Discover and read the best of Twitter Threads about #ICML2022
Most recents (14)

I’m a bit late, but check out @Apple research papers presented at #ICML2022 here: machinelearning.apple.com/research?year=…
Includes work on transformer pre-training, dynamic pooling, private federated statistics, and generative models.
1/n
Includes work on transformer pre-training, dynamic pooling, private federated statistics, and generative models.
1/n
arxiv.org/abs/2207.07611 provides a simple method for transformer pre-training based on predicting the positions of a set of orderless tokens. Often requires fewer pre-training iterations to achieve a good model.
2/n
2/n
By @zhaisf @navdeepjaitly10 @jramapuram @danbusbridge Tatiana Likhomanenko @josephycheng @waltertalbott @chen_huang23 @hanlingoh @jsusskin.
3/n
3/n

If you’re interested in deep learning (DL) and neuroscience, come to our poster at @AI_for_Science’s #ICML2022 workshop
**No Free Lunch from Deep Learning in Neuroscience: A Case Study through Models of the Entorhinal-Hippocampal Circuit**
Joint w/ @KhonaMikail @FieteGroup 1/13
**No Free Lunch from Deep Learning in Neuroscience: A Case Study through Models of the Entorhinal-Hippocampal Circuit**
Joint w/ @KhonaMikail @FieteGroup 1/13

@AI_for_Science @KhonaMikail @FieteGroup The central promise of DL-based models of the brain are that they (1) shed light on the brain’s fundamental optimization problems/solutions, and/or (2) make novel predictions. We show, using DL models of grid cells in the MEC-HPC circuit, that one often gets neither 2/13
@AI_for_Science @KhonaMikail @FieteGroup Prior work claims that training artificial networks (ANNs) on a path integration task generically creates grid cells (a). We empirically show and analytically explain why grid cells only emerge in a small subset of hyperparameter space chosen post-hoc by the programmer (b). 3/13


There is a lot of excitement about causal machine learning, but in what ways exactly can causality help with ML tasks?
In my work, I've seen four: enforcing domain knowledge, invariant regularizers, "counterfactual" augmentation & better framing for fairness & explanation. 🧵👇🏻
In my work, I've seen four: enforcing domain knowledge, invariant regularizers, "counterfactual" augmentation & better framing for fairness & explanation. 🧵👇🏻
1)Enforcing domain knowledge: ML models can learn spurious correlations. Can we avoid this by using causal knowledge from experts?
Rather than causal graphs, eliciting info on key relationships is a practical way. See #icml2022 paper on how to enforce them arxiv.org/abs/2111.12490
Rather than causal graphs, eliciting info on key relationships is a practical way. See #icml2022 paper on how to enforce them arxiv.org/abs/2111.12490
2) Invariant regularizers: For out-of-distribution generalization, another way is to add regularization constraints.
Causality can help us find the correct constraint for any dataset. Also easy to show that no single constraint can work everywhere. Algo: arxiv.org/abs/2206.07837
Causality can help us find the correct constraint for any dataset. Also easy to show that no single constraint can work everywhere. Algo: arxiv.org/abs/2206.07837

