Discover and read the best of Twitter Threads about #Causalinference
Most recents (24)

😯 The greatest fear that drives people away from causality is not about complexity
It's about something much simpler
🧵 (1/n)
#causality #causalinference #python #machinelearning #datascience #casualtwitter
It's about something much simpler
🧵 (1/n)
#causality #causalinference #python #machinelearning #datascience #casualtwitter

If you ask people who have some knowledge about causality, but they never worked in the field, you can often hear that using causal methods in the real world is "too risky".
🧵 (2/n)
🧵 (2/n)
The number one reason for this are the dreaded "causal assumptions".
🧵 (3/n)
🧵 (3/n)

DAG question for #CausalInference and #epitwitter tweeps: TL;DR: How do we use DAGs in typical pharmacosurveillance scenarios, when the entities of interest are unobserved? A thread 1/

We are interested in whether the administration of a drug is causing an increase in the probability of an adverse event (thus, an adverse drug reaction), vs. there not being any causal relation. 2/


However, the data we have access to are the spontaneous reports of practitioners and patients, about the co-occurrence of drug & event. So, drug & event are unobserved variables, only the report of their co-occurrence is reported. 3/



@BU_BMC_Rheum Abs 1912 @profdeepakkumar
❓Is altered facilitatory and inhibitory nociceptive functioning is related to lower physical activity in people with knee OA?
#ACR22
❓Is altered facilitatory and inhibitory nociceptive functioning is related to lower physical activity in people with knee OA?
#ACR22


"#Imitation vs #Innovation: Large #Language and Image Models as Cultural #Technologies"
Today's Seminar by SFI External Prof @AlisonGopnik (@UCBerkeley)
Streaming now:
Follow our 🧵 for live coverage.
Today's Seminar by SFI External Prof @AlisonGopnik (@UCBerkeley)
Streaming now:
Follow our 🧵 for live coverage.

"Today you hear people talking about 'AN #AI' or 'THE AI.' Even 15 years ago we would not have heard this; we just heard 'AI.'"
@AlisonGopnik on the history of thought on the #intelligence (or lack thereof) of #simulacra, linked to the convincing foolery of "double-talk artists":
@AlisonGopnik on the history of thought on the #intelligence (or lack thereof) of #simulacra, linked to the convincing foolery of "double-talk artists":


"We should think about these large #AI models as cultural technologies: tools that allow one generation of humans to learn from another & do this repeatedly over a long period of time. What are some examples?"
@AlisonGopnik suggests a continuity between #GPT3 & language itself:
@AlisonGopnik suggests a continuity between #GPT3 & language itself:


@PWGTennant: Avoiding observational research altogether is 'socially regressive'. #LeedsCausalSchool


@PWGTennant: When we admit that what we want is causal, we admit that what we currently have is not enough. #causalinference #LeedsCausalSchool

@statsmethods: Prediction & causal inference often use the same tools but use them differently for different goals. 💡 #LeedsCausalSchool



This is my favorite teaching example for showing the importance of #CausalInference: @Google conducts an annual pay equity analysis in which they use fairly advanced statistical techniques. In 2019 they found that they were actually underpaying MEN?! npr.org/2019/03/05/700… 1/

What do they do specifically? They collect a lot of data (as Google does) and then run OLS regressions of annual compensation on demographic variables (gender, race) and other explanatory variables such as tenure, location, and performance. services.google.com/fh/files/blogs… 2/

If they find statistically meaningful differences, @Google is actually committed to make upward adjustments for the disadvantaged groups. In this case it was male, level-4 software engineers who got a raise. 3/


