Discover and read the best of Twitter Threads about #brms
Most recents (13)

1/ Mixed models are a powerful statistical tool for analyzing complex data with both fixed and random effects. R has several great packages for fitting mixed models. #rstats #datascience 

2/ One of the most popular packages for mixed models in R is "lme4". This package provides functions for fitting linear and generalized linear mixed models, including models with crossed and nested random effects. #rstats #lme4 cran.r-project.org/web/packages/l…
3/ Another popular mixed model package in R is "nlme". It has similar functionality to "lme4" but is designed to handle longitudinal or repeated-measures data. #rstats #nlme cran.r-project.org/web/packages/n…
1/ Bayesian inference is a powerful statistical framework that allows us to estimate the probability distribution of parameters based on data and prior knowledge. And R has a variety of packages for implementing Bayesian analysis! #rstats #datascience #Bayesian

Tricky Bayesian #rstats #brms methods question! I'm building a predictive model for a strangely-distributed outcome—it's a count with a bunch of 1s, a bunch of 32s (the max) and some numbers in between. How do you model this weird thing?! (reprex here: gist.github.com/andrewheiss/33…)

- I can subtract 1 from the outcome and use zero-inflated poisson to pick up the excess 1s, but there's no such thing as "1-and-32-inflated poisson" like zero-one-inflated beta, and the pp_check is awful
- I can use a mixture of two poisson models, but pp_check is bad+ESS bad
- I can use a mixture of two poisson models, but pp_check is bad+ESS bad


- I can collapse all the 2–31 counts into a category and just do ordered logit with 1, 2–31, and 32 as categories, but collapsing like that feels icky



Do choirs have accents?
Now I am 3 years into the PhD I have some thoughts I would like to share with you…
Here’s a wee thread🧵#AcademicChatter #AcademicTwitter #SingingResearch #SpheresOfSinging
1\
Now I am 3 years into the PhD I have some thoughts I would like to share with you…
Here’s a wee thread🧵#AcademicChatter #AcademicTwitter #SingingResearch #SpheresOfSinging
1\
Why?
Over 2 million people sing in choirs every week in the UK.
Everyone has an accent - and accents can differ by many different social factors (incl. region, age, gender, education and more).
\2
Over 2 million people sing in choirs every week in the UK.
Everyone has an accent - and accents can differ by many different social factors (incl. region, age, gender, education and more).
\2
Choir directors anecdotally report differences in choir sound by region. And, in musicology, Classical singing technique™ and choral singing has been associated with Received Pronunciation AKA “the Queen’s English”.
\3
\3

Volume 100 of @jstatsoft: Software for Bayesian Statistics
Guest editors: @micameletti & @precariobecario
20 contributions on a wide range of methods #rstats #python #bayesian #inla @mcmc_stan #nimble #brms #rjags
URL: jstatsoft.org/v100
Guest editors: @micameletti & @precariobecario
20 contributions on a wide range of methods #rstats #python #bayesian #inla @mcmc_stan #nimble #brms #rjags
URL: jstatsoft.org/v100

Van Niekerk, Bakka, Rue, Schenk:
New Frontiers in Bayesian Modeling Using the INLA Package in R
#rstats #inla #bayesian
doi.org/10.18637/jss.v…
New Frontiers in Bayesian Modeling Using the INLA Package in R
#rstats #inla #bayesian
doi.org/10.18637/jss.v…
Michaud, De Valpine, Turek, Paciorek, Nguyen:
Sequential Monte Carlo Methods in the nimble and nimbleSMC R Packages
#rstats #bayesian #nimble
doi.org/10.18637/jss.v…
Sequential Monte Carlo Methods in the nimble and nimbleSMC R Packages
#rstats #bayesian #nimble
doi.org/10.18637/jss.v…

Conversation is a dance, how do we learn? In this systematic review & meta-analysis we thoroughly explore models & evidence for how turn-taking develops and which factors are involved. Comments & suggested pub venues are very welcome. Long thread 1/ psyarxiv.com/3bak6

This was a brilliant student-led project by Vivian Nguyen & Otto Versyp from Ghent University, who spent their Fall 20 on an internship (aka regularly zooming) with me and @ChrisMMCox 2/
Turn taking is a very fascinating phenomenon. @Evol_of_Com & @Sonja_Vernes argue that it might be a cornerstone for animal communication in a very inspiring paper (royalsocietypublishing.org/doi/full/10.10…) 3/
The Puzzle of Danish: a thread on taking linguistic diversity seriously to highlight the flexibility of human cognition.
1/n
1/n