Understanding data quality is crucial for reliable ML. In our #ICML2022 paper, @NabeelSeedat01, @JonathanICrabbe & @MihaelaVDS present a Data-Centric framework for the understudied problem of identifying incongruous examples of in-distribution data.
🧵1/10
🧵1/10
TLDR.
*Do you want to know which examples will be reliably predicted, independent of the downstream predictive model?
* Do you want to get insights into your data to understand possible limitations?
If so, Data-SUITE our new #DataCentricAI framework is for you!
2/10
*Do you want to know which examples will be reliably predicted, independent of the downstream predictive model?
* Do you want to get insights into your data to understand possible limitations?
If so, Data-SUITE our new #DataCentricAI framework is for you!
2/10
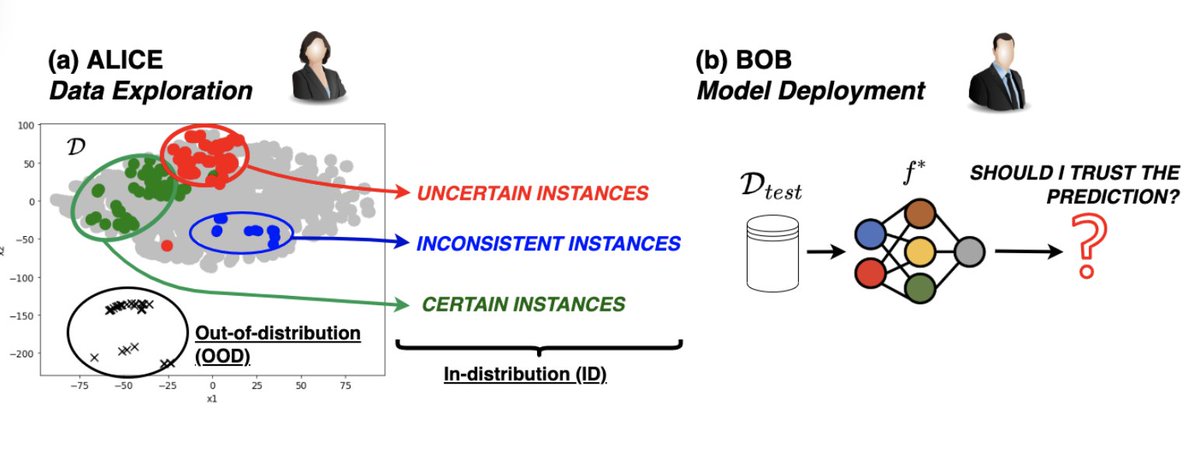
There has been a significant focus on out-of-distribution data (OOD) for reliable ML.
However, in Data-SUITE we tackle an equally important yet understudied problem.
How do we assess In-Distribution data, with feature space heterogeneity?
3/10
However, in Data-SUITE we tackle an equally important yet understudied problem.
How do we assess In-Distribution data, with feature space heterogeneity?
3/10

Excited and honored to share that our #ICML2022 paper, “Causal Conceptions of Fairness and their Consequences” (w/ @jgaeb1, Ravi Shroff, and @5harad) has received an outstanding paper award!!! See 🧵for key findings and results
Paper: arxiv.org/abs/2207.05302 1/17
Paper: arxiv.org/abs/2207.05302 1/17

@jgaeb1 @5harad We find that, surprisingly, the paradigm shift in fair ML towards causal reasoning is *harmful* to common policy goals, including diversity and equity efforts. 2/17
Our results are counterintuitive because causal approaches may seem like policy *improvements* over traditional, non-causal fairness criteria. For instance, a traditional approach in fair ML (blinding) is to simply remove features like race or gender from decisions. 3/17