1/
Our findings on a fourth dose (2nd booster) of the Pfizer-BioNTech #COVID19 vaccine are now published.
Compared with 3 doses only, a fourth dose had 68% effectiveness against COVID-19 hospitalization during the Omicron era in persons over 60 years of age.
Interestingly...
Our findings on a fourth dose (2nd booster) of the Pfizer-BioNTech #COVID19 vaccine are now published.
Compared with 3 doses only, a fourth dose had 68% effectiveness against COVID-19 hospitalization during the Omicron era in persons over 60 years of age.
Interestingly...
2/
... this is yet another example of the need for good #observational studies that emulate a #TargetTrial.
Would it be better to have a real randomized trial? Yes
Do we have a randomized trial? No
Will we have a randomized trial? Perhaps, but too late for a timely decision.
... this is yet another example of the need for good #observational studies that emulate a #TargetTrial.
Would it be better to have a real randomized trial? Yes
Do we have a randomized trial? No
Will we have a randomized trial? Perhaps, but too late for a timely decision.
3/
Last year, observational evidence was also used to recommend a first vaccine booster.
Our and others' studies provided evidence on the booster's protection against hospitalization after infection with Delta:
Policy makers listened. Lives were saved...
Last year, observational evidence was also used to recommend a first vaccine booster.
Our and others' studies provided evidence on the booster's protection against hospitalization after infection with Delta:
Policy makers listened. Lives were saved...
1/
We emulated a target trial of two #COVID19 mRNA vaccines in the largest healthcare system in the US.
Both vaccines were similarly effective, with Moderna slightly better than Pfizer-BioNTech.
But that isn't the most important conclusion of our study.
We emulated a target trial of two #COVID19 mRNA vaccines in the largest healthcare system in the US.
Both vaccines were similarly effective, with Moderna slightly better than Pfizer-BioNTech.
But that isn't the most important conclusion of our study.
2/
Spring of 2020: #COVID19 vaccines are developed.
October 2020: Results from randomized trial are announced.
businesswire.com/news/home/2021…
~6 months from development to evaluation of effectiveness.
Utterly impressive. Unprecedented.
Kudos to the pharmaceutical industry.
Now...
Spring of 2020: #COVID19 vaccines are developed.
October 2020: Results from randomized trial are announced.
businesswire.com/news/home/2021…
~6 months from development to evaluation of effectiveness.
Utterly impressive. Unprecedented.
Kudos to the pharmaceutical industry.
Now...
3/
December 2020: Vaccines become available.
December 2021: Where are the big randomized trials for COMPARATIVE effectiveness?
1 year, still *crickets*
Billions of taxpayer dollars and we don’t get to know which vaccine is better and safer?
Not so impressive, pharma industry.
December 2020: Vaccines become available.
December 2021: Where are the big randomized trials for COMPARATIVE effectiveness?
1 year, still *crickets*
Billions of taxpayer dollars and we don’t get to know which vaccine is better and safer?
Not so impressive, pharma industry.
1/
Vaccine safety: We compared excess adverse events after #COVID19 vaccination (Pfizer-BioNTech) and after documented #SARSCoV2 infection.
nejm.org/doi/full/10.10…
Take-home message: Low excess risk of adverse events after vaccination, higher after infection.
Some thoughts👇
Vaccine safety: We compared excess adverse events after #COVID19 vaccination (Pfizer-BioNTech) and after documented #SARSCoV2 infection.
nejm.org/doi/full/10.10…
Take-home message: Low excess risk of adverse events after vaccination, higher after infection.
Some thoughts👇
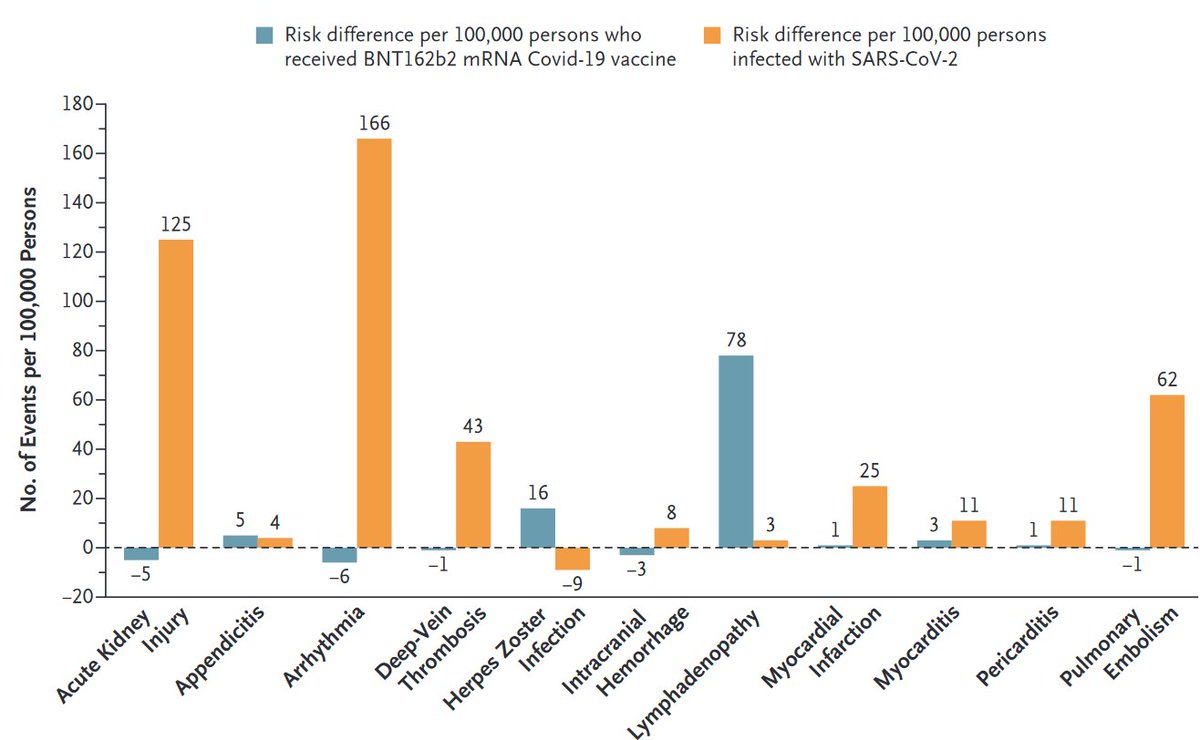
2/
Preferring #SARSCoV2 infection over vaccination has become even harder. (Remember: infection also increases the risk of severe disease/death)
This is a good illustration of how #randomized trials and #observational studies complement each other for better #causalinference...
Preferring #SARSCoV2 infection over vaccination has become even harder. (Remember: infection also increases the risk of severe disease/death)
This is a good illustration of how #randomized trials and #observational studies complement each other for better #causalinference...
3/
The original #randomized trial estimated vaccine effectiveness to prevent symptomatic infection, but was too small to quantify vaccine safety.
That's what #observational studies do.
Now a different sort of question: Why could we do this study in the first place?
2 reasons.
The original #randomized trial estimated vaccine effectiveness to prevent symptomatic infection, but was too small to quantify vaccine safety.
That's what #observational studies do.
Now a different sort of question: Why could we do this study in the first place?
2 reasons.

