Discover and read the best of Twitter Threads about #NeurIPS2019
Most recents (19)

Important work is happening in *Participatory ML* and in recognizing that AI ethics is about the *distribution of power*. I want to create a thread linking to some of this work 1/
Don’t ask if artificial intelligence is good or fair, ask how it shifts power. @radical_ai_'s essay in Nature is a great place to start: 2/
Also check out @radical_ai_'s talk from @QueerinAI #NeurIPS2019 on how ML shifts power, and on the questions we should be asking ourselves: 3/
If the idea of tech not being neutral is new to you, or if you think of tech as just a tool (that is equally likely to be used for good or bad), I want to share some resources & examples in this thread. Please feel free to suggest/add additional resources! 1/
A classic paper exploring this is "Do Artifacts Have Politics?" by Langdon Winner (written in 1980), on whether machines/structures/systems can be judged for how they embody specific types of power 2/
cc.gatech.edu/~beki/cs4001/W…
cc.gatech.edu/~beki/cs4001/W…
Surveillance technologies are aligned with power. The panopticon is not going to be used to hold the warden accountable: 3/

Last week @AgnesSchim presented the first iteration of our ethics roadmap to the whole company. We might still be pre-series A but we believe ethics needs to be baked in from the start!
A thread 🧵
A thread 🧵
Last year we codified the values and principles that guide our work as a mission-driven company.
As we continue developing our products and ML we are now taking the next steps to integrate ethical considerations into our daily operations.
As we continue developing our products and ML we are now taking the next steps to integrate ethical considerations into our daily operations.
After her research last summer on #AIEthics for systemic issues (paper presented at #NeurIPS2019 workshop) @AgnesSchim built on this to develop an internal ethics framework to uphold those principles and embed them in the company.

Survey of #MachineLearning experimental methods (aka "how do ML folks do their experiments") at #NeurIPS2019 and #ICLR2020, a thread of results:
1. "Did you have any experiments in your paper?"
The future is empirical! If we historically look at NeurIPS papers (not just 2019), the number of theoretical submissions is dwindling and now almost relegated to conferences like UAI, and that's unfortunate.
The future is empirical! If we historically look at NeurIPS papers (not just 2019), the number of theoretical submissions is dwindling and now almost relegated to conferences like UAI, and that's unfortunate.

side note: There was a time when folks used to say, "what experiments? It's a NIPS paper!" (also, I am a dinosaur).

Looking for a weekend/holiday read?
Happy to share this major update of our #NeurIPS2019 #ML4PS workshop paper on chemical reaction classificaction (but not only.. 🧪⚗️🌍). @IBMResearch @unibern #compchem #RealTimeChem
Summary thread ⬇️:
Happy to share this major update of our #NeurIPS2019 #ML4PS workshop paper on chemical reaction classificaction (but not only.. 🧪⚗️🌍). @IBMResearch @unibern #compchem #RealTimeChem
Summary thread ⬇️:
We compared different RXN classification methods. 📍Using a BERT model borrowed from NLP, we matched the ground truth (Pistachio, @nmsoftware) with an accuracy of 98.2%.

We did not only visualize what was important for the class predictions by looking at the different attention weights...


Bayesian methods are *especially* compelling for deep neural networks. The key distinguishing property of a Bayesian approach is marginalization instead of optimization, not the prior, or Bayes rule. This difference will be greatest for underspecified models like DNNs. 1/18
In particular, the predictive distribution we often want to find is p(y|x,D) = \int p(y|x,w) p(w|D) dw. 'y' is an output, 'x' an input, 'w' the weights, and D the data. This is not a controversial equation, it is simply the sum and product rules of probability. 2/18
Rather than betting everything on a single hypothesis, we want to use every setting of parameters, weighted by posterior probabilities. This procedure is known as a Bayesian model average (BMA). 3/18
Check out our work on Data-Driven Chemical Reaction Classification at the ML for Physical Sciences poster session (15.20-16.20, room 109) #NeurIPS2019 #compchem @IBMResearch

@IBMResearch @acvaucher @teodorolaino The reaction map was visualized using @skepteis's TMAP library (-> tmap.gdb.tools) @reymondgroup

