Discover and read the best of Twitter Threads about #ICCV2021
Most recents (9)

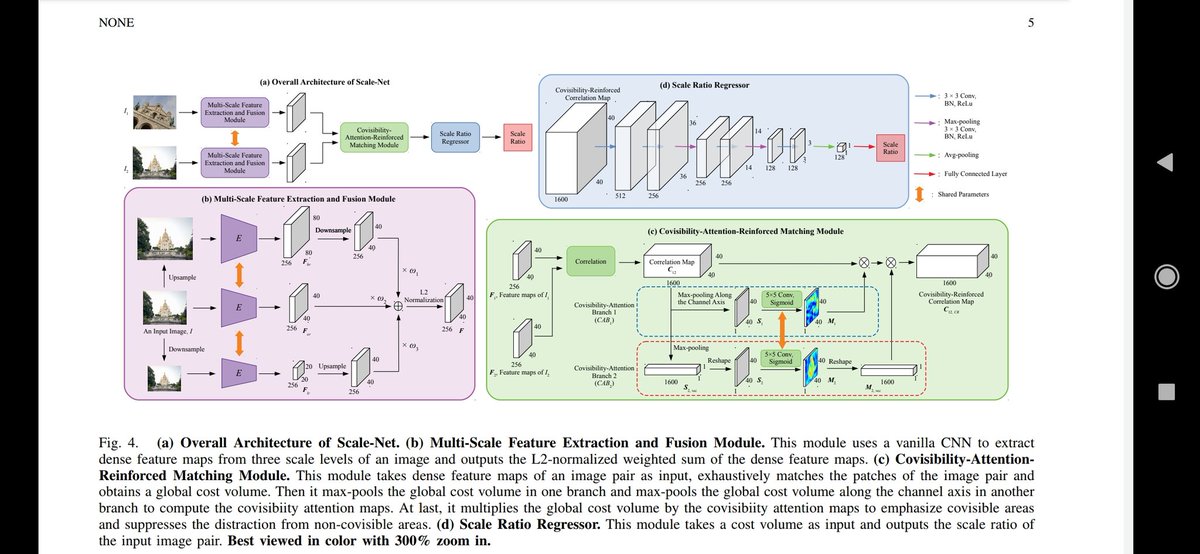
Scale-Net: Learning to Reduce Scale Differences for Large-Scale Invariant Image Matching
tl;dr: same idea as with other ScaleNet: estimate scale difference in 2 images-> resize them. Eval on their version of Scale IMC
1/2 (check 2nd)
Yujie Fu, Yihong Wu
arxiv.org/abs/2112.10485
tl;dr: same idea as with other ScaleNet: estimate scale difference in 2 images-> resize them. Eval on their version of Scale IMC
1/2 (check 2nd)
Yujie Fu, Yihong Wu
arxiv.org/abs/2112.10485



In order to prove priority and originality of the idea w.r.t. @axelbarrosotw ScaleNet, authors included #ICCV2021 submission screenshot as a proof.
Weird, however that current paper has less authors.
2/2
Weird, however that current paper has less authors.
2/2


This is other ScaleNet

All talks of our #ICCV2021 tutorial on visual localisation are available on YouTube.
In my talk about learning-based localisation, I discuss a challenge, a promise and a compromise.
Watch it here:
Links to all the amazing talks in 🧵👇
In my talk about learning-based localisation, I discuss a challenge, a promise and a compromise.
Watch it here:
Links to all the amazing talks in 🧵👇

Giorgos Tolias (@giotolias) from the CTU in Prague talked about Instance Search for Place Recognition:

Yannis Avrithis (@1avr1e) from the Athena Research Center talked about Metric Learning: Knowledge Transfer, Data Augmentation, and Attention:





Jitendra Malik slides


Great job @SergeBelongie! I could have watched another hour of this panel.

We are presenting 5 papers at #ICCV2021! Get a first glimpse here: youtube.com/playlist?list=… More detailed info 👇
(Just) A Spoonful of Refinements Helps the Registration Error Go Down, oral presentation, session 5A! arxiv.org/abs/2108.03257 @sragostinho @AljosaOsep Wonderful collaboration with @alessiodelbue
MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking?
Session 8A/8B! Paper: arxiv.org/abs/2108.09518 Project page: aimagelab.ing.unimore.it/imagelab/page.…
Session 8A/8B! Paper: arxiv.org/abs/2108.09518 Project page: aimagelab.ing.unimore.it/imagelab/page.…