1/ Readers ask: What's the simplest problem in which a combination of experimental and observational studies can be shown to be better than each study alone?
Ans. Consider X--->Z----> Y
with unobserved confounder between X & Z.
Query Q: Find P(y|do(x))
We have 2 valid estimands:
Ans. Consider X--->Z----> Y
with unobserved confounder between X & Z.
Query Q: Find P(y|do(x))
We have 2 valid estimands:
2/
ES1 = P(y|do(x)) estimable from the experiment
ES2 =SUM_z P(z|do(x))P(y|z), the first term is estimable from the experiment, the second from the observational study.
ES2 is better than ES1 for 3 reasons:
1. P(y|z) can rest on a larger sample
2. ES2 is composite (see
ES1 = P(y|do(x)) estimable from the experiment
ES2 =SUM_z P(z|do(x))P(y|z), the first term is estimable from the experiment, the second from the observational study.
ES2 is better than ES1 for 3 reasons:
1. P(y|z) can rest on a larger sample
2. ES2 is composite (see
3/ (see ucla.in/2ocoWqq for advantage of composite estimators)
3. ES2 need not measure Y in the experimental study.
Remark: The validity of ES2 follows from do-calculus. Adding any edge to the graph invalidates ES2 and leaves ES1 the only estimand.
3. ES2 need not measure Y in the experimental study.
Remark: The validity of ES2 follows from do-calculus. Adding any edge to the graph invalidates ES2 and leaves ES1 the only estimand.

