Discover and read the best of Twitter Threads about #NLProc
Most recents (24)

Excited to share our #NLProc #ACL2023NLP paper:
Controlled Text Generation with Hidden Representation Transformations
Work done during my applied scientist internship at @AmazonScience @alexa99 team.
Paper: arxiv.org/abs/2305.19230
Code: github.com/amazon-science… (Coming soon)
Controlled Text Generation with Hidden Representation Transformations
Work done during my applied scientist internship at @AmazonScience @alexa99 team.
Paper: arxiv.org/abs/2305.19230
Code: github.com/amazon-science… (Coming soon)

@AmazonScience @alexa99 LLMs are notoriously difficult to control. This work is an effort to fix that.
We create CHRT : a novel framework to attribute control LLMs using learned transformation blocks.
It can be used to minimize toxicity, maximize positive sentiment and more.
We create CHRT : a novel framework to attribute control LLMs using learned transformation blocks.
It can be used to minimize toxicity, maximize positive sentiment and more.

The approach has minimal loss in linguistic quality while achieving high attribute control.
Also has the least latency delta as compared to all other included baselines, something that makes it ideal for production environments.
Also has the least latency delta as compared to all other included baselines, something that makes it ideal for production environments.


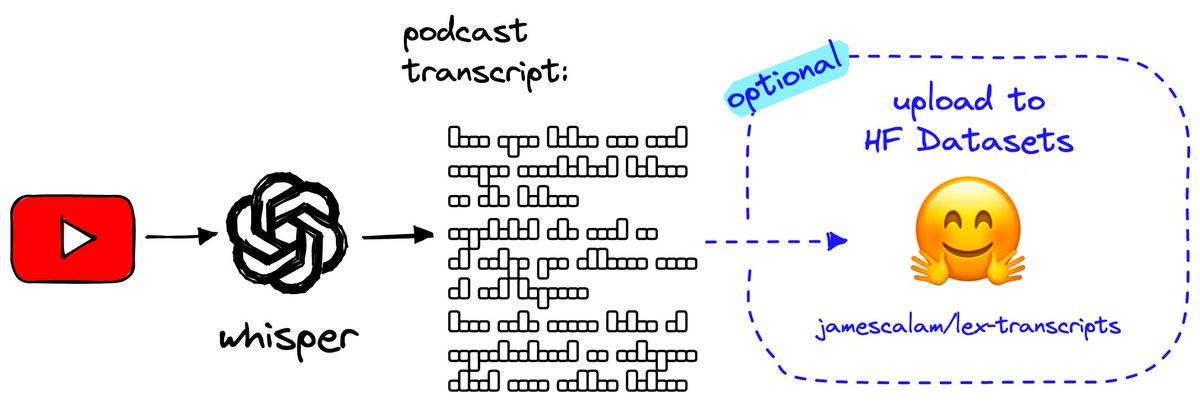
I built a ChatGPT @lex_fridman plugin that allows to chat with the collective wisdom contained across 499 of Lex's podcasts and videos... Here's how I built it 🧵
#ChatGPT #ArtificialIntelligence #nlproc #OPStack
#ChatGPT #ArtificialIntelligence #nlproc #OPStack
Started by:
- downloading Lex MP3s via @YouTube API
- transcribing audio to text with @OpenAI's large Whisper model
- (optional) hosted the new "lex-transcripts" dataset on @huggingface datasets!
- downloading Lex MP3s via @YouTube API
- transcribing audio to text with @OpenAI's large Whisper model
- (optional) hosted the new "lex-transcripts" dataset on @huggingface datasets!
‼️ The code for the next few steps can be found here:
github.com/pinecone-io/ex…
github.com/pinecone-io/ex…

Several things that can all be true at once:
1. Open access publishing is important
2. Peer review is not perfect
3. Community-based vetting of research is key
4. A system for by-passing such vetting muddies the scientific information ecosystem
1. Open access publishing is important
2. Peer review is not perfect
3. Community-based vetting of research is key
4. A system for by-passing such vetting muddies the scientific information ecosystem
Yes, this is both a subtweet of arXiv and of every time anyone cites an actually reviewed & published paper by just pointing to its arXiv version, just further lending credibility to all the nonsense that people "publish" on arXiv and then race to read & promote.
Shout out to the amazing @aclanthology which provides open access publishing for most #compling / #NLProc venues and to all the hardworking folks within ACL reviewing & looking to improve the reviewing process.