TLDR: Danish has an unusual speech opacity (consonant reduction). Danish native speakers rely more strongly on context and top-down inference. They also create more redundant speech and repeat each other more: a richer context for top-down speech processing. 2/n
The Puzzle of Danish is a project funded by the Danish council for independent research involving (besides me) @MH_Christiansen, @kristian_tylen, Dorthe Bleses, Anders Højen, Christer Johansson, @ChrisDideriksen, @fabio_trecca and @byureka . 3/n

TLDR: we applied cognitive science & cultural evolution to investigate some of the earliest human engravings (100k year old), finding that they were likely used to express implicit style and human intent. Background, pics and nerdy methodological observations in the thread. 1/n
After a long journey "The evolution of human symbolic behavior in Homo sapiens" is finally out in PNAS. The international interdisciplinary group included
@kristian_tylen, @johannsen_niels, @ARCHAEOfelix, @katheimann, @Nicolas_Fay, @SergioGdlR and Marlize Lombard. 2/n
@kristian_tylen, @johannsen_niels, @ARCHAEOfelix, @katheimann, @Nicolas_Fay, @SergioGdlR and Marlize Lombard. 2/n
Here a picture of (most of) the team getting familiar with an ancient (200k) ochre production site. 3/n


Pleased to announce that #tidybayes v2.0 (SLABS FOR DAYS edition) hit CRAN today. #rstats
Lots of new stuff in this version: A THREAD
Lots of new stuff in this version: A THREAD
The biggest thing is the new slab+interval meta-geom, generalizing old #tidybayes geoms and enabling a bunch of new ones. This is a flexible FAMILY of #ggplot geoms for visualizing probability distributions and uncertainty using slabs (densities, cdfs, etc), points, and intervals
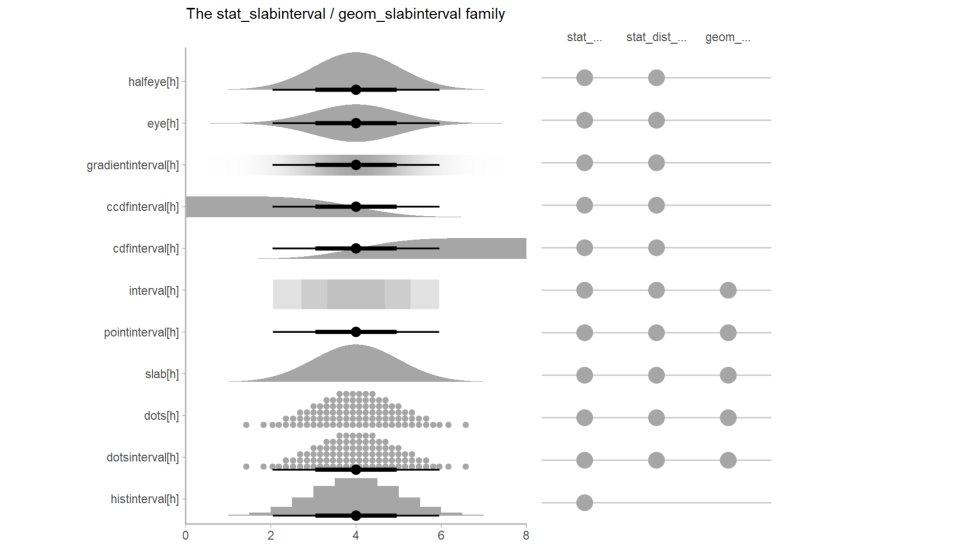
The slab+interval meta-geom now drives old standards like eyes and half-eyes...