1/ Q: Do we know more about whether the vaccines reduce transmission?
A: YES! Evidence continues to mount that the vaccines DO in fact reduce transmission.
#vaccineswork
dearpandemic.org/do-vaccines-re…
A: YES! Evidence continues to mount that the vaccines DO in fact reduce transmission.
#vaccineswork
dearpandemic.org/do-vaccines-re…
2/ ➡️ While the Nerdy Girls are still dreaming of transmission being tested in the clinical trials (call us☎️), the data pouring in from around the world strongly suggests that the vaccines are very good (but not perfect) at reducing ALL infections & by extension transmission.
3/ Recall the clinical trials (largely) tested only participants who developed symptoms. One possibility is that vaccines reduce the severity of COVID-19 to the point of no symptoms, but still allow the virus to replicate in the nose and throat & potentially be spread to others.


🧵 1/ @TamaraSurin’s smart (and *very* generous) take on recent @JAMA_current podcast on “structural racism”...
🧵 2/ Now here’s my take: I believe that the host, JAMA editor Edward Livingston, inadvertently makes a strong argument against his own thesis!
🧵3/ Dr. Livingston argues that using the word “racism” is counterproductive for addressing “very real” “structural problems in our society”
1/
We've just confirmed the effectiveness of the Pfizer-BioNTech vaccine outside of randomized trials.
Details @NEJM: nejm.org/doi/full/10.10…
Yes, great news, but let's talk about methodological issues that arise when using #observational data to estimate vaccine effectiveness.
We've just confirmed the effectiveness of the Pfizer-BioNTech vaccine outside of randomized trials.
Details @NEJM: nejm.org/doi/full/10.10…
Yes, great news, but let's talk about methodological issues that arise when using #observational data to estimate vaccine effectiveness.
2/
A critical concern in observational studies of vaccine effectiveness is #confounding:
Suppose that people who get vaccinated have, on average, a lower risk of infection/disease than those who don't get vaccinated.
Then, even if the vaccine were useless, it'd look beneficial.
A critical concern in observational studies of vaccine effectiveness is #confounding:
Suppose that people who get vaccinated have, on average, a lower risk of infection/disease than those who don't get vaccinated.
Then, even if the vaccine were useless, it'd look beneficial.
3/
To adjust for confounding:
We start by identifying potential confounders.
For example: Age
(vaccination campaigns prioritize older people and older people are more likely to develop severe disease)
Then we choose a valid adjustment method. In our paper, we matched on age.
To adjust for confounding:
We start by identifying potential confounders.
For example: Age
(vaccination campaigns prioritize older people and older people are more likely to develop severe disease)
Then we choose a valid adjustment method. In our paper, we matched on age.
🧵I’ve written before about the undercurrent of misogyny I perceive in the public debate about in-person K-12 schooling in the US...1/
🧵I’ve stopped much writing about #SARSCoV2 & K-12: I think weight of evidence is strong that K-12 (esp for younger ages) can be operated w very low levels of in-school #SARSCoV2 transmission when precautions in place (new variants may change this) dontforgetthebubbles.com/evidence-summa… ...2/
🧵...and I’ve stopped writing about it because the debate seems polarized and hardened (although there’s a LOT of policy movement rn nationally...we’ll see how that all plays out). I just don’t have much to add that I think will change anyone’s mind 3/

Too many broadly useful stats methods are masked in domain-specific language. In my new pair of posts, I discuss formula-free #causalinference design patterns to help data analysts recognize frameworks as they encounter them in everyday work
emilyriederer.netlify.app/post/causal-de…
1/3
emilyriederer.netlify.app/post/causal-de…
1/3
I don't rehash the finer details; for that my resource round-up post catalogues the plethora of amazing books freely available from @_MiguelHernan @causalinf @CasualBrady @nickchk and more
emilyriederer.netlify.app/post/resource-…
2/3
emilyriederer.netlify.app/post/resource-…
2/3
Instead, I simply focus on the bare-bones frameworks. While econ and epi Twitter talk about CI nonstop, I'm struck by how underutilized some of the basics are in industry where we have rich high-dimensional panel data, well-defined but non-random treatment mechanism, etc