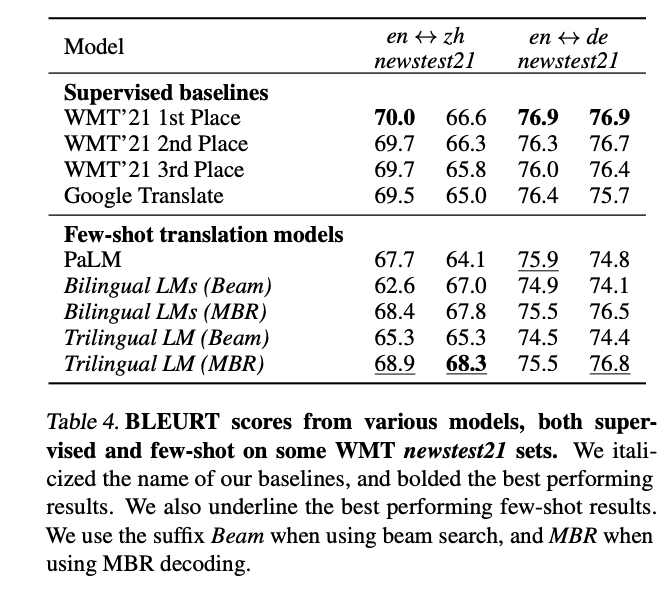
Few-shot learning almost reaches traditional machine translation
Xavier Garcia @whybansal @ColinCherry George Foster, Maxim Krikun @fengfangxiaoyu @melvinjohnsonp @orf_bnw
arxiv.org/abs/2302.01398
#enough2skim #NLProc #neuralEmpty
Xavier Garcia @whybansal @ColinCherry George Foster, Maxim Krikun @fengfangxiaoyu @melvinjohnsonp @orf_bnw
arxiv.org/abs/2302.01398
#enough2skim #NLProc #neuralEmpty
The setting is quite simple:
Take a smaller (8B vs 100-500B in some baselines)
bilingual LM in two languages (one might be low resource see fig)
Show it a few translation examples in the prompt
Say abra kadabra 🪄
and you got a very good translation system
Take a smaller (8B vs 100-500B in some baselines)
bilingual LM in two languages (one might be low resource see fig)
Show it a few translation examples in the prompt
Say abra kadabra 🪄
and you got a very good translation system

They reproduce known results and detail how to do it (especially for low resource)
e.g., continue previous training for speed\stability have many epochs on the monolingual training (fig)
etc.
e.g., continue previous training for speed\stability have many epochs on the monolingual training (fig)
etc.

We're seeing multiple folks in #NLProc who *should know better* bragging about using #ChatGPT to help them write papers. So, I guess we need a thread of why this a bad idea:
>>
>>
1- The writing is part of the doing of science. Yes, even the related work section. I tell my students: Your job there is show how your work is building on what has gone before. This requires understanding what has gone before and reasoning about the difference.
>>
>>
The result is a short summary for others to read that you the author vouch for as accurate. In general, the practice of writing these sections in #NLProc (and I'm guessing CS generally) is pretty terrible. But off-loading this to text synthesizers is to make it worse.
>>
>>
We want to pretrain🤞
Instead we finetune🚮😔
Could we collaborate?🤗
ColD Fusion:
🔄Recycle finetuning to multitask
➡️evolve pretrained models forever
On 35 datasets
+2% improvement over RoBERTa
+7% in few shot settings
🧵
#NLProc #MachinLearning #NLP #ML #modelRecyclying
Instead we finetune🚮😔
Could we collaborate?🤗
ColD Fusion:
🔄Recycle finetuning to multitask
➡️evolve pretrained models forever
On 35 datasets
+2% improvement over RoBERTa
+7% in few shot settings
🧵
#NLProc #MachinLearning #NLP #ML #modelRecyclying
We all wish to improve pretraining
If only we had unlimited compute and data...
Together we have!
We propose a way to recycle finetuning
and transform it into multitask learning!
arxiv.org/abs/2212.01378
@Shachar_Don @VenezianElad @colinraffel @noamslonim @YoavKatz73 me
If only we had unlimited compute and data...
Together we have!
We propose a way to recycle finetuning
and transform it into multitask learning!
arxiv.org/abs/2212.01378
@Shachar_Don @VenezianElad @colinraffel @noamslonim @YoavKatz73 me
How to perform multitasking, by simply uploading models?
Collaborative Descent (ColD) Fusion is simple:
Start from a pretrained model
Let contributors finetune on it, and share their models
Fuse the models to get a new better model
Take the improved model as the new best model
Collaborative Descent (ColD) Fusion is simple:
Start from a pretrained model
Let contributors finetune on it, and share their models
Fuse the models to get a new better model
Take the improved model as the new best model