I've made a cheat sheet and a bunch of applets to give you an intuitive feel for various reaction time distributions. You can choose datasets, fiddle with parameters, and see working code examples: lindeloev.net/shiny/rt/ 1/n
You can choose among several pre-existing datasets, e.g., by @EJWagenmakers and @JeffRouder. You can also copy-paste in your own data and try fitting different distributions. 2/n
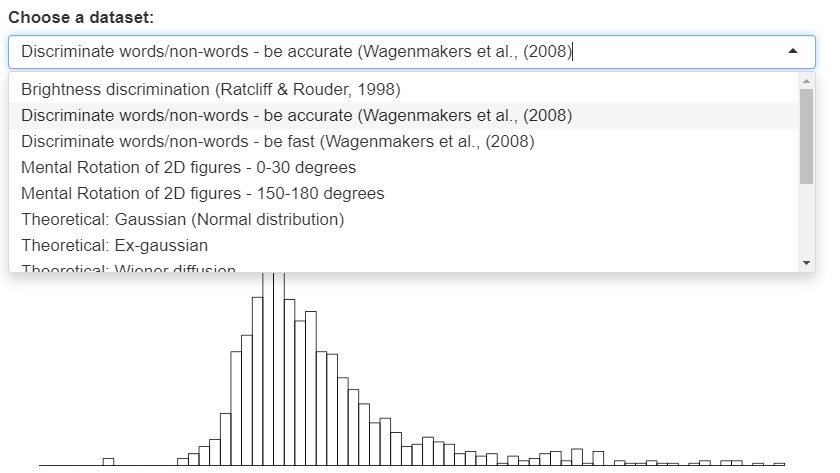
For example, take the Ratcliff diffusion model for a spin. You can upload your own data to see if it fits. Or you can plug in some parameters from a paper to get an intuition about their findings. 3/n

Morning of exam grading. I'm quite impressed by what open science is allowing students to do. So far: scales of chronic fatigue overlapping (building on @EikoFried's code), mixed strategies of social learning (based on @_lrendell and Galesic/Barkoczi codes)
@EikoFried @_lrendell and of course I almost overlooked how incredibly enabling #brms, @mcmc_stan tidyverse, #rstats, @rstudio, #oTree, #Python and @psychopy are. what my students are doing was basically impossible for the average students in my uni years (early 2000's)
@EikoFried @_lrendell So much more good stuff! More on critical social learning in agent-based-models (ABM). A study building on a simplified version of @bahadorbahrami's Optimally Interacting Minds to investigate gender bias, then implementing the empirical biases in this ABM: github.com/penelopy/bias_…
The R syntax for mixed models, "y ~ 1 + a*b + (1|id)", has two origins. The fixed part is Wilkinson notation from 1973: jstor.org/stable/2346786. The random part was introduced in the nlme package in the late 90s: stats.stackexchange.com/a/285026. It doesn't have a name. 1/5
History confirmed by nlme- and lmer-author Douglas Bates (@BatesDmbates): . So we may call it *Wilkinson-Bates notation* 2/5
It's now being massively extended in #brms. Check out this crazy mixed-effects meta-analysis w. censored y predicted by missing + monotonic + measurement error:
y | se(y_se) + cens(y_cens) ~ mi(a) + mo(b) + me(c, c_se) + (1|study)
Bayes --> infinite power! @BayesDose 3/5
y | se(y_se) + cens(y_cens) ~ mi(a) + mo(b) + me(c, c_se) + (1|study)
Bayes --> infinite power! @BayesDose 3/5

1/n
Someone asked me recently what resources I’d recommend for furthering one’s introduction to Bayesian statistics after going through @rlmcelreath's text (xcelab.net/rm/statistical…) and my accompanying project (bookdown.org/connect/#/apps…).
Here are my thoughts:
Someone asked me recently what resources I’d recommend for furthering one’s introduction to Bayesian statistics after going through @rlmcelreath's text (xcelab.net/rm/statistical…) and my accompanying project (bookdown.org/connect/#/apps…).
Here are my thoughts:
2/n
It probably goes without saying, but just in case you missed it, make sure you check out McElreath’s lectures on his text, too youtube.com/channel/UCNJK6…. He has three semester’s worth and they’re overall really great.
It probably goes without saying, but just in case you missed it, make sure you check out McElreath’s lectures on his text, too youtube.com/channel/UCNJK6…. He has three semester’s worth and they’re overall really great.
3/n
And plus, I also like his sand-alone lecture on “Bayesian Statistics without Frequentist Language” . It’s more conceptual than applied, but we could all probably do with a little more philosophy of statistics in our lives.
And plus, I also like his sand-alone lecture on “Bayesian Statistics without Frequentist Language” . It’s more conceptual than applied, but we could all probably do with a little more philosophy of statistics in our lives.
