Discover and read the best of Twitter Threads about #apachespark
Most recents (4)

🎯 You should know 7 things to become successful in
#dataengineering career 🔥
📌 Credit - Shri Ajay Kadiyala ji ✅
🧵👇
#dataengineering career 🔥
📌 Credit - Shri Ajay Kadiyala ji ✅
🧵👇

📍 The need for data compression📍
🧵
When we talk about computation time we are also talking about money, data compression represents the most appropriate economic way to shorten the gap between content creators and content consumers.
🧵
When we talk about computation time we are also talking about money, data compression represents the most appropriate economic way to shorten the gap between content creators and content consumers.
Compressed files are obviously smaller and it is necessary less money and time to transfer them and cost less money to store them, content creators pay less money to distribute their content, and content consumers pay less money to consume content.
On the other hand, companies in all sectors need to find new ways to control the rapid growth of their data heterogeneous generated every day, data compression and decompression techniques are one of the most viable solutions to these problems. #bigdata

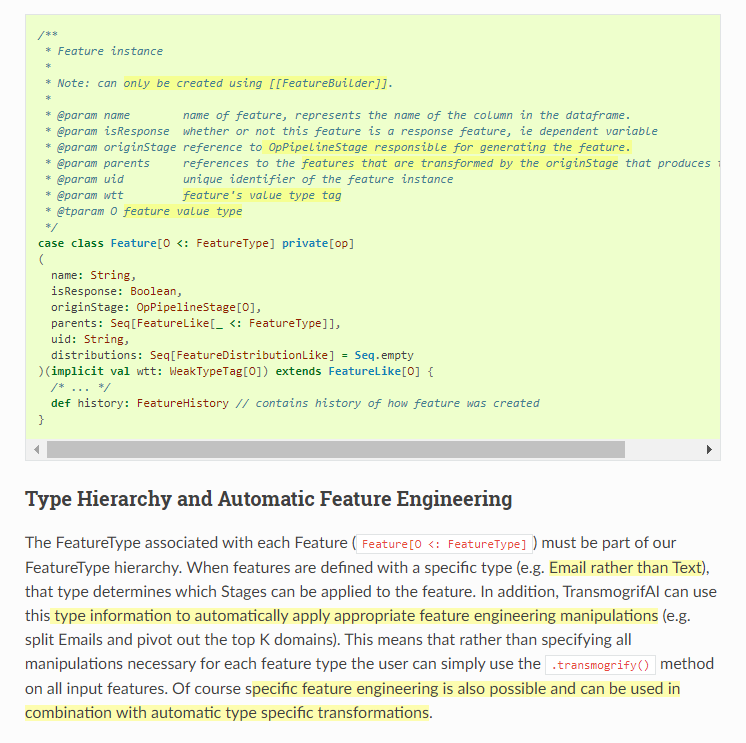
#TransmogrifAI #Scala #DSL over #ApacheSpark with rich functionality for #featureEngineering & #featureEvaluation and expressive typelevel / #functionalProgramming & design abstractions
docs.transmogrif.ai/en/stable/deve…
#MachineLearningEngineering
#WorkflowManagement #StateManagement
docs.transmogrif.ai/en/stable/deve…
#MachineLearningEngineering
#WorkflowManagement #StateManagement

Hypothesis: #TransmogrifAI with #workflowManagement done on #Cloudflow (#MLOps over #Kubernetes) could be functionally superior to "#Kubeflow Pipelines" because would allow more complex orchestrations, beyond Spark only, through #Akka
@tovbinm thoughts?↕️
@tovbinm thoughts?↕️
@threadreaderapp unroll

2/ While Spark can be 10-100X faster than #Hadoop's #MapReduce, the analytic engines (MapReduce & Spark) have different use cases
3/ #apachespark built to sit on top of #Hadoop, b/c it's an analytic engine while #Hadoop is a #BigData file system and orchestrator