Talk on Social Intelligence by Blaise is getting started now at West Hall C. #NeurIPS2019

Let’s start the conversation around of energy and natural resources

The importance of federated learning in ML

A few of my favorite posters from today. Lots of reading to do over the holidays. #NeurIPS2019




Some more:



And a few more:




Machine learning for single cell biology: insights and challenges by Dana Pe’er. #NeurIPS2019

The representation challenge

On visualizing and modeling the data



Bin Yu discussing three principles of data science and interpretable machine learning. #NeurIPS2019




Can we mitigate data perturbations related issues

We need proper documentation about how we tried to come up with results... few things to consider:


At the end of her #NeurIPS2019 talk on how we come to know about the world, @celestekidd takes a moment to comment on the "climate for men" that #MeToo has created and what people don't know about it. @NeurIPSConf @WomenInCogSci #WiML2019 @AnnOlivarius @ucberkely @BerkeleyPsych
In science and tech, "people believe that men are being fired for subtle comments or minor jokes, or just plain kindness or cordial behavior. This perception makes people very nervous. What I want to say today to all of the men in the room is that you have been misled."
"The truth is this: it takes an incredible--truly immense--amount of mistreatment before women complain. No woman in tech wants to file a complaint because they know the consequences of doing so. The most likely outcome---by far---is that they will be retaliated against."

Comparing distributions: Kernels estimate good representations, l1 distances give good tests
A simple summary of our #NeurIPS2019 work
gael-varoquaux.info/science/compar…
Given two set of observations, how to know if they are drawn from the same distribution? Short answer in the thread..
A simple summary of our #NeurIPS2019 work
gael-varoquaux.info/science/compar…
Given two set of observations, how to know if they are drawn from the same distribution? Short answer in the thread..
For instance, do McDonald’s and KFC use different logic to position restaurants? Difficult question! We have access to data points, but not the underlying generative mechanism, governed by marketing strategies.

To capture the information in the spatial proximity of data points, kernel mean embeddings are useful. They are intuitively related to Kernel Density Estimates


Excited to present at #NeurIPS2019 this week!! I identify challenges in hyperparameter search when training sequential autoencoders (SAEs) on sparse data such as neural spiking, and present new methods to address them.
Wed 10:45a, East B+C #138 👨💼
Paper: tinyurl.com/lfads-hp-opt
Wed 10:45a, East B+C #138 👨💼
Paper: tinyurl.com/lfads-hp-opt
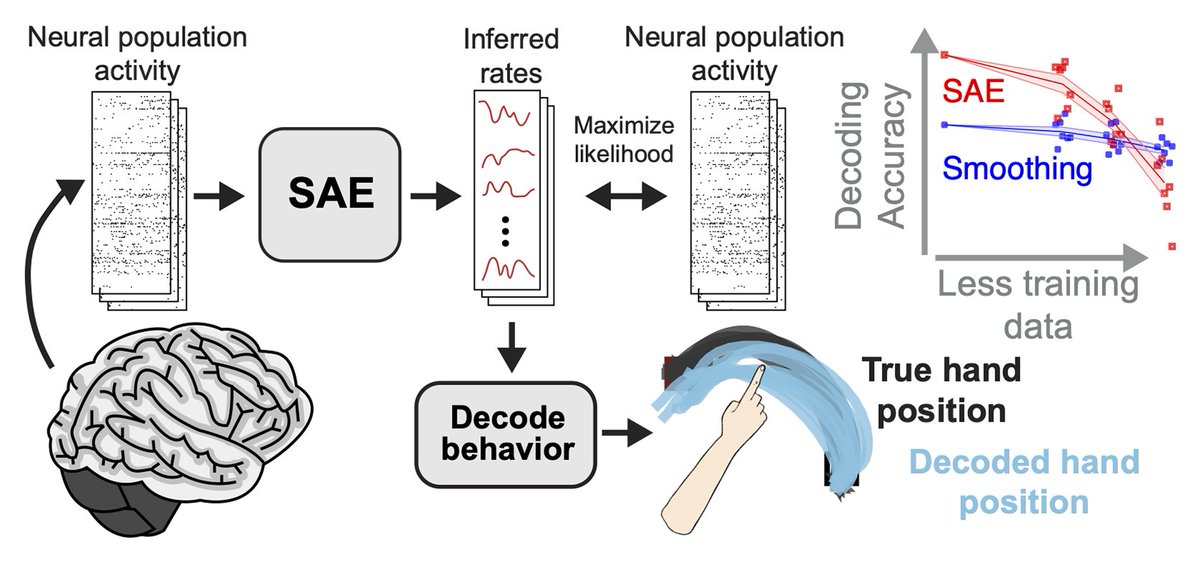
We use SAEs to model dynamics underlying neural population activity. With small datasets, hyperparameters (HPs) can be critical. But SAEs are prone to a type of overfitting that is challenging to detect, making it difficult to adjust HPs automatically.

