sci-fi author and guest speaker to upcoming #ICLR2022 workshop, on #optimization, #intelligence, and the animal kingdom. @iclr_conf 1/4
Listen here:
Listen here:
"Most things that people deal with – the outcomes that we want – cannot be captured by an optimization function. Trying to view things as optimization problems is very often the wrong way to look at it." 2/4
"The endless capacity for expression is a big part of what enables collective learning – the ever growing sophistication of culture among humans." 3/4

Our paper “How Do Vision Transformers Work?” was accepted as a Spotlight at #ICLR2022!!
We show that the success of ViTs is NOT due to their weak inductive bias & capturing long-range dependency.
paper: openreview.net/forum?id=D78Go…
code & summary: github.com/xxxnell/how-do…
👇 (1/7)
We show that the success of ViTs is NOT due to their weak inductive bias & capturing long-range dependency.
paper: openreview.net/forum?id=D78Go…
code & summary: github.com/xxxnell/how-do…
👇 (1/7)
We address the following three key questions of multi-head self-attentions (MSAs) and ViTs:
Q1. What properties of MSAs do we need to better optimize NNs?
Q2. Do MSAs act like Convs? If not, how are they different?
Q3. How can we harmonize MSAs with Convs?
(2/7)
Q1. What properties of MSAs do we need to better optimize NNs?
Q2. Do MSAs act like Convs? If not, how are they different?
Q3. How can we harmonize MSAs with Convs?
(2/7)
Q1. What Properties of MSAs Do We Need?
MSAs have their pros and cons. MSAs improve NNs by flattening the loss landscapes. A key feature is their data specificity, not long-range dependency. On the other hand, ViTs suffers from non-convex losses.
(3/7)
MSAs have their pros and cons. MSAs improve NNs by flattening the loss landscapes. A key feature is their data specificity, not long-range dependency. On the other hand, ViTs suffers from non-convex losses.
(3/7)


The pretrain-then-finetune paradigm is a staple of transfer learning but is it always the right way to use auxiliary tasks? In our #ICLR2022 paper openreview.net/forum?id=2bO2x…, we show that in settings where the end-task is known in advance, we can do better.
[1/n]
[1/n]

@gneubig @atalwalkar @pmichelX TL;DR, instead of decoupled pretrain-then-finetune, we multitask the end-task with the auxiliary objectives. We use meta-learning to determine end-task and auxiliary task weights. Our approach improves performance and data-efficiency in low-resource settings.
[2/n]
[2/n]
@gneubig @atalwalkar @pmichelX Consider this common scenario. You have an end-task, E (say sentiment classification on movie reviews), and a set of auxiliary objectives, A, (eg MLM on generic or task data) you believe can improve results on E.
[3/n]
[3/n]

(1/N) Happy to share my first machine learning conference paper as a Ph.D. student. "Auto-Transfer: Learning to Route Transferrable Representations" accepted at ICLR 2022 (@iclr_conf). @IBMResearch @csatrpi @rpi #MachineLearning #iclr2022
arxiv: arxiv.org/abs/2202.01011
arxiv: arxiv.org/abs/2202.01011

(2/N) Knowledge transfer between heterogeneous source and target networks/tasks has received a lot of attention in recent times. We answer the following questions in this paper. 1) What knowledge to transfer? 2) Where to transfer? 3) How to transfer the source knowledge?
(3/N) To address "What knowledge to transfer?" and "Where to transfer?", we propose an adversarial multi-armed bandit (AMAB) that learns the parameters of our routing function.

How can we make neural networks learn both the knowns and unknowns? Check out our #ICLR2022 paper “VOS: Learning What You Don’t Know by Virtual Outlier Synthesis”, a general learning framework that suits both object detection and classification tasks. 1/n
arxiv.org/abs/2202.01197
arxiv.org/abs/2202.01197

(2/) Joint work with @xuefeng_du @MuCai7. Deep networks often struggle to reliably handle the unknowns. In self-driving, an object detection model trained to recognize known objects (e.g., cars, stop signs) can produce a high-confidence prediction for an unseen object of a moose.
(3/) The problem arises due to the lack of knowledge of unknowns during training time. Neural networks are typically optimized only on the in-distribution data. The resulting decision boundary, despite being useful on ID tasks, can be ill-fated for OOD detection. See Figure 1(b).

Excited to announce that my paper with @maurice_weiler on Steerable Partial Differential Operators has been accepted to #iclr2022! Steerable PDOs bring equivariance to differential operators. Preprint: arxiv.org/abs/2106.10163 (1/N)

Equivariance has become a popular topic in deep learning, but it has played a huge role in physics long before that. So wouldn't it be great if we could bring equivariant deep learning and physics closer together, to transfer more ideas? (2/N)
The issue is that equivariant NNs are usually defined using convolutions, whereas physics is described in the language of equivariant partial differential operators (PDOs). Our paper bridges that gap by developing the theory of equivariant PDOs in a deep learning setting. (3/N)