Despite the amazing results I’ve experienced with ChatGPT, this is not a correct way to look at LLM vs. Google search. Since several other tweets have made this equivalence and have been eager to spell doom for Google, let’s examine the details:
1. Google has more LLMs deployed internally than any place I know. If private communication is to be believed that number is in the order of “few dozens”. Not talking of BERT/T5 sized models here.
2. Google also has more compute than anyone. The joke is only NSA probably has an estimate of Google’s compute. So they are not compute-limited to build as much big a model as they want.

Really enjoyed giving a talk today on #fakenews #linguistics for the Fakespeak project at the University of Oslo today. A quick 🧵...

My basic argument is that there a lots of definitions of Fake News out there and a taxonomy of fake news is therefore very useful to make sense of this situation and to theoretically ground our research...

The taxonomy I propose is based on the concepts of veracity (true/false news) and honesty (honest/dishonest news), which I argue are independent concepts.


Sentence embeddings (e.g., SBERT) are powerful -- but we just don't know what is crammed into a %&!$# vector 😵💫.
💥So in our new paper, we use Abstract Meaning Representation (AMR) to make sentence embeddings more explainable! #AACL2022 #nlproc #MachineLearning (1/3)
💥So in our new paper, we use Abstract Meaning Representation (AMR) to make sentence embeddings more explainable! #AACL2022 #nlproc #MachineLearning (1/3)

Interesting: Yes, we use AMR -- but we don't need an AMR parser🤯. Therefore, we don't lose efficiency 🚀. The accuracy 🎯 is also preserved, and sometimes even improved (for argument similarity, we achieve a new state-of-the-art). (2/3)

We suffered through curating and analysing thousands of benchmarks -- to better understand the (mis)measurement of AI! 📏🤖🔬
We cover all of #NLProc and #ComputerVision.
Now live at @NatureComms! nature.com/articles/s4146…
1/
We cover all of #NLProc and #ComputerVision.
Now live at @NatureComms! nature.com/articles/s4146…
1/

Benchmarks are crucial to measuring and steering AI progress.
Their number has become astounding.
Each has unique patterns of activity, improvement and eventual stagnation/saturation. Together they form the intricate story of global progress in AI. 🌐
2/
Their number has become astounding.
Each has unique patterns of activity, improvement and eventual stagnation/saturation. Together they form the intricate story of global progress in AI. 🌐
2/

We found a sizable portion of benchmarks have kind of reached saturation ("can't get better than this") or stagnation ("could get better, but we don't know how / nobody tries"). But still a lot of dynamic benchmarks as well!
3/
3/


Happy to release GOAL ⚽️, a multimodal dataset based on football highlights that includes 1) videos, 2) human transcriptions, and 3) Wikidata-based KB with statistics about players and teams for every match.
arxiv.org/abs/2211.04534
Interested? Read the thread below! #NLProc
arxiv.org/abs/2211.04534
Interested? Read the thread below! #NLProc
[1/7] Previous video benchmarks consider movies or TV series that typically involve scripted interaction between characters instead of visually grounded language. On the other hand, in GOAL we focus on football commentaries because they involve visually grounded language

[2/7]: GOAL pushes the boundaries of current multimodal models because it requires the encoding of 1) videos; 2) commentary; 3) KB information. All these elements are essential when generating a sound and coherent commentary for a football video.