We developed coordinated dropout (CD). CD forces a network to only model shared structure underlying the data. CD first passes in a subset of samples at the input. To update network weights, CD only uses gradients from reconstruction of the complementary subset of samples.


Why do deep ensembles trained with just random initialization work surprisingly well in practice?
In our recent paper arxiv.org/abs/1912.02757 with @stanislavfort & Huiyi Hu, we investigate this by using insights from recent work on loss landscape of neural nets.
More below:
In our recent paper arxiv.org/abs/1912.02757 with @stanislavfort & Huiyi Hu, we investigate this by using insights from recent work on loss landscape of neural nets.
More below:
@stanislavfort 2) One hypothesis is that ensembles may lead to different modes while scalable Bayesian methods may sample from a single mode.
We measure the similarity of function (both in weight space and function space) to test this hypothesis.
We measure the similarity of function (both in weight space and function space) to test this hypothesis.
@stanislavfort 3) t-SNE plot of predictions along training trajectories (marked by different colors) shows that random initialization leads to diverse functions. Sampling functions from a subspace corresponding to a single trajectory increases diversity but not as much as random init.

Learning to Predict Without Looking Ahead: World Models Without Forward Prediction
Rather than hardcoding forward prediction, we try to get agents to *learn* that they need to predict the future.
Check out our #NeurIPS2019 paper!
learningtopredict.github.io
arxiv.org/abs/1910.13038
Rather than hardcoding forward prediction, we try to get agents to *learn* that they need to predict the future.
Check out our #NeurIPS2019 paper!
learningtopredict.github.io
arxiv.org/abs/1910.13038
Work by @bucketofkets @Luke_Metz and myself.
Rather than assume forward models are needed, in this work, we investigate to what extent world models trained with policy gradients behave like forward predictive models, by restricting the agent’s ability to observe its environment.
Rather than assume forward models are needed, in this work, we investigate to what extent world models trained with policy gradients behave like forward predictive models, by restricting the agent’s ability to observe its environment.

@bucketofkets @Luke_Metz @NeurIPSConf Core idea: By not letting an agent observe (most of the time), it can be coerced into learning a world model to help fill in the gaps between observations.
It's like training a blindfolded agent to drive. Its world model realigns with reality when we let it observe (red frames):
It's like training a blindfolded agent to drive. Its world model realigns with reality when we let it observe (red frames):

Excited to share our blog on ~Discovering Neural Wirings~ expanding on recent work with Ali Farhadi & @morastegari to appear at #NeurIPS2019 (see thread below for more info)!
Blog: mitchellnw.github.io/blog/2019/dnw/
Preprint: arxiv.org/abs/1906.00586
Code: github.com/allenai/dnw
(1/4)
Blog: mitchellnw.github.io/blog/2019/dnw/
Preprint: arxiv.org/abs/1906.00586
Code: github.com/allenai/dnw
(1/4)
@morastegari Two cool takeaways:
1) In _some_ ways, the problem of NAS and sparse neural network learning are really two sides of the same coin. As NAS becomes more fine grained, finding a good architecture is akin to finding a sparse subnetwork of the complete graph.
(2/4)
1) In _some_ ways, the problem of NAS and sparse neural network learning are really two sides of the same coin. As NAS becomes more fine grained, finding a good architecture is akin to finding a sparse subnetwork of the complete graph.
(2/4)
@morastegari 2) It is still possible to play the initialization lottery (see arxiv.org/abs/1803.03635) with a combinatorial number of subnetworks even when the model is sparse.
(3/n)
(3/n)