@TaschnerNatalia @cnpaiva @FelipeBGSilva @MBittencourtMD Olá,
este paper tem muitos problemas, que como disse, serve para exemplo de aula.
Para focar em 1 tema, que vai de encontro ao que a Natalia escreveu e outros acima, são os vieses. Vieses assim não podem ser corrigidos com ajuste. Se fosse assim, tudo estaria resolvido. 1/n
este paper tem muitos problemas, que como disse, serve para exemplo de aula.
Para focar em 1 tema, que vai de encontro ao que a Natalia escreveu e outros acima, são os vieses. Vieses assim não podem ser corrigidos com ajuste. Se fosse assim, tudo estaria resolvido. 1/n
@TaschnerNatalia @cnpaiva @FelipeBGSilva @MBittencourtMD Começa aqui, onde se cria um mecanismo perverso de viés de seleção. E isso criou essa disparidade entre os grupos que um mero ajuste multivariado não corrige. Também temos o immortal time bias, que é uma clássico erro. Esses são erros praticamente não passíveis de ajuste 2/n

@TaschnerNatalia @cnpaiva @FelipeBGSilva @MBittencourtMD Quanto a variáveis de confusão, isso já mudou muito na epidemiologia. E os erros vão desde a como lidar com variáveis contínuas e colocar variáveis pós exposição (collider-bias). Uma coisa simples que o Cox permite é time-dependent variable, por exemplo. 3/n
I’m so excited! Past couple years, I’ve wanted to sit down & structurally* deconstuct Roland Fryer’s 2019 paper on racial difs in police use of force to use as a teaching example** re: #colliderbias. Alas life got in the way...1/
HT @l_farland
*analyze “structure” in a #DAG
HT @l_farland
*analyze “structure” in a #DAG
#ColliderBias^ is rampant in US disparities research that uses admin data like hospital claims, police records. Almost all non-random samples will differentially select by race & other imp factors
^a selection bias with a particular structure in #causalinference #DAGs
2/
^a selection bias with a particular structure in #causalinference #DAGs
2/
Side note: Dr. Chanelle Howe (@BrownUniversity) and I explore a different type of selection bias in this @EpidemiologyLWW paper
ncbi.nlm.nih.gov/pmc/articles/P…
Structural selection bias* is EVERYwhere in health disparities, research, y’all! 3/
ncbi.nlm.nih.gov/pmc/articles/P…
Structural selection bias* is EVERYwhere in health disparities, research, y’all! 3/

Great discussion about propensity score trimming and how we need to carefully interpret results. Trimming can change who is in the population.
When thinking about #MachineLearning and #CausalInference need to consider what you will be training it against

1/ Super excited about our research on Medicare coverage delays among the uninsured and their effect on long-term PD use!
Published in the current issue of @MedicalCareLWW with @gchertow, Jay Bhattacharya, and Darius Lakdawalla. @SchaefferCenter
journals.lww.com/lww-medicalcar…
Published in the current issue of @MedicalCareLWW with @gchertow, Jay Bhattacharya, and Darius Lakdawalla. @SchaefferCenter
journals.lww.com/lww-medicalcar…
2/ We used a regression discontinuity design (a #causalinference method in observational studies to reduce selection bias) to identify the effect of this esoteric, but important, @CMSGov coverage policy
3/ The policy is strange and creates strange differences in the uninsured: most uninsured patients receive Medicare on day 1 of month 4 of dialysis (i.e., if you start dialysis June 1-30, you get Medicare Sept 1)

Ingredients for a successful approach in managing pandemic:
1. Value Field experience
2. Utilise knowledge and skills
3. Abundant Precautions in communication
4. Unbiased analysis
5. Use Common sense
#2019nCoV #leadership #coronavirusindia
1ofN
1. Value Field experience
2. Utilise knowledge and skills
3. Abundant Precautions in communication
4. Unbiased analysis
5. Use Common sense
#2019nCoV #leadership #coronavirusindia
1ofN
6. Ethics should be as integral as epidemiological principles in the strategy
7. Ensuring Equity is the goal, not an accessory. Think of vulnerable before thinking of self preservation
2ofN #COVID__19 #pandemic #MigrantWorkers
7. Ensuring Equity is the goal, not an accessory. Think of vulnerable before thinking of self preservation
2ofN #COVID__19 #pandemic #MigrantWorkers
8. Be open. Do not close doors to Ideas
People
Hypotheses
Alternatives
3ofN #2019nCoV #TheWHO #Asymptomatic
People
Hypotheses
Alternatives
3ofN #2019nCoV #TheWHO #Asymptomatic