Can instruction tuning improve zero and few-shot performance on dialogue tasks? We introduce InstructDial, a framework that consists of 48 dialogue tasks created from 59 openly available dialogue datasets
#EMNLP2022🚀
Paper 👉 arxiv.org/abs/2205.12673
Work done at @LTIatCMU
🧵👇
#EMNLP2022🚀
Paper 👉 arxiv.org/abs/2205.12673
Work done at @LTIatCMU
🧵👇

Instruction tuning involves fine-tuning a model on a collection of tasks specified through natural language instructions (T0, Flan models). We systematically studied instruction tuning for dialogue tasks and show it works a lot better than you might expect!
The InstructDial framework consists of 48 diverse dialogue tasks varying from classification, grounded and controlled generation, safety, QA, pretraining, summarization, NLI, and other miscellaneous tasks. All tasks are specified through instructions in a seq-2-seq format.


ITT: an OAI employee admits that the text-davinci API models are not from their papers.
Until @OpenAI actually documents the connection between the models in their papers and the models released via APIs, #NLProc researchers need to stop using them to do research.
Until @OpenAI actually documents the connection between the models in their papers and the models released via APIs, #NLProc researchers need to stop using them to do research.
@OpenAI This is not a minor point either. Apparently the text-davinci-002 API “is an instruct model. It doesn't uses a similar but slightly different [sic] training technique but it's not derived from davinci. Hence it's not a fair comparison.”
@OpenAI Note that the text-davinciplus-002 model that he mentions isn’t publicly available AFAIK. So external researchers trying to study the InstructGPT models not only are running the wrong models, but they can’t study the correct ones.
People often ask me if I think computers could ever understand language. You might be surprised to hear that my answer is yes! My quibble isn't with "understand", it's with "human level" and "general".
>>
>>
To answer that question, of course, we need a definition of understanding. I like the one from Bender & @alkoller 2020: Meaning is the relationship between form and something external to language and understanding is retrieving that intent from form.
>>
>>

So when I ask a digital voice assistant to set a timer for a specific time, or to retrieve information about the current temperature outside, or to play the radio on a particular station, or to dial a certain contact's phone number and it does the thing: it has understood.
>>
>>
This article in the Atlantic by Stephen Marche is so full of #AIhype it almost reads like a self-parody. So, for your entertainment/education in spotting #AIhype, I present a brief annotated reading:
theatlantic.com/technology/arc…
/1
theatlantic.com/technology/arc…
/1
Straight out of the gate, he's not just comparing "AI" to "miracles" but flat out calling it one and quoting Google & Tesla (ex-)execs making comparisons to "God" and "demons".
/2
/2

This is not the writing of someone who actually knows what #NLProc is. If you use grammar checkers, autocorrect, online translation services, web search, autocaptions, a voice assistant, etc you use NLP technology in everyday life. But guess what? NLP isn't a subfield of "AI".
/3
/3

Language Models have taken #NLProc by storm. Even if you don’t directly work in NLP, you have likely heard and possibly, used language models. But ever wonder who came up with the term “Language Model”? Recently I went on that quest, and I want to take you along with me. 🧶
I am teaching a graduate-level course on language models and transformers at @ucsc this Winter, and out of curiosity, I wanted to find out who coined the term “Language Model”.
First, I was a bit ashamed I did not know this fact after all these years in NLP. Surely, this should be in any NLP textbook, right? Wrong! I checked every NLP textbook I could get my hands on, and all of them define what an LM is, without giving any provenance to the term.