0/ Introducing TACTiS, a transformer-based model for multivariate probabilistic time series prediction. 1) supports forecasting, interpolation... 2) supports unaligned and non-uniformly sampled time series 3) can scale to hundreds of time series. Curious? Read on to learn more…
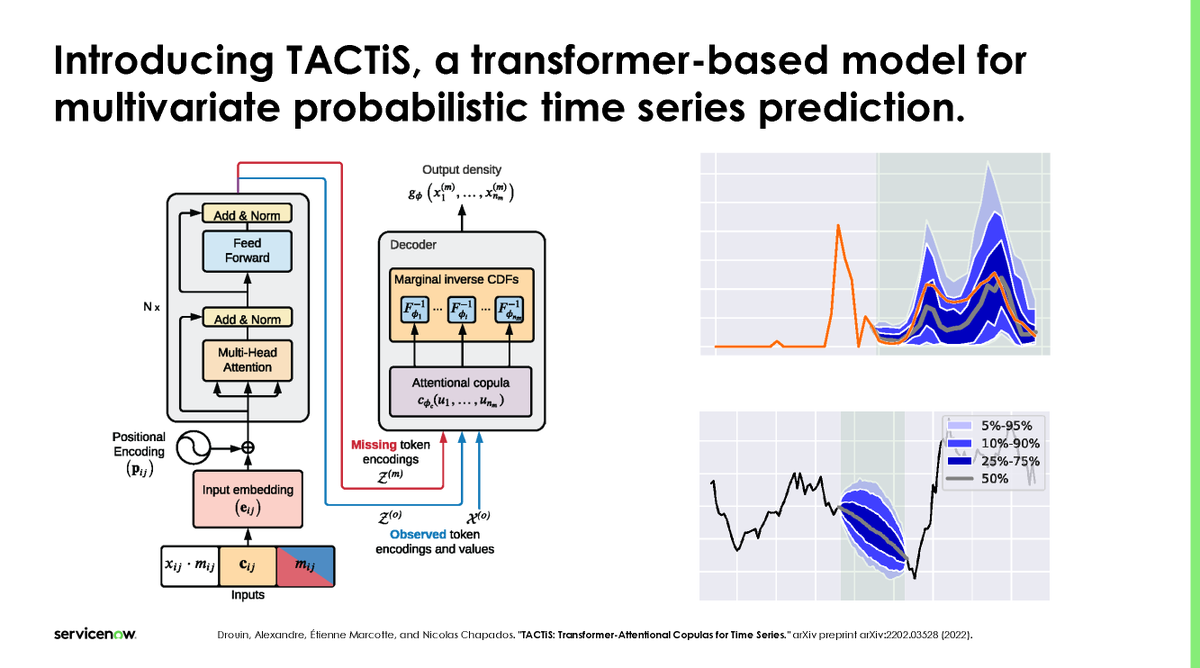
1/ The TACTiS model infers the joint distribution of masked time points given observed time points in multivariate time series. It enables probabilistic multivariate forecasting, interpolation, and backcasting according to arbitrary masking patterns specified at inference time.
2/ TACTiS is an encoder-decoder model similar to standard transformers. Our main contribution, attentional copulas, belongs to the decoder. However, both component have key features that enables the great flexibility of TACTiS. Let’s dive into these…


📢 Physics + GPs + inverse problems using #ProbabilisticNumerics 📢
At #ICML2022 we show that probabilistic ODE solvers are not just fast, but also useful for solving inverse problems! Joint work with Filip Tronarp and @PhilippHennig5. More below 🧵
At #ICML2022 we show that probabilistic ODE solvers are not just fast, but also useful for solving inverse problems! Joint work with Filip Tronarp and @PhilippHennig5. More below 🧵
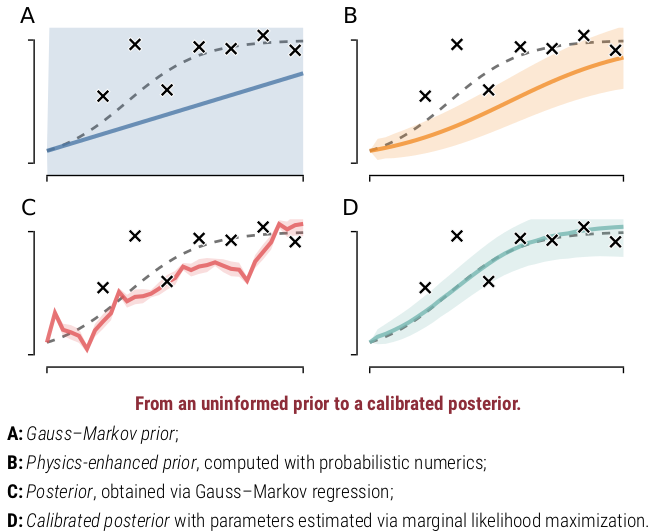
The gist is: When doing inference with traditional ODE solvers we ignore their numerical error. But by being "probabilistic about the numerics", we can fit _both the ODE and the data jointly_! Which e.g. allows us to better learn parameters of oscillatory systems:
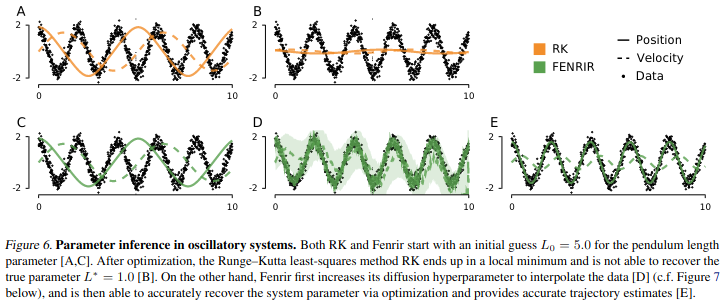
Paper: proceedings.mlr.press/v162/tronarp22a
Experiments: github.com/nathanaelbosch…
Code in #julialang: github.com/nathanaelbosch…
And if you got curious about probabilistic ODE solvers, there's more this ICML:
Experiments: github.com/nathanaelbosch…
Code in #julialang: github.com/nathanaelbosch…
And if you got curious about probabilistic ODE solvers, there's more this ICML:

Neural nets are brittle under domain shift & subpop shift.
We introduce a simple mixup-based method that selectively interpolates datapts to encourage domain-invariance
ICML 22 paper: arxiv.org/abs/2201.00299
w/ @HuaxiuYaoML Yu Wang @zlj11112222 @liang_weixin @james_y_zou (1/3)
We introduce a simple mixup-based method that selectively interpolates datapts to encourage domain-invariance
ICML 22 paper: arxiv.org/abs/2201.00299
w/ @HuaxiuYaoML Yu Wang @zlj11112222 @liang_weixin @james_y_zou (1/3)

Prior methods encourage domain-invariant *representations*.
This constrains the model's internal representation
By using mixup to interpolate within & across domains, we get domain invariant *predictions* w/o constraining the model.
Less constraining -> better performance
(2/3)
This constrains the model's internal representation
By using mixup to interpolate within & across domains, we get domain invariant *predictions* w/o constraining the model.
Less constraining -> better performance
(2/3)


The method is also quite simple to implement.
Code: github.com/huaxiuyao/LISA
#ICML2022 Paper: arxiv.org/abs/2201.00299
WILDS Leaderboard: wilds.stanford.edu/leaderboard/
See Huaxiu's thread for much more!
(3/3)
Code: github.com/huaxiuyao/LISA
#ICML2022 Paper: arxiv.org/abs/2201.00299
WILDS Leaderboard: wilds.stanford.edu/leaderboard/
See Huaxiu's thread for much more!
(3/3)

VGG, U-Net, TCN, ... CNNs are powerful but must be tailored to specific problems, data-types, -lenghts & -resolutions.
Can we design a single CNN that works well on all these settings?🤔Yes! Meet the 𝐂𝐂𝐍𝐍, a single CNN that achieves SOTA on several datasets, e.g., LRA!🔥
Can we design a single CNN that works well on all these settings?🤔Yes! Meet the 𝐂𝐂𝐍𝐍, a single CNN that achieves SOTA on several datasets, e.g., LRA!🔥

Accepted at the #ICML2022 #Workshop on #ContinuousTimeMethods.
Joint work with @davidknigge, @_albertgu, @erikjbekkers, @egavves, @jmtomczak & Mark Hoogendoorn.
Paper: arxiv.org/abs/2206.03398
Code: github.com/david-knigge/c…
Slides: app.slidebean.com/p/gk5j826nq7/C…
Joint work with @davidknigge, @_albertgu, @erikjbekkers, @egavves, @jmtomczak & Mark Hoogendoorn.
Paper: arxiv.org/abs/2206.03398
Code: github.com/david-knigge/c…
Slides: app.slidebean.com/p/gk5j826nq7/C…
𝐌𝐚𝐢𝐧 𝐈𝐝𝐞𝐚: Architecture changes are needed to model long range dependencies for signals of different length, res & dims, e.g., pooling, depth, kernel sizes.
To solve all tasks with a single CNN, it must model long range deps. at every layer: use Continuous Conv Kernels!
To solve all tasks with a single CNN, it must model long range deps. at every layer: use Continuous Conv Kernels!