I am excited to share my first working paper! @PHuenermund and I address why the interpretation of control variables in regression analysis should be avoided.
“On the Nuisance of Control variables in Regression Analysis”
arxiv.org/abs/2005.10314
#econometrics #causalinference /1
“On the Nuisance of Control variables in Regression Analysis”
arxiv.org/abs/2005.10314
#econometrics #causalinference /1

2/The interpretation of control variables is widespread within our research field. We checked the last five years of SMJ issues and found that 47% of papers that use parametric regression models with control variables also interpret or mention the results of their controls.
3/ We argue that this practice should be avoided because control variable estimates are unlikely to have causal interpretation themselves.
#Causalinference that talks the talk and walks the walk.
Claim: "Continuing #breastcancer screening past age 75 doesn't reduce 8-year breast cancer mortality."
Emulation of a #TargetTrial led by @xabieradrian with Medicare data
doi.org/10.7326/M18-11…
Let the discussion start.
Claim: "Continuing #breastcancer screening past age 75 doesn't reduce 8-year breast cancer mortality."
Emulation of a #TargetTrial led by @xabieradrian with Medicare data
doi.org/10.7326/M18-11…
Let the discussion start.

@xabieradrian @AnnalsofIM @HarvardEpi @harvard_data @HarvardBiostats @HarvardChanSPH @CMSGov @CMSgovPress @MonganInstitute @MassGeneralNews 2)
Because there's so much talk about #causalinference around here.
Computer scientists, economists, statisticians... talk a lot about the merits of #DeepLearning, instrumental variables, or whatever their preferred methodology is.
Everybody: This is your chance to shine.
Because there's so much talk about #causalinference around here.
Computer scientists, economists, statisticians... talk a lot about the merits of #DeepLearning, instrumental variables, or whatever their preferred methodology is.
Everybody: This is your chance to shine.

3)
No more toy examples. A real world question:
"At what age should #breastcancer screening stop?"
Need to compare the mortality of women under two dynamic screening strategies using a database of insurance claims with time-varying treatments and confounders.
How'd you do it?
No more toy examples. A real world question:
"At what age should #breastcancer screening stop?"
Need to compare the mortality of women under two dynamic screening strategies using a database of insurance claims with time-varying treatments and confounders.
How'd you do it?

Hype: "Give me data on millions on people and my algorithms will spit out gold."
Truth: Lots of data + sophisticated methods do not guarantee correct effect estimates.
Our empirical demonstration of the limits of observational data for #causalinference:
academic.oup.com/aje/article-ab…
Truth: Lots of data + sophisticated methods do not guarantee correct effect estimates.
Our empirical demonstration of the limits of observational data for #causalinference:
academic.oup.com/aje/article-ab…
<2% of deaths are from colorectal cancer. Even if screening prevented all colorectal cancer deaths (which is impossible), the effect wouldn't exceed 2%.
No matter what adjustment method @xabieradrian and us used, our effect estimate from a large claims database was always >5%.
No matter what adjustment method @xabieradrian and us used, our effect estimate from a large claims database was always >5%.

Please join us in publishing your failures. It is the best way to fight hype in #causalinference from complex longitudinal data.
Algorithms may help but, at the end of the day, either you do or don't have data on treatments, outcomes, and confounders. It is really that simple.
Algorithms may help but, at the end of the day, either you do or don't have data on treatments, outcomes, and confounders. It is really that simple.

Award-winning, free material on #causalinference – here’s an overview on the 2013-2018 winners of the „Causality in Statistics Education Award“, awarded by .@AmstatNews, and initiated by .@yudapearl
In 2018, the award went to Jonas Peters, Dominik Janzing, and @bschoelkopf for their open-access textbook “Elements of Causal Inference”. This is the best textbook on the connection between machine learning and causal inference. It’s almost self-contained.
I think it is very useful for students in ML, stats, and physics, and is certainly very interesting for social scientists, because it views familiar topics from a different angle. mitpress.mit.edu/books/elements…