I finally read @boazbaraktcs’s blog on DL vs Stats.
A great mind-clearing read! 👍
“Yes, that was how we thought about NNs losing out due to bias/variance in ~2000”
“Yes, pre-trained models really are different to classical stats, even if math is the same”
windowsontheory.org/2022/06/20/the…
A great mind-clearing read! 👍
“Yes, that was how we thought about NNs losing out due to bias/variance in ~2000”
“Yes, pre-trained models really are different to classical stats, even if math is the same”
windowsontheory.org/2022/06/20/the…
A bit more nuance could be added to this 2nd para on Supervised Learning. Initial breakthroughs _were_ made in #NLProc via unsupervised learning prior to AlexNet—the word vectors of Collobert&Weston (2008/2011) like related stuff in RBMs, Google cat, etc. jmlr.org/papers/volume1…

But, for a few years, the siren song of the effectiveness of end-to-end deep learning on large supervised datasets was irresistible and very successful, probably partly because of how, in the over-parameterized regime, it does do representation learning as this post argues.

📢 Today we officially launch TweetNLP, an all-round NLP platform for social media. From sentiment analysis to emoji prediction and more 🔥🔥
✔️ TweetNLP includes a Python API, a demo and tutorials. Useful for developers and researchers alike. Want to know more? 🧵
✔️ TweetNLP includes a Python API, a demo and tutorials. Useful for developers and researchers alike. Want to know more? 🧵

Everything you need is at ➡️tweetnlp.org⬅️
TweetNLP is powered by relatively light-weight transformer-based language models, which can be run on most computers or free cloud services.
So, what’s in it for you? 👇
TweetNLP is powered by relatively light-weight transformer-based language models, which can be run on most computers or free cloud services.
So, what’s in it for you? 👇
1⃣ <Python API>
Step 1: pip install tweetnlp
Step 2: import tweetnlp
Step 3: model = tweetnlp.load('sentiment')
Step 4: model.sentiment("We love NLP!🥰")
github.com/cardiffnlp/twe…
Step 1: pip install tweetnlp
Step 2: import tweetnlp
Step 3: model = tweetnlp.load('sentiment')
Step 4: model.sentiment("We love NLP!🥰")
github.com/cardiffnlp/twe…

Can your encoder-decoder model generate a database-like table? We intended to do it efficiently and ended up with the STable🐴framework applicable to problems such as extraction of line items or joint entity and relation extraction.
See arxiv.org/abs/2206.04045 and 🧵
#NLProc
See arxiv.org/abs/2206.04045 and 🧵
#NLProc

From receipts and invoices, through paycheck stubs and insurance loss run reports, to scientific articles, real-world documents contain explicitly or implicitly tabular data to be extracted. These are not necessarily represented as a table per se within the input document.

At the same time, encoder-decoder models unify a variety of NLP problems by casting them as QA with a plain-text answer. We argue that the restriction of output type to raw text is sometimes suboptimal and propose a framework able to infer a list of ordered tuples or a table.