Is it possible that adversarially-trained DNNs are already more robust than the biological neural networks of primate visual cortex? Here is a short thread for our #ICML2022 paper arxiv.org/pdf/2206.11228…. 1/8

Biological neurons supporting visual recognition in the primate brain are thought to be robust. Using a novel technique, we discovered that neurons are in fact highly susceptible to nearly imperceptible adversarial perturbations. 🙈2/8

So how do biological neurons compare to artificial neurons in DNNs? We find that while biological neurons are less sensitive than units in vanilla DNNs, they are MORE SENSITIVE than units in adversarially trained DNNs. 🤯3/8


What do Lyapunov functions, offline RL, and energy based models have in common? Together, they can be used to provide long-horizon guarantees by "stabilizing" a system in high density regions! That's the idea behind Lyapunov Density Models: sites.google.com/berkeley.edu/l…
A thread:
A thread:

Basic question: if I learn a model (e.g., dynamics model for MPC, value function, BC policy) on data, will that model be accurate when I run it (e.g., to control my robot)? It might be wrong if I go out of distribution, LDMs aim to provide a constraint so they don't do this.


By analogy (which we can make precise!) Lyapunov functions tell us how to stabilize around a point in space (i.e., x=0). What if we want is to stabilize in high density regions (i.e., p(s) >= eps). Both require considering long horizon outcomes though, so we can't just be greedy!

Happy to finally share our paper about differentiable Top-K Learning by Sorting that didn’t make it to #CVPR2022, but was accepted for #ICML2022! We show that you can improve classification by actually considering top-1 + runner-ups… 1/6🧵
#ComputerVision #AI #MachineLearning
#ComputerVision #AI #MachineLearning
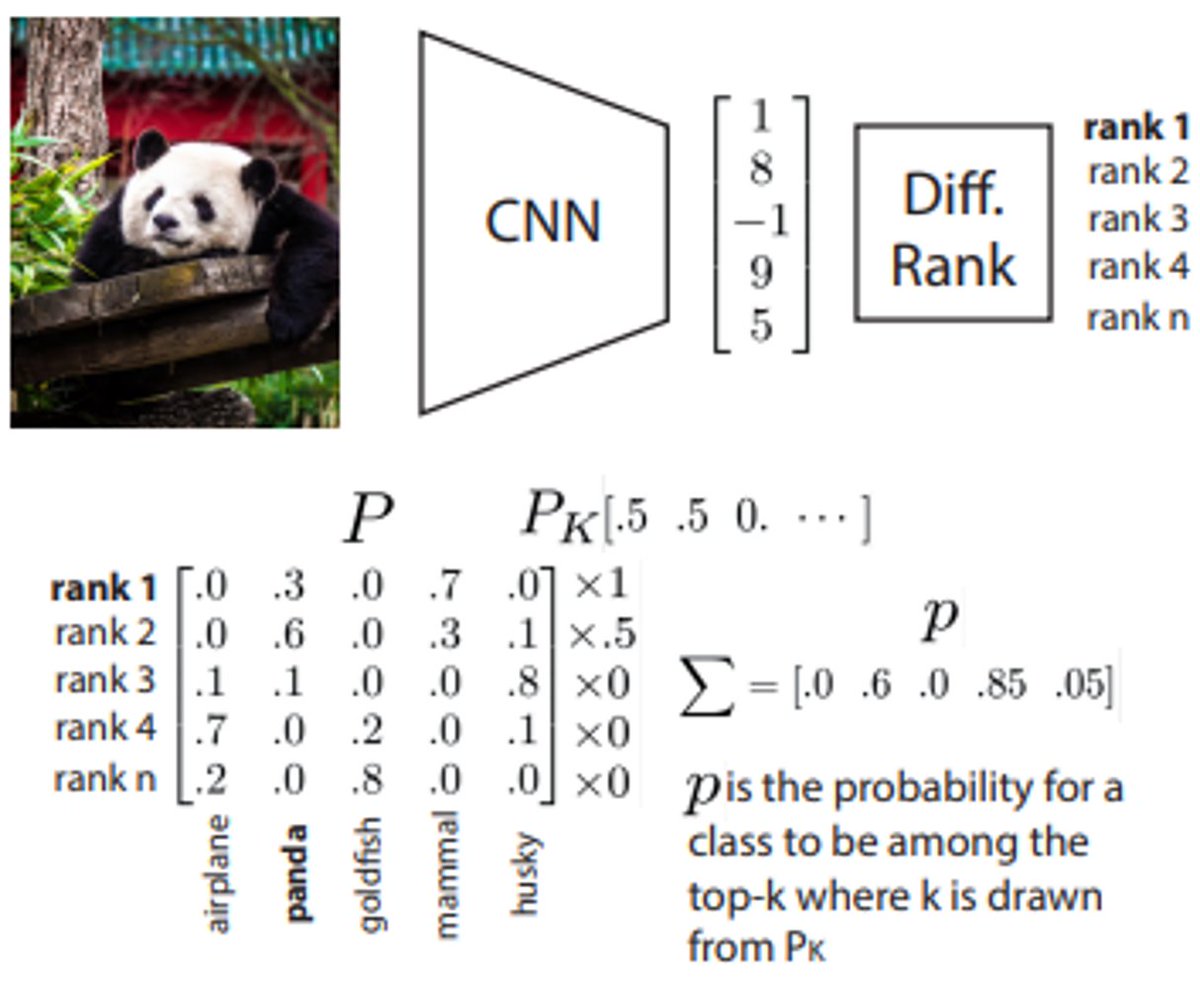
Paper: arxiv.org/abs/2206.07290
Great work by @FHKPetersen in collaboration with Christian Borgelt, @OliverDeussen . 2/6🧵
@MITIBMLab @goetheuni @UniKonstanz
Great work by @FHKPetersen in collaboration with Christian Borgelt, @OliverDeussen . 2/6🧵
@MITIBMLab @goetheuni @UniKonstanz
Idea: Top-k class accuracy is used in many ML tasks, but training is usually limited to top-1 accuracy (or another k). We propose a differentiable top-k classification loss that allows training by considering any combination of top-k predictions, e.g. top-2 top-5, 3/6🧵