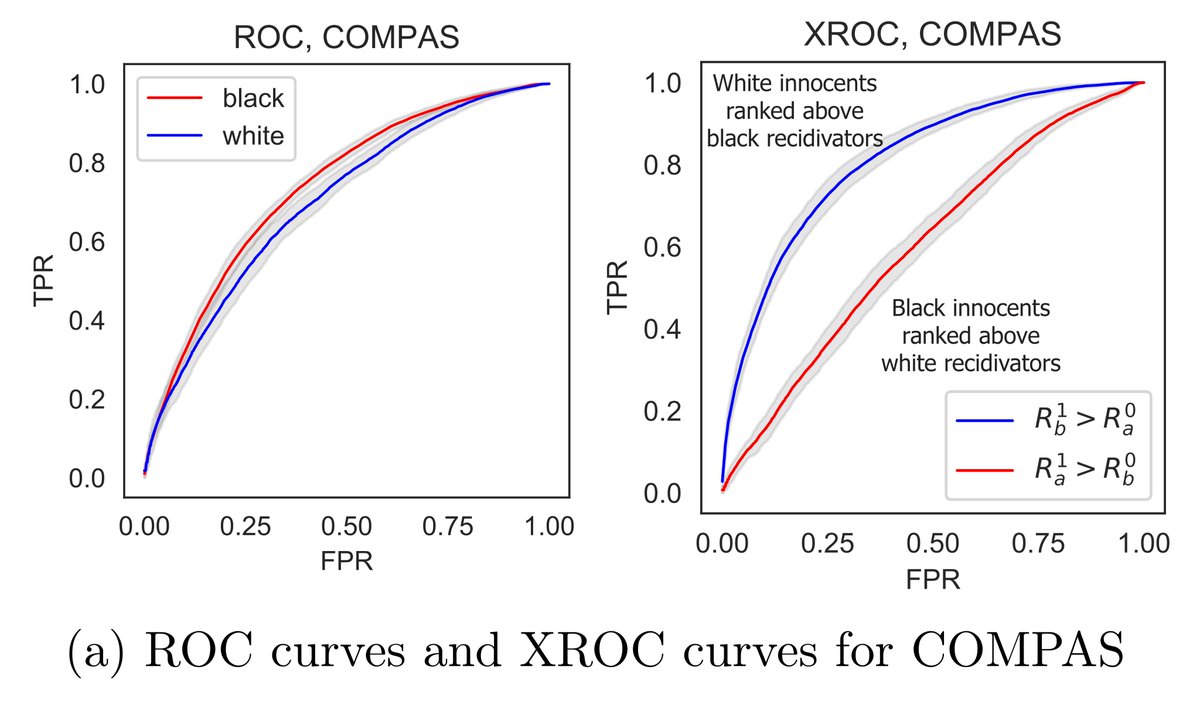
Assessing fairness of predictive risk scores requires us to think beyond binary classification. In arxiv.org/abs/1902.05826 we consider (un)fairness in bipartite ranking, where a natural metric, xAUC, arises for diagnosing disparities in risk scores algo @angelamczhou #NeurIPS2019
@angelamczhou Scores can have biases even when algo gives no clear binary decision (algos rarely make final decisions in civics). True story: Equivant (then Northpointe) pointed to overlapping ROCs to defend its COMPAS recidivism score. But xROC curves paint a different, more racist picture.
@angelamczhou The xROCs show that COMPAS is essentially random guessing when choosing whose riskier between a black non-recidivator and a white recidivator, but it makes damn sure to absolve white non-recidivators when compared to black recidivators. (Difference in probs = xAUC disparity)

#NeurIPS2018 is over! Time to wrap up!
In this thread I'll share what I found the most interesting in the field of ML and creativity.
Everything below worth your time IMO!
In this thread I'll share what I found the most interesting in the field of ML and creativity.
Everything below worth your time IMO!
First day, the talk by @viegasf & @wattenberg about DataVisualisation was excellent: theoretical and practical.
static.googleusercontent.com/media/research…
static.googleusercontent.com/media/research…
Fernanda Viega co-lead the People + AI Research team for Google Cambridge. She makes Art & Design Projects too. More here: fernandaviegas.com