Excited to share RankGen, a 1.2B param contrastive encoder mapping prefixes & model generations to vectors.
✅ large improvements over nucleus/typical sampling
✅ score & rank generations from any LM
✅ human eval with writers
✅ HuggingFace ckpts, code👇
arxiv.org/abs/2205.09726
✅ large improvements over nucleus/typical sampling
✅ score & rank generations from any LM
✅ human eval with writers
✅ HuggingFace ckpts, code👇
arxiv.org/abs/2205.09726
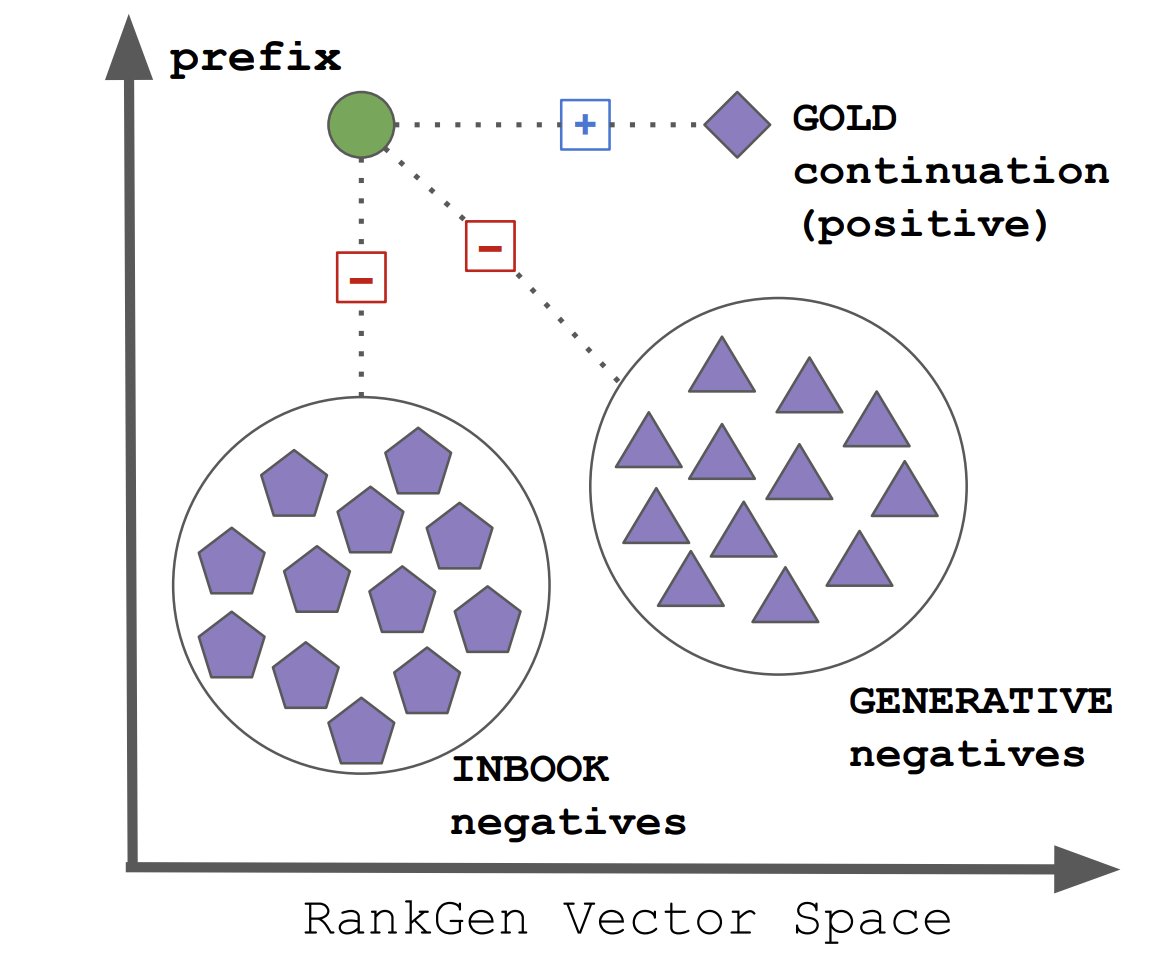
Despite great progress, text generation continues to underperform. Even large LMs generate text that has hallucination, poor continuity etc.
Part of the issue is LMs are trained to predict the next one token given the ground truth prefix, encouraging reliance on local context.
Part of the issue is LMs are trained to predict the next one token given the ground truth prefix, encouraging reliance on local context.

To tackle this we build RankGen, which map prefixes close to their gold continuation, but away from other continuations in the same document, as well as model-generations from a large LM.
We train RankGen using large-scale contrastive learning with minibatch size of 3K.
We train RankGen using large-scale contrastive learning with minibatch size of 3K.