Tired of waiting 💤 while your model trains? Try skipping points that are already learned, not learnable or not worth learning! Robustly reduces required training steps 🏎 by >10x ! to reach the same accuracy on big web-scraped data
📜ICML 2022 paper: arxiv.org/abs/2206.07137
📜ICML 2022 paper: arxiv.org/abs/2206.07137

Training on big web-scraped data can take ages 💤 But lots of compute and time is wasted on redundant and noisy points that are already learned, not learnable, or not even worth learning.

What if we just skip these points? Our method—RHO-LOSS—trains in far fewer gradient steps than prior art, boosts accuracy, and speeds up training on 8 datasets, lots of hyperparameters, and 10 architectures (MLPs, CNNs, and BERT).

New workshop at @icmlconf: Updatable Machine Learning (UpML 2022)!
Training models from scratch is expensive. How can we update a model post-deployment but avoid this cost? Applications to unlearning, domain shift, & more!
Deadline May 12
upml2022.github.io #ICML2022 (1/3)
Training models from scratch is expensive. How can we update a model post-deployment but avoid this cost? Applications to unlearning, domain shift, & more!
Deadline May 12
upml2022.github.io #ICML2022 (1/3)

Ft stellar lineup of invited speakers including: Chelsea Finn (@chelseabfinn), Shafi Goldwasser, Zico Kolter (@zicokolter), Nicolas Papernot (@NicolasPapernot), & Aaron Roth (@Aaroth)
They've studied UpML in a variety of contexts, including unlearning, robustness, fairness (2/3)
They've studied UpML in a variety of contexts, including unlearning, robustness, fairness (2/3)

Workshop is co-organized with lead organizer Ayush Sekhari (@ayush_sekhari) and Jayadev Acharya (@AcharyaJayadev), and supported by an excellent program committee (being finalized).
We look forward to seeing your best work in this emerging area! (3/3)
We look forward to seeing your best work in this emerging area! (3/3)