🚨 This week at #ICCV2021, check out "Pixel-Perfect Structure-from-Motion with Featuremetric Refinement" w/ @PhilippCSE V. Larsson @mapo1
➡️ oral & *best student paper award*
Website: psarlin.com/pixsfm
Paper: arxiv.org/abs/2108.08291
Video:
thread ⬇️
➡️ oral & *best student paper award*
Website: psarlin.com/pixsfm
Paper: arxiv.org/abs/2108.08291
Video:
thread ⬇️
We improve the accuracy of Structure-from-Motion (= camera poses & 3D points), making COLMAP subpixel accurate & closer to Lidar performance. This enables:
➡️ accurate visual localization of new images
➡️ mapping with fewer images - critical for large-scale crowd-sourced AR 😎
2/
➡️ accurate visual localization of new images
➡️ mapping with fewer images - critical for large-scale crowd-sourced AR 😎
2/

We align dense deep features with featuremetric optimization in 2 steps
1️⃣ Before SfM: keypoint adjustment
2️⃣ After SfM: bundle adjustment
This works well with many dense CNNs (even VGG ImageNet) & sparse local features (SuperGlue!) and suitable for both global/incremental SfM
3/
1️⃣ Before SfM: keypoint adjustment
2️⃣ After SfM: bundle adjustment
This works well with many dense CNNs (even VGG ImageNet) & sparse local features (SuperGlue!) and suitable for both global/incremental SfM
3/


Excited to introduce a new generation of privacy protecting smart cameras in our #ICCV2021 Oral paper by @CarlosH_93, @henarfu and myself 🇺🇸🇨🇴. See 🧵 below for details!
PDF: openaccess.thecvf.com/content/ICCV20…
Talk:
Project: carloshinojosa.me/project/privac…
@StanfordAILab
PDF: openaccess.thecvf.com/content/ICCV20…
Talk:
Project: carloshinojosa.me/project/privac…
@StanfordAILab
Our cameras introduce optical distortions at acquisition time, capturing images that protect the identity of people in the scene while enabling vision algorithms to perform inference accurately.
*Key idea*: joint end-to-end optimization of optical distortions & vision algorithm.
*Key idea*: joint end-to-end optimization of optical distortions & vision algorithm.

We achieve this by back-propagating all the way down to the camera lens. To make the lens shape differentiable, we parametrize it using Zernike polynomials.


In anticipation of the Intl. Conf. on Computer Vision (#ICCV2021) this week, I rounded up all papers that use Neural Radiance Fields (NeRFs) represented in the main #ICCV2021 conference here (1/N):
dellaert.github.io/NeRF21
dellaert.github.io/NeRF21
Many of the papers I discussed in my original blog-post on NerF (dellaert.github.io/NeRF/) made it into CVPR, but the sheer number of NeRF-style papers that appeared on Arxiv this year meant I could no longer keep up. 2/N
Conferences like #ICCV2021 (with CVPR, the top-tier Computer Vision conference) provide an (imperfect) filter, and I decided to read all the papers I could find in the ICCV main program. I share them with you below and in the archival blog post. Email me if any are missing! 3/N

Wondering how to detect when your neural network is about to predict pure non-sense in a safety critical scenario?
We answer your questions in our #ICCV2021 @ICCV_2021 paper!
Thursday 1am (CET) or Friday 6pm (CET), Session 12, ID: 3734
📜 openaccess.thecvf.com/content/ICCV20…
Thread 🧵👇
We answer your questions in our #ICCV2021 @ICCV_2021 paper!
Thursday 1am (CET) or Friday 6pm (CET), Session 12, ID: 3734
📜 openaccess.thecvf.com/content/ICCV20…
Thread 🧵👇
The problem with DNNs is they are trained on carefully curated datasets that are not representative of the diversity we find in the real world.
That's especially true for road datasets.
In the real world, we have to face "unknown unkowns", ie, unexpected objects with no label.
That's especially true for road datasets.
In the real world, we have to face "unknown unkowns", ie, unexpected objects with no label.

How to detect such situation?
We propose a combination of 2 principles that lead to very good results:
1_ Disentangle the task (classification, segmentation, ...) from the Out-of-distribution detection.
2_ Train the detector using generated adversarial samples as proxy for OoD.
We propose a combination of 2 principles that lead to very good results:
1_ Disentangle the task (classification, segmentation, ...) from the Out-of-distribution detection.
2_ Train the detector using generated adversarial samples as proxy for OoD.


Self-supervised learning promises to leverage vast amounts of data, but existing methods remain slow and expensive. Introducing contrastive detection, a new objective that learns useful representations for many tasks, with up to 10x less computation: dpmd.ai/3jsOV9l 1/

Contrastive detection amplifies the learning signal from each image by carving it into pieces and learning from each simultaneously. This works particularly well when transferring to challenging tasks like detection, segmentation, and depth estimation. 2/

These results raise the possibility of learning algorithms that are more widely accessible, requiring neither human annotations nor vast amounts of computation.
To be presented at #ICCV2021 by @olivierhenaff @skandakoppula @jalayrac @avdnoord @OriolVinyalsML & @joaocarreira 3/3
To be presented at #ICCV2021 by @olivierhenaff @skandakoppula @jalayrac @avdnoord @OriolVinyalsML & @joaocarreira 3/3