Ever wondered what it takes to build an intelligent Q/A assistant? 🤔
@OpenAI #gpt3 and a few hours is all you need!
🤯 Yes, you heard it right!
🕹 Built a #javascript wizard using @streamlit to answer all your queries like a human expert!
A thread 🧵
#nlproc #AI #lowcode
@OpenAI #gpt3 and a few hours is all you need!
🤯 Yes, you heard it right!
🕹 Built a #javascript wizard using @streamlit to answer all your queries like a human expert!
A thread 🧵
#nlproc #AI #lowcode
@OpenAI @streamlit Gone are the days when you had to spend hours on @StackOverflow for resolving code-related queries!
🪄 Javascript wizard gives you precise answers to all your #JS related questions by leveraging #gpt3's latest code-davinci model that understands your queries just like humans!
🪄 Javascript wizard gives you precise answers to all your #JS related questions by leveraging #gpt3's latest code-davinci model that understands your queries just like humans!
@OpenAI @streamlit @StackOverflow I have made the application code #OpenSource so you can just clone the repo and build #gpt3 powered #AI applications for your usecase!
👨💻 GitHub Repo - github.com/Shubhamsaboo/j…
#NLP #lowcode #nlproc
👨💻 GitHub Repo - github.com/Shubhamsaboo/j…
#NLP #lowcode #nlproc
How to make your weekend productive? 🤔
🕹 Build an end-to-end neural search engine in #Python using @JinaAI_
🤯 Yes, you heard it right!
@JinaAI_'s DocArray library and a few hours is all you need to build a complete search solution!
A thread 🧵
#nlproc #OpenSource #AI
🕹 Build an end-to-end neural search engine in #Python using @JinaAI_
🤯 Yes, you heard it right!
@JinaAI_'s DocArray library and a few hours is all you need to build a complete search solution!
A thread 🧵
#nlproc #OpenSource #AI
@JinaAI_ Neural search lets you improve search relevance by understanding the intent and going beyond the conventional keyword-based search!
Some common applications are:
👉 Q/A chatbots
👉 Voice assistants like #alexa #siri
👉 Recommendation system by @netflix
Some common applications are:
👉 Q/A chatbots
👉 Voice assistants like #alexa #siri
👉 Recommendation system by @netflix

Check out this blog to build a semantic search engine for textual data.
It will walk you through the steps to build your first neural search application in no time!
#python #artificialintelligence #nlproc #OpenSource #datascience #lowcode
shubhamsaboo111.medium.com/build-neural-t…
It will walk you through the steps to build your first neural search application in no time!
#python #artificialintelligence #nlproc #OpenSource #datascience #lowcode
shubhamsaboo111.medium.com/build-neural-t…

Annotation guidelines for ML 101 (basic concepts) 🧵
✨ The results of supervised learning approaches are only as good as the annotations they are based on.
✨ Annotations are only as good as the guidelines that annotators rely upon to direct their efforts.
⬇️
✨ The results of supervised learning approaches are only as good as the annotations they are based on.
✨ Annotations are only as good as the guidelines that annotators rely upon to direct their efforts.
⬇️
What is data annotation? 🪄
✨It is the task of associating entries in your data with additional information
✨It is also known as "coding" or "labeling"
✨It is crucial for both qualitative and quantitative analyses
⬇️
✨It is the task of associating entries in your data with additional information
✨It is also known as "coding" or "labeling"
✨It is crucial for both qualitative and quantitative analyses
⬇️
Supervised learning basics 🤖
✨ In AI, data annotation is the bases for the supervised learning approach
✨ Supervised learning uses annotated datasets or collections of data points with associated labels
✨ The model learns to predict labels from these annotated datasets
⬇️
✨ In AI, data annotation is the bases for the supervised learning approach
✨ Supervised learning uses annotated datasets or collections of data points with associated labels
✨ The model learns to predict labels from these annotated datasets
⬇️

Over the past several months, I’ve been doing a deep-dive into transformer language models #NLProc and their applications in #psychology for the last part of my #PhD thesis. 👩🏻🎓 Here are a few resources that I’ve found invaluable and really launched me forward on this project 🧵:
🏃🏻♀️💨 If you already have some data and you want a jump start to classify it all using #transformers, check out @maria_antoniak’s #BERT for Humanists/Computational Social Scientists Talk: Colab notebook and other info: bertforhumanists.org/tutorials/#cla…
🤓 I’m an absolute nerd for stats and experiment design in psych, but doing #ML experiments is very different. A clear, detailed (and reasonable length) course to get up to speed on train-test splits, hyperparameter tuning, etc. and do the very best work: coursera.org/learn/deep-neu…
